关于Oracle和MySQL的高可用方案,其实一直想要总结了,今天分为几个系列简单说说。通过这样的对比,会对两种数据库架构设计上的细节差异有一个基本的认识。
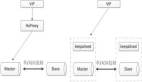
高可用方案概览
Oracle有一套很成熟的高可用解决方案MAA。用我在OOW上的ppt来看,这个方案自9i开始,到今年已经有16个年头了。

当然,MAA方案虽好,成本还是有的、复杂度还是有的,所以放眼国内的使用情况,RAC不一定是100%有,电信、证券、寿险、银行如果用,基本都是全套方案,有些相对保守,RAC也有使用active-passive模式的,互联网行业如果用,清一色都是单实例和DG结合。
而MySQL因为开源的特点,官方和社区里推出了很更多的解决方案,高可用情况大体如下,仅供参考(数据引用自Percona)。
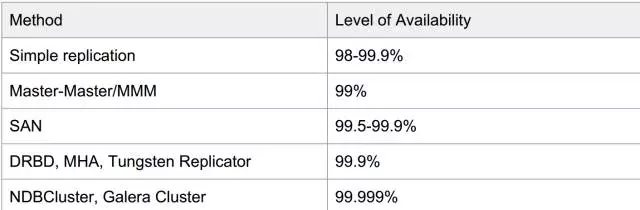
因为时间的原因,MGR刚推出不久,还在观察期。MGR固然不错,MySQL Cluster方案也有PXC、Galera等方案,个人还是更倾向于MHA。
基本情况说完了,接下来分为几个部分来解读。
Oracle RAC和MySQL MHA
先拿RAC和MHA来做一个基本的对比。
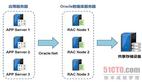
Oracle的解决方案在阿里快速发展时期支撑起了核心业务的需求。大概是这样的架构体系,看起来很庞大。里面的RAC算是一个贵族,用昂贵的商业存储,网络带宽要求极高,前端大量的小机业务还有不菲的license费用。非常典型的IOE的经典架构。

如果要考虑异地容灾,那么资源配置要double,预算翻番。
MySQL的架构方案相对来说更加平民化,普通的PC就可以,但数量级要高,做业务拆分、水平拆分就能够横向扩展出非常多的节点,很多大互联网公司的MySQL集群规模都是几百几百的规模,上千都不稀奇。如此之多的服务资源,发生故障的概率还是有的,保证业务服务的可持续性访问是技术方案的关键。如果按照MHA的架构,基本上就是MHA Manager节点来负责整个集群的状态,好比一个居委会大妈,对住户的大大小小的事情都了如指掌包打听。
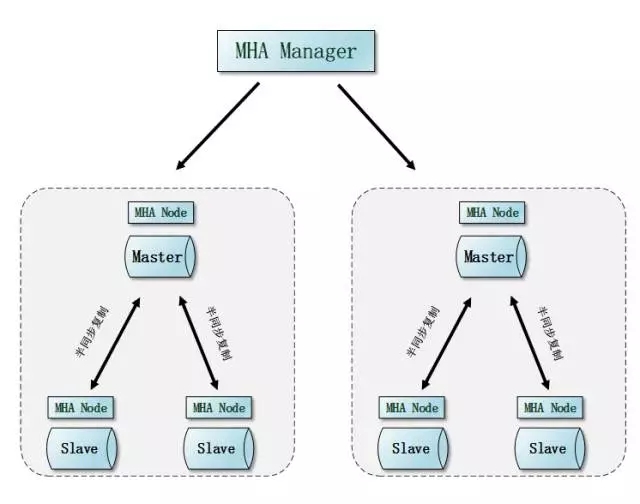
当然上面的架构图过于笼统,在MHA的高版本里面还使用了binlogServer,我们从一些细节入手。比如先来说说网络的事情。
Oracle对于网络的要求还是很严格的,一般都是要2块物理网卡,每台服务器需要至少3个IP:Public IP、private IP、VIP,除了共享存储,至少需要2个计算节点。
private IP是节点间互信的,Public IP和VIP在一个网段,简单来说,VIP是对外的,是public IP所在网络的漂移IP,在10g里面都是通过VIP来做负载均衡的,11g开始有了scan-IP,原来的VIP还是保留,所以Oracle里面的网络配置要求还是很高的。抛开共享存储,搭建的核心就是网络配置了,网络通则通。
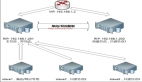
scan-IP还可以继续扩展,最多支持3个scan-ip,如下图所示:[[208772]]
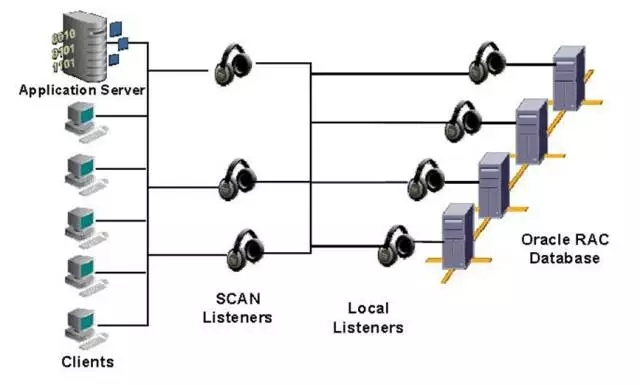
当然网络层面不只是这些,我们还有必要了解下TAF(Transparent Application Failover)。TAF是Oracle中对应用透明的故障转移,在RAC环境中使用尤其广泛。在RAC中Load Balance这块确实做了很大的改进,从10g版本开始的多个VIP地址的Load Balance,到11g版本中的SCAN,做了很大的简化。
而在Failover的实现中,还是有一定的使用限定,比如11g中默认的SCAN-IP的实现其实默认没有Failover的选项,如果两个节点中的其中一个节点挂了,那么原有的连接中继续查询就会提示session已经断开,需要重新连接。客户端TAF主要会讨论Failover Method和Failover Type的一些简单内容。
(1)Failover Method
Failover Method的主要思路就是换取故障转移时间,或者换取资源来实现。
可以这样来理解,假设我们存在两个节点,如果某个session连接到了节点2,然而节点2突然挂了,为了更快处理Failover这种情况,Failover Method有preconnect和basic两种。
- preconnect这种预连接方式还是会占用较多的资源使用,在各个节点上会预先占用一部分额外的资源,在切换时会相对更加平滑,速度更快。
- basic这种方式,则在发生Failover时,再去切换对应的资源,中间会有一些卡顿,但是对于资源的消耗相对来说要小很多。
简单来说,basic方式会在故障发生时才去判断,而preconnect则是未雨绸缪;从实际的应用来说,basic这种方式更加通用,也是默认的故障转移方式。
(2)Failover Type
Failover Type实现更加丰富而且灵活,非常强大。这时控制粒度可以针对用户SQL的执行情况进行控制,有select和session两种;通过一个小例子说明一下。
比如,我们有个很大的查询在节点2上进行,结果节点2突然宕机了,对于正在执行的查询,比如说有10 000条数据,结果刚好故障发生的时候查出了8 000条,那么剩下的2 000该怎么处理。
第一种方式就是使用select;即会完成故障切换,继续把剩下的2 000条记录返回,当然中间会有一些上下文环境的切换,对于用户是透明的。
第二种方式是session;即直接断开连接,要求重新查询。
在10g版本中借助于VIP的配置达到Load Balance+Failover的配置如下:
racdb=
(DESCRIPTION =
(ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.101)(PORT= 1521))
(ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.201)(PORT= 1521))
(LOAD_BALANCE = yes)
(FAILOVER = ON)
(CONNECT_DATA =
(SERVER= DEDICATED)
(SERVICE_NAME = racdb)
(FAILOVER_MODE =
(TYPE= SELECT)
(METHOD= BASIC)
(RETRIES = 30)
(DELAY = 5))))如果11g的SCAN-IP也想进一步扩展Failover,同样也需要设置failover_mode和对应的类型。
RACDB =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = rac-scan)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = RACDB)
)
)从这个角度来看,Oracle的方案真是精细。
再来看看MySQL的方案。
分布式的方案,让MySQL看起来像一把瑞士军刀,对于网络层面的要求,几乎可以说MySQL没有什么要求,申请一主一从的架构,那么就只需要4个IP即可(主、从、VIP、MHA_Manager(考虑一个manager节点)),一主两从是5个。
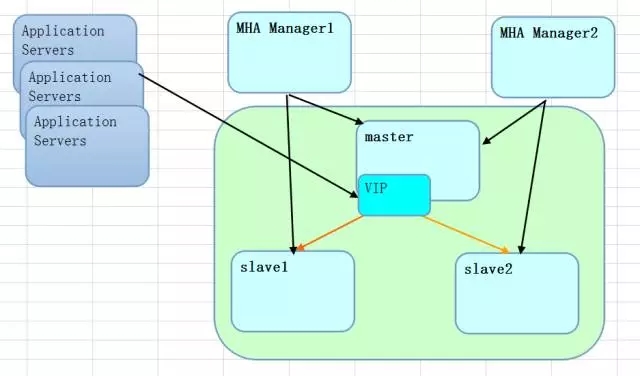
这一点上,MySQL原生并不支持所谓的负载均衡(这里说的不是读写分离),可以通过前端的业务来分流,比如使用中间件proxy,或者持续的拆分,达到一定的粒度后,通过架构设计的方式来满足需求。因为基于逻辑的复制,很容易扩展,一主多从都是很常见的,代价也不高,延迟不能说没有,只是很低,能够适应绝大部分的互联网业务需求。
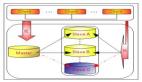
而说到触发MHA切换的条件,从网络层面来看,如下的红点都是潜在的隐患,有的是网络的中断,有的是网络的延迟,发生故障时,保数据还是保性能稳定,都可以基于自己的需求来定制。从这一点上来说,丢失数据的概率是有的。绝对不是强一致性的无损复制。
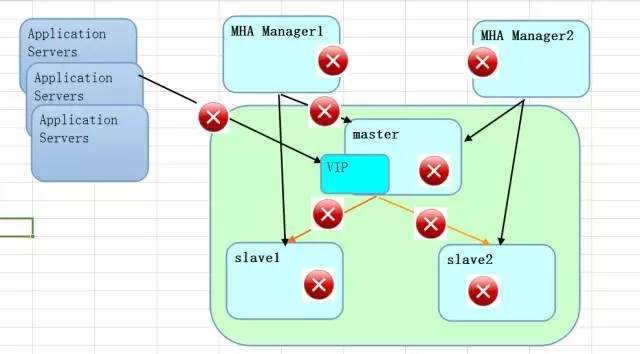
把上面的图放大,其实会有更多的细节,比如ssh的连接检测和数据库的心跳检测(insert_ping),在整个方案里面要考虑的场景就很多了。对于网络的切换,目前MHA做的主要是保证数据复制关系,如果要深入使用,还是要做更多的定制,比如结合Proxy的方案,使用ZooKeeper的状态检测,使用keepalive或者VIP的网络层面的切换等。
整体来看两种方案,RAC是集中共享,除了存储层面的共享外,网络层面的组播其实也会提高节点间通信的成本,所以RAC对于网络的需求很大,如果存在延迟是很危险的,发生了脑裂就很尴尬了。MySQL MHA的方案是分布式的。支持大批量的环境,节点间通信的成本相对来说要低很多。但是从数据架构的角度来说,因为是复制的数据分布方式,所以对于存储尽管不是共享存储,对于存储的成本还是高于RAC(不是说存储的价格,是存储的数据量大小)。
Oracle Data Guard和MySQL灾备
然后我们来继续说说灾备的部分。我就拿Oracle的DG和MySQL的方案对比。
在灾备的概念中,Oracle DBA习惯叫做主备,即为Primary、Standby,而MySQL更喜欢叫做主从,即为Master、Slave,无论怎么叫,说得都是同一个意思。
首先在Oracle中,数据是基于物理复制(此处说的都是physical standby),所以对于数据库的状态和角色就很好定位,从库正常状况下是无法读写的。所以在Oracle中角色转换的概念就很清晰,failover和switchover,failover就是故障转义,switchover就是主备切换。在MySQL中failover的概念很好理解,但是switchover相比来说,就会淡化很多。
Oracle因为是基于物理复制,所以一直以来备库要么就是恢复状态(recover),要么就是只读不应用状态(read_only),直到11g这个问题才解决,就是大名鼎鼎的ADG(read only with apply)。而在MySQL里面这都不是事儿,备库可以灵活的开关read_only的参数,当然一般是不希望备库写入的,读绝对不是问题,而且还可以扩展着读,做读写分离。
对于Oracle的备库的理解,我认为除了ADG之外,最有亮点的就是闪回数据库了,可能很多Oracle DBA都对于闪回数据库敬而远之,技术的更新很多,好端端的特性放着不用太可惜了,比如搭建DG,分分钟DG Broker搞定,使用手工方式不见得有多高效。
闪回的概念在MySQL里面也有,目前来说,可以根据binlog抽取的数据做到DML的闪回,和Oracle里面的闪回差距还很大。Oracle里面的闪回五花八门,零零总总算下,差不多就有这些。

当然常用、实用的不见得这么多,MySQL的DML还算是原生态,可以根据binlog抽取来恢复,或根据第三方工具辅助,但DDL就是难上加难了,目前MariaDB的DDL闪回就是一个突破,从我的理解来说,应该能够实现一部分的闪回功能,具体的效果我后面测试一下。
所以说闪回是个大宝藏,到底有多好呢,Oracle的备库方案有了快照数据库,就是物理备库可以临时写入,带来的优点就是主库的碎片,在备库是完全一样的。所以在SQL审核方面有着得天独厚的优势,我在线上的很多DDL审核中都做过测试和实际应用,效果很赞,而且11g中的闪回可以在线开在线关,所以一般10g里面我建议要慎重使用,11g有条件下备库端还是推荐的,满足需求就行。当然闪回数据库不是万金油,有个别场景是不支持的,在此就不展开了。
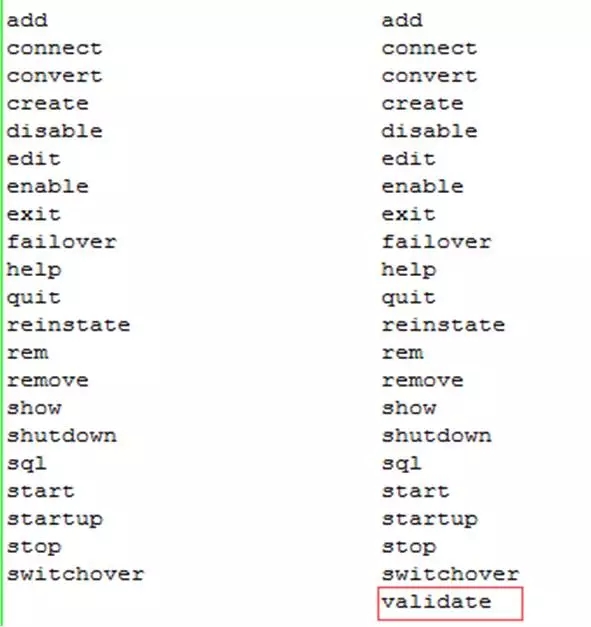
对于灾备来说,数据库的切换是未雨绸缪的事情,那么到底备库切换的检查是否OK呢,Oracle里面有了DG Broker这么一个神器,还在新版本中做了很多不错的选项,比如新版本中有了validate的选项,可以检测主备切换的条件是否满足。下面是DG Broker的命令中多出来的validate命令,效果还是不错的。
此外,从高可用的角度来说,如果在备库存在连接,做switchover时,会话会持续保持,当然会有短暂的卡顿。这也就是特色的会话保持特性。
Preserving Active Data Guard Application Connections
当然在MySQL里面就不可理解了,切换别说会话保持,卡顿的影响都微乎其微。因为Oracle基于物理复制的方式,物理一致性使得复制扩展性很难,当然也不是说完全不能实现,比如cascade standby,可以级联复制,到了12c改进一版,就是Far Sync,号称是零数据丢失,对于跨区域的数据中心来说,会把延迟降到最低。
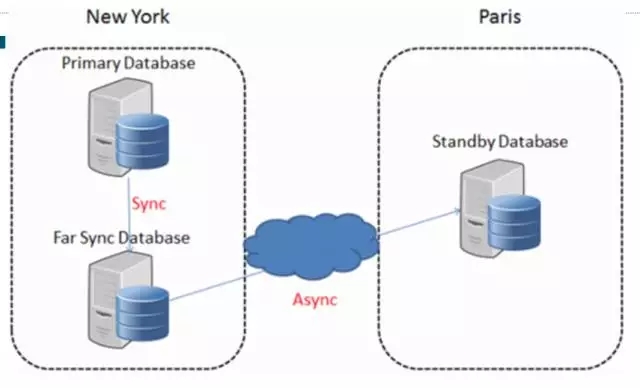
如果从技术架构的角度来看,部署的分布图类似下面的形式,中间有远距离的数据传输,可以通过中间的节点来转换,中间这个节点很特别,是不存数据的,只是保持一个内存结构,同步数据。

还有就是延迟,我测试过DG的延迟,和MySQL在基本相似的压力情况下,Oracle基本上控制在0.1秒左右,MySQL的复制就会有一些延迟的放大。
所以总体看下来,Oracle的方案是一种很专业的解决方案,工具全,架构相对复杂,数据同步是强一致性。所以在涉及交易的业务中对它更加偏爱。
再来看看MySQL方向的改进。我们不比单机性能和延迟了,因为这个确实是有差距,而且硬拼也没有太大的意义,我们从整体架构角度来考虑,这些又是Oracle难以实现的地方。
首先说下主从复制,MySQL是典型的逻辑复制,主库端可以承载大批量的并发,但是性能瓶颈很明显,主库的并发最后落到文件上还是串行的,抛开日志传输进程的开销,最大的瓶颈就在于SQL_Thread的应用延迟。就好比中午大家出去吃饭,前台可以并发点很多的菜品,但后台的厨师就好比是SQL_Thread,他得一道菜一道菜做啊。怎么能做得更快呢?比如你叫了5分盖饭,他可以一次性炒出来,这样就能够大大提高效率,所以前台的小姑娘也会建议你和其他人点一样的菜,原因就一个字——快。这用在并行复制上就是类似的道理。MySQL 5.6没法做到细粒度的并行复制,只能在库级别,而在MySQL 5.7中可以做到表级别更细粒度的,这个改进就很明显了。
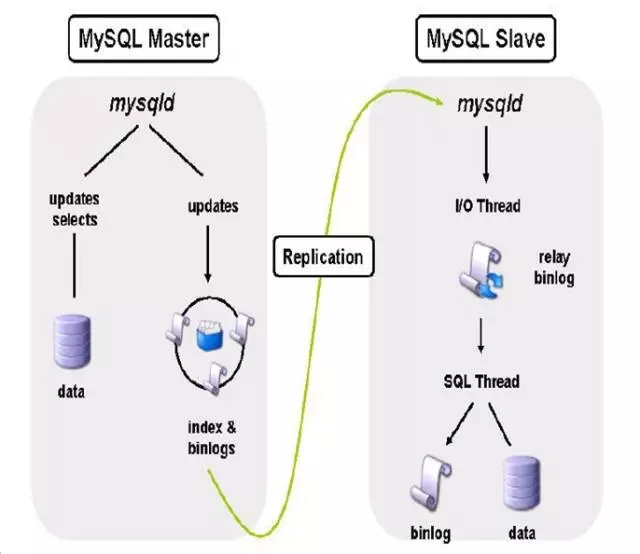
所以延迟的问题能够解决,后续的扩展就容易多了,MySQL的扩展甚至可以做到指数级的扩展方式,如果允许一些低延时,大量的读请求就可以逐步分解。所以一主多从的架构方式也是见怪不怪。
值得一提的是MHA的一主多从架构中,如果多个从库存在延迟,在切换的时候MHA会补齐差异的日志,这是MHA的一大亮点。
而MySQL的级联复制就更纯粹了,和Oracle相比的最大优势就是一个数据库可以既是主库也可以同时是从库,起到承上启下的作用。
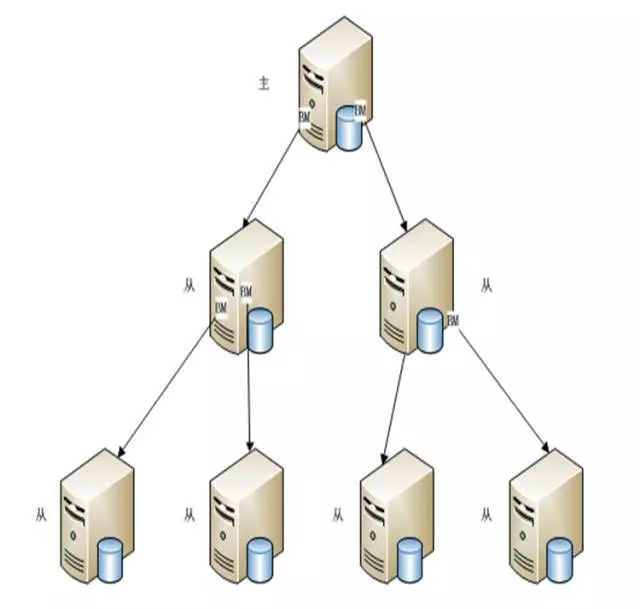
这种扩展方式简直是酸爽,在一些跨数据中心的场景,允许一定延迟的情况下还是有用武之地。比如你需要从北美读数据,可以从北美推送数据库到香港或者新加坡,再推送到北京。有了这种方式就很容易扩展。当然在实时交易中还是存在一些瓶颈和缺陷。
展望和后续补充
如果抛开具体的数据库,整体来说数据量和业务量到达一定程度都会碰到一系列的问题。这些都是痛点也是难点,常见的问题如下:
- 单台服务器无法承载已有的压力
- 数据库单表容量越来越大
- 大量的读写需求无法平衡
- 资源如果扩容,应用改动较大
- 资源的负载没法拆分,或者不易拆分
这时就需要扩展,就需要匹配的解决方案,比如中间件的方案,有的解决了一些通用的问题,有些侧重于某一方面。比如需要考虑sharding来分片,读写分离来做分担读写压力,前端海量访问可以通过大量的水平扩展来分担。
从这个角度来说,MySQL是以架构和规模取胜,通过业务拆分和架构拆分能够实现线性扩展。而Oracle的扩展性虽然没有那么好,但从架构和业务层面来说也能做,这个后续有机会再细细说一说,可以拟一篇分布式方面的文章。
小结
简单总结一下,高可用的方案选择很多,各家有各家的需求,能定制的定制,能开源的开源。大道至简,只要满足了需求,系统稳定不背锅,那就是最好的方案。