MySQL高可用方案中MHA绝地是一个相当成熟的实现。对于数据的切换,其实MGR也能很好的完成,也就是说,数据层面的角色切换已经刻意很平滑的做好了,但是对于访问IP的处理,还是有很大的空间,MHA提供了很多可选的空间来支持。
常见的组合方式有:
- MHA+VIP
- MHA+keepalive
- MHA+Zookeeper
当然MHA+VIP是一种很成熟和经典的方案了。
一般来说都有以下类似的架构方式,假设架构模式为一主两从。对于应用访问来说,提供的IP信息就依据绑定的VIP地址为准。VIP可以根据节点的数据状态在不同节点间漂移,达到无缝切换的高可用。
MHA Manager是一个核心的调度器,有了它可以调度多套环境,当然MHA Manager自身也有单点,所以会考虑两套MHA Manager节点来做冗余,实际上是做交叉互备,比如有100套环境,两个MHA Manager节点,那就每个分50个节点,如果Manager节点出现故障,可以很顺利的交接给Manager2来接管。
对于应用来说,就是统一通过VIP的方式来访问。如果是在这个基础上考虑中间件的方案,则数据访问的策略会更加复杂一些。
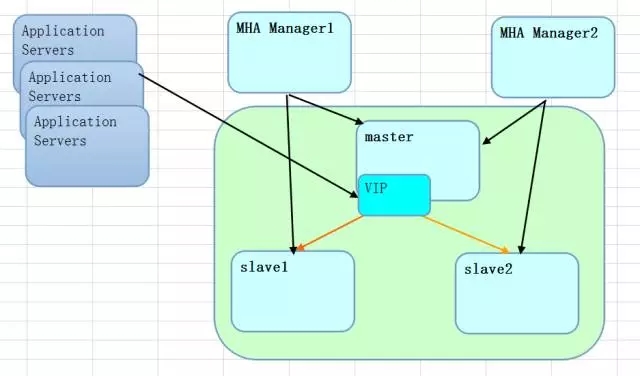
对于这样的一个基本方案,如果从多个维度来下钻会发现有很多需要注意的地方,所以问题无处不在,可喜的是在MHA中几乎都考虑到了。如果说得简单点,主要有下面的几个场景需要考虑:
- 数据库主库宕机
- 数据库从库宕机
- 重启数据库主库
- 重启数据库从库
- 从库应用延迟
- 主从网络延迟
- 主库服务器宕机
- 从库服务器宕机
- 一主多从切换优先级
- 网络抖动的切换
- 手工主从切换
- 主节点IP调整
- 从节点IP调整
- 添加从节点
- 剔除从节点
- 网络抖动的预防
- 半同步插件对于MHA的影响
- 自定义MHA脚本
所以上面的方案多多少少都需要考虑,如果用下面的图来表示,就会大体有如下的一些红色警告。所以各个层面都会有可能存在问题和异常,如何尽可能不影响业务,保持业务科持续访问是重中之重。
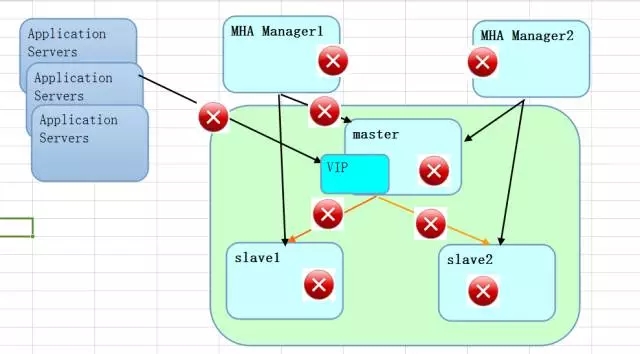
举一个比较纠结的问题,如果MHA Manager节点到数据库主库的网络发生抖动,导致短时间不可访问,我们是希望这个过程是不会做灾难切换的,但是如果时间过长了,有2分钟或者3分钟都不可访问,这个时候是切还是不切呢。这个时候信息还是相对较少的,如果我们加入应用服务器这个角色,如果应用服务器是可访问的,那么就不切,如果应用访问受到影响,那还是切吧。而且根据我们的测试,在MHA 0.56和0.57里面还是有一些差别。测试了多套环境,测试了多个特性,结合起来才会发现对于MHA的考虑会更加全面,而换句话说,了解了原委,才能更好的掌握MHA,也才能看到更多的问题,来尝试定制它,使得它更加满足于当前的业务需求。