













作者:Abhimanyu Dubey
翻译:吴蕾、霍静、任杰
当人们问我是做什么工作的时候,我总是非常困惑如何回答才好。“人工智能”这个答复吧,我觉得太宽泛了,而“图像识别”似乎又太专业了。不过呢,还是下面这个问题令我真正抓狂:
人工智能会掌控整个地球吗?
对于一名从事于机器智能研究的专业人士来说,这个问题太让我恼火了。我也不想去抱怨怀疑论者,事实上大部分人都觉得人工智能是一种神秘,而且有着无穷无尽阴谋诡计的玩意儿,最终它们会把人类灭绝,因为,它能够在我们狂看一晚Evan Goldberg编导的电影之后,就预测到下一部我们将观看的影片将会是《Sausage Party》(《香肠派对》)。
“然而,大多数人并没有意识到,无论我们认为自己多么有个性,多么特殊,从普遍意义上来看,人们还是遵循一些普遍行为模式的。只要经过足够多训练,计算机就可以轻松识别出人们的行为模式。”
因此,机器能推测你喜欢的音乐,或者给你一些手机APP应用的建议,这对机器来说很容易实现。不过,这并不代表所有的预测工作的难度和性质类似,我只是希望大家能理解,这相对于人类的能力来说是一种延伸和拓展。
要想了解时下人工智能领域中哪些技术很厉害,重点在于懂得机器学习做得不错的两个主要场景:
- 受控环境
- 监督
我们看到了Google的人工围棋选手AlphaGo打败了人类最厉害的围棋选手,计算机象棋的问题很早以前就已经解决了,而最近又有很多论文在探讨Doom游戏比赛中击败人类的话题。事实上,在游戏里面,你能够完全掌控操作环境、能够实施的行为以及可能产生的结果,这使得建模变得相当容易。而一旦我们能够将游戏环境进行建模,下一步任务就是模拟和学习。实际上,这些理论早就已经成熟了,正是近年来计算机硬件的发展使大规模机器学习得以实现,才能够令AlphaGo这类技术在实现层面上获得重大突破。
监督式受控环境表示对于每一个行为,你能够估计出可能受到的惩罚,从而能够有效地从错误中积累经验,而游戏正是这种监督式受控环境的完美表达。还有一个例子就是我们刚才提到的电影预测,可以理解为有一个很大的样本,里面存在“用户”和“影片”两类数据,还有一个给定的用户选择模型。通过这些,我们就能进行下一次看什么电影的预测。
在监督式受控环境中,我们知道会得到何种信息,并能够对类似的信息加以处理。我们可以对这类目标创建“表达法”(representation),在我们需要进行预测的时候,这些“表达法”能够帮助我们最终确定准确的计算模型。这是通用学习类型中的一个非常狭窄的子类,也是和我们人类差不多的一类智能方式。

图注:分类器概观
然而,大部分的人类行为并非监督式的,而是在与环境交互的基础上建立的逻辑和直觉。人类的基本活动,比如说识别物体,理解物理过程都是时常发生的事情。通常,我们通过与事物的互动能习得很多的新知。
在当前阶段,这对于计算机来说还是很难达到的水平。现在如果你要一台机器能认识所有你给的图片里面的汽车,你必须告诉机器先去看那些图片,还得告诉它你的汽车是什么样子的。当你给机器看了大量汽车图片时,它就能认出汽车了。这就是监督式学习,在它尚未理解看什么东西的时候,你得教它汽车是什么样子的。
现在,计算机科学家在努力使这种学习变成几乎无需监督的,即非监督式学习。最终,我们希望机器能够理解物体和景象的概念本身,而不需要特地去调教它。
当前大多数研究的重心在于非监督式学习,解决这个问题更加困难。诚然,我们的机器看上去更聪明了,不过大多数都是在监督式受控环境中的情况。首先我们必须能令机器人在非监督的环境下正常工作,然后再考虑系统在非受控的情形下运行,这样才更为接近人类的智能。
“尽管,现在探讨机器灭绝人类,或者是机器人的‘不良企图’仍为时尚早。然而,人工智能更严峻的威胁正悄然逼近,这可能造成极其严重的后果”。

早先通过观察特定的特性的算法称为决策树分割数据
在这个会议的最初讨论时,我导师曾提到了一个问题,令我第一次真正质疑人工智能的可用性。早期传统的人工智能技术的算法很容易理解,比如说,我们要造一个机器来测量人的身高和体重,并告诉他们是不是超重了。这个很简单,我们只需要计算出这个人的体重指数(Body Mass Index, BMI),如果超过了特定阈限,那就是超重。这是人工智能的原型算法。如果我说某人肥胖,这是必须要有合理的判断的(而不是熊孩子骂人),这个人的BMI确实是落在超重人群的平均BMI范围里。
现在大多数的机器已经不是这么简单了,它们采用大量复杂的数据作为输入(比如高清晰度的图片),经过非常精细粒度的算法来完成输出。这样的话,简单的阈限或决策树的方法就不够用了。渐渐地,系统采用了一套广为人知的深度学习算法,去识别和学习大量数据,用类似于人类的方式去细化模板。

图注:典型的深度学习模型。它包含了若干个互相连通传播信息的神经元(圆圈),这与已发现的人脑运作模式十分相似
这些系统性能非常好,但是学习过程很慢,因为需要很多数据来学习。
“但是,有个问题:一旦它们给了我们结果,不管正确与否,我们并不知道机器是怎么得到这个结果的。”
这个听起来并不是那么要紧—在开始的时候,在机器学习系统里面,我们有两种类型的数据—特征和标签。特征是观察到的变量,标签是我们需要预测的。举个例子,在之前的肥胖症检测器中,我们的特征是人的身高和体重,标签是每个人的超重或者健康指标。为了从图片中检测癌症细胞,特征是若干张器官的图像,标签是图片有没有癌症细胞。

癌症检测算法会先扫描这组图片
机器学习算法一般会这样解决问题,先给每个特征配置权重,相加,最后基于所得的和来做决定。比如,如果你要预测一个苹果是不是坏了,你会先看苹果的气味、颜色,如果触摸一下那么就还有它的质感,最后大脑会配置给这些特征不同的权重。
假如苹果烂了,光凭颜色一个特征就可以解决问题了
计算机遵循类似的想法,只不过权重是通过不同的优化算法算出来的。但是,在深度学习中,我们并不确定我们想用哪些具体的特征,更不用说配置权重。所以我们怎么办?我们让计算机自己学习选出最好的特征群,把它们用最佳方式组合来做决定,从某种意义上模拟人类大脑的做法。
这个主意给我们带来惊人的结果—在计算机视觉领域(这个领域研究如何让计算机理解图像数据),尤其是随着高效GPU和新框架的出现,使学习基本的图像级别的概念变得小菜一碟。但是,要注意的是—我们讨论的这些机器通过学习选出的特征,物理意义并不像传统方法那么直观。
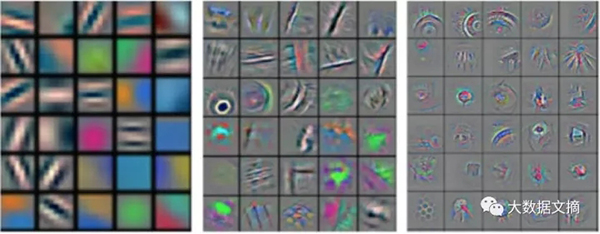
这些例子展示了计算机从图片中寻找的东西—看上去它们在检测形状,但是对于非图像数据,并不是这么直观。
大部分人不觉得这是个问题—从技术角度在现阶段这并不是一个大问题,因为现在人工智能解决的任务都是具体的,比如从图片中辨认人物和物体、脸部追踪以及合成声音信号。我们大致知道算法在学习什么样的物体(事实上,这个展示是这个方面的一个最近的发展)。但是,当我们使用深度学习来处理那些有更多风险的预测的时候,每个预测都需要合情合理,可以解释。
设想你是一家银行,你有所有客户详细的交易信息和信用历史。你使用一个复杂的深度学习算法来找出拖欠贷款者。既然你已经有了一个大型数据库囊括用户的各类行为模式信息,算法解决这个问题可能会给出很高的准确率,但是,一旦你怀疑未来的拖欠者,你并不确切的知道到底是什么引起了怀疑,对于预测的解释变得非常困难。
大部分的深度学习系统没有好的技术去理解它们的决策能力,这个也是研究的热点。对于某些与特定任务相关的深度网络,尤其在计算机视觉,我们在理解这些系统上已经有了很大的进步—对其较好的定位,理解是什么激发产生了一种算法以及算法是否确实(按照我们的理解)这么做了。但是总的来说,还是有很大的空间需要提高。
机器学习有个很严重的缺陷—为了把信号和噪声分开,需要很多人工处理。或者用专业的话说,过拟合。我说这个专业词的意思是,当一个模型要拟合一个特定的数据集,用以预测新的未知的数据,它可能对于已知数据拟合的过于完美。所以导致的结果是,当应用于现实世界的时候,它就不会那么准确。
具体来讲,模型不是学习在这个世界中确实存在的模式,而是学习已经采集数据集的模式。有几种方式可以理解过拟合,对于感兴趣的人现实中有很多的关于过拟合的例子。一个简单的例子就是在你居住的地方是夏天,所以你把自己的行李箱装满了夏天的衣服,结果在阿姆斯特丹只有11度,你在那里只能冷的瑟瑟发抖。

该图反映了过拟合的情况,即,最后一幅图显然对噪音也进行了拟合
关注过拟合问题的原因是想强调一下机器学习的可解释性的重要性。如果我们不能理解这些机器学习算法到底学习的是什么,我们并不能判断它们是不是过拟合了。举个例子说,某机器算法是根据上网浏览历史来预测可疑的上网行为。因为使用的大部分的训练数据是来自美国的19岁少年,那么用于预测美国的19岁少年以外的任何个体就会是有偏的,尽管他们的搜索历史都有PewDiePie (专注恐怖与动作游戏)的视频。
这个问题的反响会随着深度学习在推断任务中的应用增加而迅速加大。比如,我们看到很多研究关于医疗图像预测 – 这个应用需要更多的可解释性和可理解性。除此之外,假如预测任务的批量太大不可能去人工检查预测结果,我们就需要系统来帮我们理解和调整机器学习到底做了什么。
这个威胁刚刚出现,但是这个方面的研究需要更多的时间,来找到更好的解决办法。但是,我们必须意识到模型可解释性的重要性,尤其当我们建立模型是为了让生活变得更好。
我想用一个例子来结尾:如果一个人撞车了,我们可以找出原因,来理解事故是怎么发生的 – 也许司机喝醉了,也许路人正边端着热饮边发短信呢。
但是如果无人驾驶车撞到另外一辆车,致一名乘客死亡,我们去找谁呢?原因又是什么呢?你怎么保证它不会再发生呢?
这些事故最近发生过几次,随着更多的人工智能系统的出现,会有更多的失误发生。为了更好的改正,我们需要理解到底哪里出了问题:这是今天人工智能要面临的主要挑战之一。
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】






















