【51CTO.com原创稿件】学习压力大、教育资源分配失衡的中国教育,衍生出数万在线教育类应用。随着应用数量的递增,教育内容和方式在总量上也水涨船高,但其中免费应用占比多,因缺乏内容支撑导致同质化的问题越来越严重。学霸君首席科学家陈锐锋在专访中表示,公司定位在成立之初就很明确,教师和学生是最重要的合作伙伴,学霸君不会替代老师,只会借力 ABCD 对抗知识孤岛,实现 EEE。
那 ABCD 是什么?EEE 又是什么呢?陈锐锋把学霸君的技术面归纳为ABCDEEE:
- A=AI。
- B=Big Data。
- C=Cloud。
- D= Delivery。
- EEE=Educational Efficiency Enhancement。
这些因素是为了增强教学效率,并没有直接 Education。也就是说,ABCD 不论如何开拓,都不能替代教育过程中教师这个环节,从开发拍照搜题软件,到线上一对一辅导,再到智慧教育平台,学霸君做的一切都是围绕这个观点进行。
打通知识痛点,把知识辅导变成知识图谱结构
学霸君一系列产品的核心目的是打通知识痛点,把知识辅导变成知识图谱结构,供老师和学生教学使用。想要实现这个目的,就要观测学生所看的各种数据,如书籍、试卷等。这些数据都是成框架体系的,但很多学生并不知情或不关注,只是无奈陷入题海围攻。框架体系就像人的神经网络,可以串起每一块肌肉,每一块骨头的运动。或许有人会说,书的大纲不就是框架体系吗。其实不然,还有更深层次的大纲并没有体现。
在学习过程中,框架的价值是非常重要的,如果理不清整个思路,随机游走的效率非常低,就像在沙漠中找绿洲,没有 GPS,成功寻到的机会非常渺茫。
如何构建这个框架呢?这就要靠人工智能、大数据收集分析、云计算服务和针对性内容推送,也就是前面提到的 ABCD!
大规模收集行为、知识等学习数据
2013 年,学霸君在思考采用什么方式,才能洞悉学生学什么,不懂什么?无论选择何种方式,数据都是基石,所以首先要做的事情是大规模收集数据。
阅卷系统是传统收集数据的方式,但存在边界限制,不仅难覆盖全国范围的学生、推广成本也很高,学霸君是通过拍照答疑场景来获取数据的。
具体实现是团队采用拍照上传的方式,让每个用户主动地告知后台服务器自己什么地方不懂,每一个图片的上传,代表了用户的一个能力缺失点。同时,文字识别技术的采用,将图片转化成为可关联分析的重要内容。
第二步,在识别的基础上,系统采用自然语言处理技术对识别后的结果进行分析和加工,将原始的识别文本打上相应的知识点标签,这就使数据能关联到同一个知识点下的考题,实现初步的推荐。
第三步,知识点标签大规模形成之后,教研老师们结合数据挖掘的支撑,将离散的题目梳理、聚合成关联的结构,并抽取出知识图谱。
经历了这几个步骤,目前数据加工团队已形成了结合识别、自动标签和关联分析的处理流程。
中国还有一个非常特殊的数据产生机制,那就是考试。考试环境带来了世界上其他国家都没有的高量级数据,即海量题库。
题库内除客观题,还有大量的主观题,而且每道题都有相应的答案。这些题目是由众多中国老师做好标注的数据,每个答案是这道题的数据标记。
这个海量题库使得我国在教育领域的智能分析有可能形成区别欧美国家的特色技术,因为它还被中国上亿的学生应用,行为也关联在其中。
除了上述行为数据、知识数据之外,还有一些社会数据。比如说学生跟家长的关联,家长跟老师的关联,老师跟学生的关联等等。
针对海量数据进行智能分析
我们对行为、知识的数据进行量化,为每个知识点配置相应的权重、难度和考试频次,为人工智能要做的事情做积累。
分析出高频题目,重点学习
假设构建一个有几千知识点的知识树,通过分析,就可从中判断出近百个高频知识点。学生只需要覆盖到最高频的题目,就可以获得相对较好的成绩,考上一所不错的大学,同时又对重要的知识有一个更强的认知。
具体实现可通过大数据平台,对题库中的题目进行题目画像,分析出相应知识点和难度。再结合学生的行为对学生进行用户画像。
最后对题目和学生进行关联分析,不仅能够提取出历年高考的高频考点,还能针对每一个学生提供个性化的学习方案。
那么反过来说,是不是一定要刷海量题库?答案是不一定的。之所以去盲目的刷海量题库,是因为不知道哪些是重点。
当知道内容重点的情况下,学生只需要刷 50%,甚至 40% 的基本题,就可以获得好的分数,且知识框架更为牢固。所以说,在不需要题海战术的情况下,学生就可以更大的产能去覆盖更好的空间。
搭建图谱化题库,实现精准知识搜取
梳理数据,利用深度学习、机器学习等技术手段搭建题库,再针对数学、化学、物理、生物这些主要学科搭建知识图谱,能够有效的组织 k12 领域(幼儿园到高中阶段)的各种知识的结构化。
有了这个特殊的题库,当学生在搜索某个知识点时,虽然行为看起来很微观,但实际打开之后,是更宏观的世界,如下图:
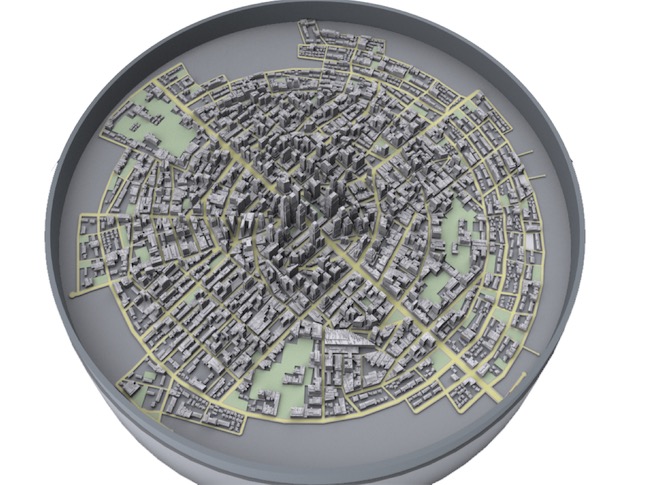
宏观的世界就像是地图,把每栋楼比作一道题,重新深入学习,把知识点较近的题目聚拢到一起,偏离较远的排斥开,映射成一张类似于地图的结构。这样做有什么好处呢?陈锐锋把学习过程类比成骑摩拜单车,骑过路线等同于做作业、考试学习的内容。当学生做某一道题,拍过或者阅读过某道题,就会把位置记录下来,就像摩拜记录在某个地方取车还车一样。
同时还可以记录学生对错的数据,基于错题分析,进行个人画像,如下图:
当对一个学生有一定的数据积累以后,就可以更清晰地勾勒他的学习轨迹。这样一来,就很好地避免了千人一面的问题。也就是把电商常用的千人千面或出行常用的技术用到教育领域。
还有一个效果是对学生做某些题目的对错情况进行分析,可对这个学生进行归类,归到已有学生群体中的某一类。如这个学生几何好,就为他排除几何题,推荐代数题。因为不同的知识点,不同的板块的学习内容,对学生抽象思维的能力要求各有不同;如男生在创新、没有边界的方向上会比较强,而女生在严谨性、严密性和架构性上会更强一点。
构建学习场景为教学做支撑
在大规模收集数据,利用智能手段进行分析搭建题库之后,下面要做的就是构建学习场景,为教学做支撑。
场景一:遇到问题,拍照搜题,实时得到解答
记忆不可以移植,所以老师一讲,学生就懂这种理想的状态很少见。一般来说,课堂授课犹如拨号上网会产生丢包,老师讲了很多,学生收集到的只是整个网络里面的一些节点。学生以为听懂了,但这其中的关联和关系并没有记忆在大脑里,所以就需要拍照搜题这一功能。大脑,对于我们来说就是一个黑盒,理论来讲对于不可观不可控的黑盒系统,需要通过它外围的情况去捕捉有用的数据。
想要知道一个学生不懂什么,就要观测他经常关注哪些,做什么样的题目出现了问题,这些可以直观反映出他不懂的内容并进行标识。拍照搜题,就是一个天然的收集学生不懂问题的通道。这里涉及到众多的识别技术,如下图:
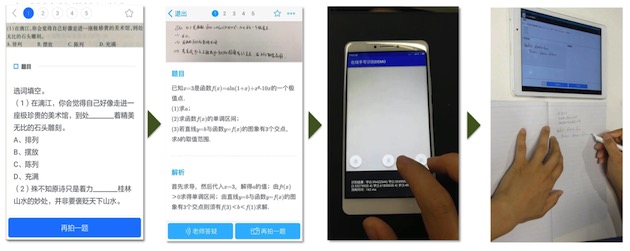
图中依次是对印刷体拍摄、手写体拍摄、手写单字联机、复杂手写体联机的识别,智能识别引擎在这里发挥着作用。
对于印刷体的识别,使用卷积神经网络提取图像特征,进行版面分析,将图像切分,之后分别识别出每一个字。对于手写体的识别,将在下面讲到。
场景二:根据作业情况有针对性的刷题和推荐练习
在 C 端,学生完成作业之后,拍照上传几分钟就可以知道所有题目的对错,系统会自动给出评判,根据结果给出自适应练习,做到今日事今日毕。
如下图,是学习数据识别与收集的流程:

学生手写的解题答案,首选通过卷积层神经网络进行初步计算,之后通过循环神经网络形成有梯度的数据结构,最后到达解码层进行解码。
针对学生的手写笔迹,首先采用卷积神经网络对图像进行多次卷积下采样,实现手写笔迹的行分割,之后对每一行结合非极大抑制方法进行笔画分割,从而把每一行的笔迹都转化为序列识别问题。再通过多层循环神经网络解码输出高精度的识别结果。
在 B 端,如果每个班级的学生都把作业上传,由系统进行评改之后,映射到知识图谱、行为图谱中,老师就可以掌握每个学生的学习情况。
传统教学中,就算是特级老师也没有办法记忆每个学生的每个细节,没法形成闭环,因为相关数据不进系统,需要老师去完成闭环衔接的环节。
这时老师就变成这个环节里面的一个瓶颈,从某种程度来说,既弱化了老师的价值,又使得学生的需求得不到及时响应。
老师最大的价值应该是育人,去引导,而不是帮每个学生去记忆哪个题存在问题。而采用这样的方式后,节省人力的同时还可以把这些相关数据都沉淀下来,形成闭环。
场景三:学生可以进行自我评测和练习
学霸君基于大数据与智能分析对 8000 万题库进行了梳理,提供给学生做自适应的自我评测。然后把评测结果反馈给学生的同时有针对性地推荐练习题。
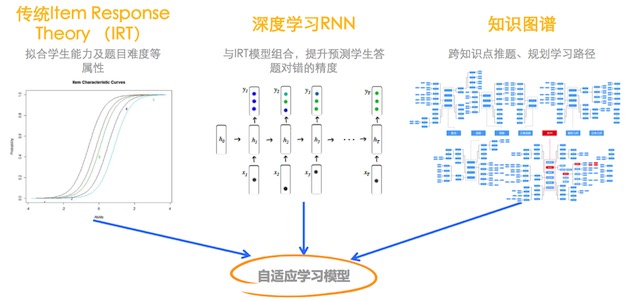
目前实现的效果是综合学生能力、题目难度等属性,与 IRT 模型相组合,提升预测学生答题对错的精度,并为学生跨知识点推送题目、规划学习路径。
关于未来
当问及对未来教育方面的畅想,陈锐锋回答:“未来希望学习过程更轻松一点,把学习变成一个愉快的事情,把反复的遇到瓶颈并且得不到解答的痛苦减到最小,有问题可以得到及时的解答。想了解的,通过无论是软件资源,还是远程的老师资源,得到一些支持服务,使学生在信息的获取上得到及时响应。当然,这需要有大量的数据沉淀,真正了解学生背后想了解什么,才能做到个性化的推送所需要的内容知识。”
做到这些还需要面临很多的挑战:
更深度层次,更智能化的,更能抓住细节的一个分析框架。如,是不是能够分析学生手写的节奏,进而分析他的性格,像比较好动、比较拖延等性格行为,且从性格行为上给予梳理。因为有时候,学生的行为不仅仅是知识,也可以影响学习效率。
能否拥有一个更全的数据。因为无论是做题库,做内容,做文库,做其他相应的学习视频,数据量虽然很大,但只是覆盖了其中一部分,我们还想覆盖得更全。
理论层次上有更体系化的梳理。中国现在的 AI+ 教育或是教育 +AI,实际上是没有一个非常成型的理论体系,希望能够把这两个模块放在一块,产生行之有效的理论方向,能够指导去做后面的事情。
新加坡国立大学博士,2013 年入职学霸君,担任技术研究负责人职务,组建智能计算团队,主攻文字识别、图像算法和数据挖掘方向。带领团队在国内率先开创同时适应自然场景、复杂版式图像拍照识别引擎,为搜题及 1V1 实时答疑业务奠定了技术基础。同时,将基于深度学习的文本挖掘技术引入产品,实现高效而智能化的知识导航。

【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】