摘要:近期神经机器翻译(NMT)在标准基准上取得了很大成功,但是缺乏大型平行语料库对很多语言对是非常大的问题。有几个建议可以缓解该问题,比如三角剖分(triangulation)和半监督学习技术,但它们仍然需要强大的跨语言信号(cross-lingual signal)。本论文中,我们完全未使用平行数据,提出了用完全无监督的方式训练 NMT 系统的新方法,该方法只需使用单语语料库。我们的模型在近期关于无监督嵌入映射的研究基础上构建,包含经过少许修改的注意力编码器-解码器模型(attentional encoder-decoder model),该模型使用去噪和回译(backtranslation)结合的方式在单语语料库上进行训练。尽管该方法很简单,但我们的系统在 WMT 2014 法语-英语和德语-英语翻译中分别取得了 15.56 和 10.21 的 BLEU 得分。该模型还可以使用小型平行语料库,使用 10 万平行句对时,该模型分别取得了 21.81 和 15.24 的 BLEU 得分。我们的方法在无监督 NMT 方面是一个突破,为未来的研究带来了新的机会。
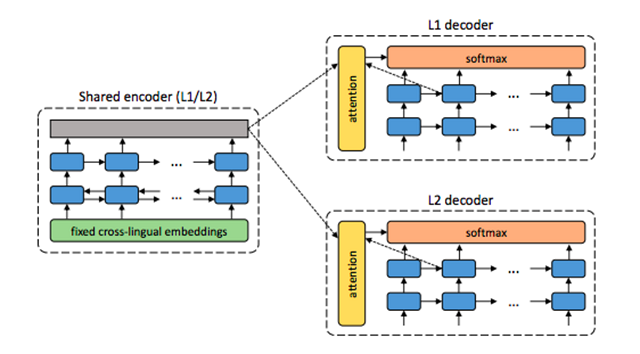
图 1:系统架构。
对语言 L1 中的每个句子,该系统都通过两个步骤进行训练:去噪——利用共享编码器优化对句子带噪声版本进行编码和使用 L1 解码器重构句子的概率;回译——在推断模式(inference mode)下翻译该句子(使用共享编码器编码该句子,使用 L2 解码器进行解码),然后利用共享编码器优化对译文句子进行编码和使用 L1 解码器恢复源句子的概率。交替执行这两个步骤对 L1 和 L2 进行训练,对 L2 的训练步骤和 L1 类似。
系统架构
如图 1 所示,我们提出的系统使用比较标准的带有注意力机制的编码器-解码器架构(Bahdanau et al., 2014)。具体来说,我们在编码器中使用一个双层双向 RNN,在解码器中使用另一个双层 RNN。所有 RNN 使用带有 600 个隐藏单元的 GRU 单元(Cho et al., 2014),嵌入的维度设置为 300。关于注意力机制,我们使用 Luong et al. (2015b) 提出的全局注意力方法,该方法具备常规对齐功能。但是,我们的系统与标准 NMT 在三个方面存在差异,而正是这些差异使得我们的系统能够用无监督的方式进行训练:
1. 二元结构(Dual structure)。NMT 系统通常为特定的翻译方向搭建(如法语到英语或英语到法语),而我们利用机器翻译的二元本质(He et al., 2016; Firat et al., 2016a),同时进行双向翻译(如法语 ↔ 英语)。
2. 共享编码器。我们的系统仅使用一个编码器,该编码器由两种语言共享。例如,法语和英语使用同一个编码器。这一通用编码器旨在产生输入文本的语言独立表征,然后每个解码器将其转换成对应的语言。
3. 编码器中的固定嵌入。大多数 NMT 系统对嵌入进行随机初始化,然后在训练过程中对其进行更新,而我们在编码器中使用预训练的跨语言嵌入,这些嵌入在训练过程中保持不变。通过这种方式,编码器获得语言独立的词级表征(word-level representation),编码器只需学习如何合成词级表征来构建较大的词组表征。如 Section 2.1 中所述,存在多种无监督方法利用平行语料库来训练跨语言嵌入,这在我们的场景中也是可行的。注意:即使嵌入是跨语言的,我们仍然需要使用每种语言各自的词汇。这样,同时存在于英语和法语中的单词 chair(法语意思是「肌肉」)在每种语言中都会获得一个不同的向量,尽管两个向量存在于共同的空间中。
无监督训练
NMT 系统通常用平行语料库进行训练,由于我们只有单语语料库,因此此类监督式训练方法在我们的场景中行不通。但是,有了上文提到的架构,我们能够使用以下两种策略用无监督的方式训练整个系统:
1. 去噪
我们使用共享编码器,利用机器翻译的二元结构,因此本文提出的系统可以直接训练来重构输入。具体来说,整个系统可以进行优化,以使用共享编码器对给定语言的输入句子进行编码,然后使用该语言的解码器重构源句子。鉴于我们在共享编码器中使用了预训练的跨语言嵌入,该编码器学习将两种语言的嵌入合称为语言独立的表征,每个解码器应该学习将这类表征分解成对应的语言。在推断阶段,我们仅用目标语言的解码器替代源语言的解码器,这样系统就可以利用编码器生成的语言独立表征生成输入文本的译文。
但是,相应的训练过程本质上是一个琐碎的复制任务,这使得上述完美行为大打折扣。该任务的最佳解决方案不需要捕捉语言的内部结构,尽管会有很多退化解只会盲目地复制输入序列的所有元素。如果确实如此的话,该系统的最好情况也不过是在推断阶段进行逐词替换。
为了避免出现此类退化解,使编码器真正学会将输入词语合成为语言独立的表征,我们提出在输入句子中引入随机噪声。这个想法旨在利用去噪自编码器(denoising autoencoder)同样的基本原则(Vincent et al., 2010),即系统被训练用于重构带噪声输入句子的原始版本(Hill et al., 2017)。为此,我们通过随机互换相邻词语来改变输入句子的词序。具体而言,对于包含 N 个元素的序列,我们进行 N/2 次此类随机互换操作。这样,该系统需要学习该语言的内部结构以恢复正确的词序。同时,我们不鼓励系统过度依赖输入句子的词序,这样我们可以更好地证明跨语言的实际词序离散。
2. 回译
尽管存在去噪策略,上述训练步骤仍然是一个复制任务,其中包含一些合成的改动,最重要的是,每次改动都只涉及一种语言,而非同时考虑翻译的两种语言。为了在真正的翻译环境中训练新系统,而不违反仅使用单语语料库的限制,研究人员提出引入 Sennrich 等人 2016 年提出的回译方法。具体说来,这种方法是针对给定语言的一个输入句,系统使用贪心解码在推断模式下将其翻译成另一种语言(即利用共享编码器和另一种语言的解码器)。利用这种方法,研究人员得到了一个伪平行语料库,然后训练该系统根据译文来预测原文。

表 1:几种系统在 newstest2014 上的 BLEU 得分。无监督系统利用 News Crawl 单语语料库进行训练,半监督系统利用 News Crawl 单语语料库和来自 News Commentary 平行语料库的 10 万句对进行训练,监督学习系统(作为对比)使用来自 WMT 2014 的平行语料库进行训练。其中,Wu et al. 2016 年提出的 GNMT 取得了单模型的最佳 BLEU 得分。
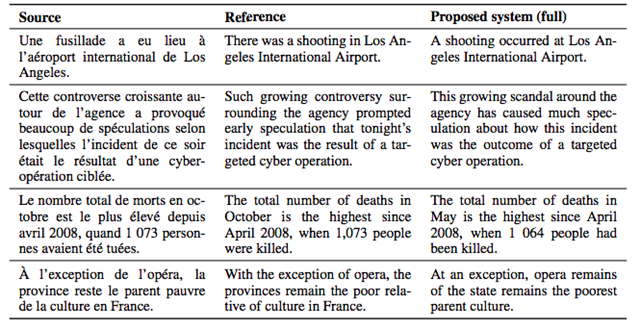
表 2:本文提出的系统使用 BPE 对 newstest2014 中的部分句子进行法语到英语的翻译。
结论
在本论文中,研究人员提出用无监督方法训练神经机器翻译系统的新方法。它建立在无监督跨语言嵌入的现有工作上(Artetxe 等人,2017;Zhang 等人,2017),并将它们纳入修改后的注意力编码器-解码器模型中。通过使用带有固定跨语言嵌入的共享编码器,结合去噪和回译,我们实现了仅利用单语语料库训练 NMT 系统。
实验显示了新方法的有效性,在标准 WMT 2014 法语-英语和德语-英语基准测试中,新方法的 BLEU 得分显著超过执行逐词替换的基线系统。我们也手动分析并确定了新系统的表现,结果表明它可以建模复杂的跨语言关系并生成高质量的译文。此外,实验还表明新方法结合一个小型平行语料库可以进一步提升系统性能,这对于训练数据不足的情况非常有用。
新的工作也为未来研究带来了新的机会,尽管该研究在无监督 NMT 方面是一个突破,但仍有很大改进空间。其中,在研究中用于比较的监督 NMT 系统不是业内最佳,这意味着新方法带来的修正同样也限制了其性能。因此,研究人员接下来将检查这一线性的原因并尝试缓解。直接解决它们不太可行,我们希望探索两个步骤,时序 i 安按照当前方式训练系统,然后恢复主要的架构变更,再进行精确调整。另外,研究人员还将探索将字符级信息纳入模型,这可能会有助于解决训练过程中出现的一些充分性问题。同时,如果解决了罕见词,特别是命名实体的问题,该系统的表现将进一步提升。