最近和很多实时音视频领域的朋友交流中都有谈论到RUDP(Reliable UDP),这其实是个老生常谈的问题,RUDP在很多著名的项目上都有使用,例如google的QUIC和webRTC。在UDP之上做一层可靠,很多朋友认为这是很不靠谱的事情,也有朋友认为这是一个大杀器,可以解决实时领域里大部分问题。作为在教育公司来说,学霸君在很多实时场景下确实使用RUDP技术来解决我们的问题,不同场景我们采用的RUDP方式也不一样。先来看看学霸君哪些场景使用了RUDP:
- 全局250毫秒延迟的实时1V1答疑,采用的是RUDP + 多点relay智能路由方案。
- 500毫秒1080P视频连麦互动系统,采用的是RUDP + PROXY调度传输方案。
- 6方实时同步书写系统,采用的是RUDP+redo log的可靠传输技术。
- 弱网WIFI下Pad的720P同屏传输系统,采用的是RUDP +GCC实时流控技术。
- 大型直播的P2P分发系统,通过RUDP + 多点并联relay技术节省了75%以上的分发带宽。
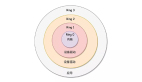
涉及到实时传输我们都会先考虑RUDP,RUDP应用在学霸君核心传输体系的各个方面,但不同的系统场景我们设计了不同的RUDP方式,所以基于那些激烈的讨论和我们使用的经验我扒一扒RUDP。其实在实时通信领域存在一个三角平衡关系:成本,质量,时延三者的制约关系(图1)

图1
也就是说投入的成本、获得的质量和通信的时延之间是一个三角制约(LEQ)关系,所以实时通信系统的设计者会在这三个制约条件下找到一个平衡点,TCP属于是通过增大延迟和传输成本来保证质量的通信方式,UDP是通过牺牲质量来保证时延和成本的通信方式,所以在一些特定场景下RUDP更容易找到这样的平衡点。RUDP是怎么去找这个平衡点的,就要先从RUDP的可靠概念和使用场景来分析。
可靠的概念
在实时通信过程中,不同的需求场景对可靠的需求是不一样的,我们在这里总体归纳为三类定义:
-
尽力可靠:通信的接收方要求发送方的数据尽量完整到达,但业务本身的数据是可以允许缺失的。例如:音视频数据、幂等性状态数据。
-
无序可靠:通信的接收方要求发送方的数据必须完整到达,但可以不管到达先后顺序。例如:文件传输、白板书写、图形实时绘制数据、日志型追加数据等。
-
有序可靠:通信接收方要求发送方的数据必须按顺序完整到达。
RUDP是根据这三类需求和图1的三角制约关系来确定自己的通信模型和机制的,也就是找通信的平衡点。
UDP为什么要可靠
说到这里可能很多人会说:干嘛那么麻烦,直接用TCP好了!确实很多人也都是这样做的,TCP是个基于公平性的可靠通信协议,在一些苛刻的网络条件下TCP要么不能提供正常的通信质量保证,要么成本过高。为什么要在UDP之上做可靠保证,究其原因就是在保证通信的时延和质量的条件下尽量降低成本,RUDP主要解决以下相关问题:
-
端对端连通性问题:一般终端直接和终端通信都会涉及到NAT穿越,TCP在NAT穿越实现非常困难,相对来说UDP穿越NAT却简单很多,如果是端到端的可靠通信一般用RUDP方式来解决,场景有:端到端的文件传输、音视频传输、交互指令传输等等。
-
弱网环境传输问题:在一些WIFI或者3G/4G移动网下,需要做低延迟可靠通信,如果用TCP通信延迟可能会非常大,这会影响用户体验。例如:实时的操作类网游通信、语音对话、多方白板书写等,这些场景可以采用特殊的RUDP方式来解决这类问题。
-
带宽竞争问题:有时候客户端数据上传需要突破本身TCP公平性的限制来达到高速低延时和稳定,也就是说要用特殊的流控算法来压榨客户端上传带宽,例如:直播音视频推流,这类场景用RUDP来实现不仅能压榨带宽,也能更好的增加通信的稳定性,避免类似TCP的频繁断开重连。
-
传输路径优化问题:在一些对延时要求很高的场景下,会用应用层relay的方式来做传输路由优化,也就是动态智能选路,这时双方采用RUDP方式来传输,中间的延迟进行relay选路优化延时。还有一类基于传输吞吐量的场景,例如:服务与服务之间数据分发、数据备份等,这类场景一般会采用多点并联relay来提高传输的速度,也是要建立在RUDP上的(这两点在后面着重来描述)。
-
资源优化问题:某些场景为了避免TCP的三次握手和四次挥手的过程,会采用RUDP来优化资源的占用率和响应时间,提高系统的并发能,例如:QUIC.
不管哪类场景,都是要保证可靠性,也就是质量,那么在UDP之上怎么实现可靠呢?答案就是重传。
重传模式
IP协议在设计的时候就不是为了数据可靠到达而设计的,所以UDP要保证可靠,就依赖于重传,这也就是我们通常意义上的RUDP行为,在描述RUDP重传之前先来了解下RUDP基本框架,如图:

图2
RUDP在分为发送端和接收端,每一种RUDP在设计的时候会做不一样的选择和精简,概括起来就是图中的单元。RUDP的重传是发送端通过接收端ACK的丢包信息反馈来进行数据重传,发送端会根据场景来设计自己的重传方式,重传方式分为三类:定时重传,请求重传和FEC选择重传。
定时重传
定时重传很好理解,就是发送端如果在发出数据包(T1)时刻一个RTO之后还未收到这个数据包的ACK消息,那么发送就重传这个数据包。这种方式依赖于接收端的ACK和RTO,容易产生误判,主要有两种情况:
对方收到了数据包,但是ACK发送途中丢失。
ACK在途中,但是发送端的时间已经超过了一个RTO。
所以超时重传的方式主要集中在RTO的计算上,如果你的场景是一个对延迟敏感但对流量成本要求不高的场景,就可以将RTO的计算设计比较小,这样能尽***可能保证你的延时足够小。例如:实时操作类网游、教育领域的书写同步,是典型的用expense换latency和Quality的场景,适合用于小带宽低延迟传输。如果是大带宽实时传输,定时重传对带宽的消耗是很大的,极端情况会用20%的重复重传率,所以在大带宽模式下一般会采用请求重传模式。
请求重传
请求重传就是接收端在发送ACK的时候携带自己丢失报文的信息反馈,发送端接收到ACK信息时根据丢包反馈进行报文重传。如下图:

图3
这个反馈过程最关键的步骤就是回送ACK的时候应该携带哪些丢失报文的信息,因为UDP在网络传输过程中会乱序会抖动,接收端在通信的过程中要评估网络的jitter time,也就是rtt_var(RTT方差值),当发现丢包的时候记录一个时刻t1,当t1 + rtt_var < curr_t(当前时刻),我们就认为它丢失了,这个时候后续的ACK就需要携带这个丢包信息并更新丢包时刻t2,后续持续扫描丢包队列,如果他t2 + RTO <curr_t,再次在ACK携带这个丢包信息,以此类推,直到收到报文为止。这种方式是由丢包请求引起的重发,如果网络很不好,接收端会不断发起重传请求,造成发送端不停的重传,引起网络风暴,通信质量会下降,所以我们在发送端设计一个拥塞控制模块来限流,这个后面我们重点分析。除了网络风暴以外,整个请求重传机制也依赖于jitter time和RTO这个两个时间参数,评估和调整这两个参数和对应的传输场景也息息相关。请求重传这种方式比定时重传方式的延迟会大,一般适合于带宽较大的传输场景,例如:视频、文件传输、数据同步等。
FEC选择重传
除了定时重传和请求重传模式以外,还有一种方式就是以FEC分组方式选择重传,FEC(Forward Error Correction)是一种前向纠错技术,一般是通过XOR类似的算法来实现,也有多层的EC算法和raptor涌泉码技术,其实是一个解方程的过程。应用到RUDP上示意图如下:

图4
在发送方发送报文的时候,会根据FEC方式把几个报文进行FEC分组,通过XOR的方式得到若干个冗余包,然后一起发往接收端,如果接收端发现丢包但能通过FEC分组算法还原,就不向发送端请求重传,如果分组内包是不能进行FEC恢复的,就请求想发送端请求原始的数据包。FEC分组方式适合解决要求延时敏感且随机丢包的传输场景,在一个带宽不是很充裕的传输条件下,FEC会增加多余的冗余包,可能会使得网络更加不好。FEC方式不仅可以配合请求重传模式,也可以配合定时重传模式。
RTT与RTO的计算
在上面介绍重传模式时多次提到RTT、RTO等时间度量阐述,RTT(Round Trip Time)即网络环路延时,环路延迟是通过发送的数据包和接收到的ACK包计算了,示意图如下:

图5
RTT = T2 - T1,这个计算方式只是计算了某一个报文时刻的RTT,但网络是会波动的,这难免会有噪声现象,所以在计算的过程中引入了加权平均收敛的方法(具体可以参考RFC793)。
SRTT = (α * SRTT) + (1-α)RTT,这样可以求得新逼近的SRTT,在公式总一般α=0.8,确定了SRTT,下一步就是计算RTT_VAR(方差),我们设RTT_VAR = |SRTT – RTT|
那么SRTT_VAR =(α * SRTT_VAR) + (1-α) RTT_VAR,这样可以得到RTT_VAR的值,但最终我们是需要去顶RTO,因为涉及到报文重传,RTO就是一个报文的重传周期,从网络的通信流程我们很容易知道,重传一个包以后,如果一个RTT+RTT_VAR之后的时间还没收到确定,那我们就可以再次重传,则可知:
RTO = SRTT + SRTT_VAR
但一般网络在严重抖动的情况下还是会有较大的重复率问题,所以:
RTO = β*(SRTT + RTT_VAR)
1.2 <β<2.0,可以根据不同的传输场景来选择β的值。
RUDP是通过重传来保证可靠的,重传在三角平衡关系中其实是用Expense和latency来换取Quality的行为,所以重传会引来两个问题,一个是延时,一个是重传的带宽,尤其是后者,如果控制不好会引来网络风暴,所以在发送端会设计一个窗口拥塞机制了避免并发带宽占用过高的问题。
窗口与拥塞控制
-
窗口
RUDP需要一个收发的滑动窗口系统来配合对应的拥塞算法来做流量控制,有些RUDP需要严格的发送端和接收端的窗口对应,有些RUDP是不要收发窗口严格对应。如果涉及到可靠有序的RUDP,接收端就要做窗口就要做排序和缓冲,如果是无序可靠或者尽力可靠的场景,接收端一般就不做窗口缓冲,只做位置滑动。先来看收发窗口关系图:

图6
上图描述的是发送端从发送窗口中发了6个数据报文给接收端,接收端收到101,102,103,106时会先判断报文的连续性并滑动窗口开始位置到103,,然后每个包都回应ACK,发送端在接收到ACK的时候,会确认报文的连续性,并滑动窗口到103,发送端会再判断窗口的空余,然后填补新的发送数据,这就是整个窗口滑动的流程。这里值的一提的是在接收端收到106时的处理,如果是有序可靠,那么106不会通知上层业务进行处理,而是等待104,105。如果是尽力可靠和无序可靠场景,会将106通知给上层业务先进行处理。在收到ACK后,发送端的窗口要滑动多少是由自己的拥塞机制定的,也就是说窗口的滑动速度受拥塞机制控制,拥塞控制实现要么基于丢包率来实现,要么基于双方的通信时延来实现,下面来看几种典型的拥塞控制。
-
经典拥塞算法
TCP经典拥塞算法分为四个部分:慢启动、拥塞避免、拥塞处理和快速恢复,这四个部分都是为了决定发送窗和发送速度而设计的,其实就是为了在当前网络条件下通过网络丢包来判断网络拥塞状态,从而确定比较适合的发送传输窗口。经典算法是建立在定时重传的基础上的,如果RUDP采用这种算法来做拥塞控制,一般的场景是为了保证有序可靠传输的同时又兼顾网络传输的公平性原则。先逐个来解释下这几部分
-
慢启动(slow start)
当连接链路刚刚建立后,不可能一开始将cwnd设置的很大,这样容易造成大量重传,经典拥塞里面会在开始将cwnd = 1,让后根据通信过程的丢包来逐步扩大cwnd来适应当前的网络状态,直到达到慢启动的门限阈值(ssthresh),步骤如下:
1) 初始化设置cwnd = 1,并开始传输数据
2) 收到回馈的ACK,会将cwnd 加1
3) 当一个发送端一个RTT后且未发现有丢包重传,就会将cwnd = cwnd * 2.
4) 当cwnd >= ssthresh或发生丢包重传时慢启动结束,进入拥塞避免状态。
-
拥塞避免
当通信连接结束慢启动后,有可能还未到网络传输速度的上线,这个时候需要进一步通过一个缓慢的调节过程来进行适配。一般是一个RTT后如果未发现丢包,就是将cwnd = cwnd + 1。一但发现丢包和超时重传,就进入拥塞处理状态。
-
拥塞处理
拥塞处理在TCP里面实现很暴力,如果发生丢包重传,直接将cwnd = cwnd / 2,然后进入快速恢复状态。
-
快速恢复
快速恢复是通过确认丢包只发生在窗口一个位置的包上来确定是否进行快速恢复,如图6中描述,如果只是104发生了丢失,而105,106是收到了的,那么ACK总是会将ack的base = 103,如果连续3次收到base为103的ACK,就进行快速恢复,也就是将并立即重传104,而后如果收到新的ACK且base > 103,
将cwnd = cwnd + 1,并进入拥塞避免状态。
经典拥塞控制是基于丢包检测和定时重传模式来设计的,在三角平衡关系中是一个典型的以Latency换取Quality的案例,但由于其公平性设计避免了过高的Expense,也就会让这种传输方式很难压榨网络带宽,很难保证网络的大吞吐量和小时延。
-
BRR拥塞算法
对于经典拥塞算法的延迟和带宽压榨问题google设计了基于发送端延迟和带宽评估的BBR拥塞控制算法。这种拥塞算法致力于解决两个问题:
- 在一定丢包率网络传输链路上充分利用带宽
- 降低网络传输中的buffer延迟
BBR的主要策略是就是周期性通过ACK和NACK返回来评估链路的min_rtt和max_bandwidth。***吞吐量(cwnd)的大小就是:
- cwnd = max_bandwidth / min_rtt
传输模型如下:

图7
BBR整个拥塞控制是一个探测带宽和Pacing rate的状态,有是个状态:
Startup:启动状态(相当于慢启动),增益参数为max_gain = 2.85
DRAIN:满负荷传输状态
PROBE_BW:带宽评估状态,通过一个较小的BBR增益参数来递增(1.25)或者递减(0.75).
PROBE_RTT:延迟评估状态,通过维持一个最小发送窗口(4个MSS)进行的RTT采样。
那么这几种状态是怎么且来回切换的呢?以下是QUIC中BBR大致的步骤如下:
- 初始化连接时会将设置一个初始的cwnd = 8, 并将状态设置Startup
- 在Startup下发送数据,根据ACK数据的采样周期性判断是否可以增加带宽,如果可以,将cwnd = cwnd *max_gain。如果时间周期数超过了预设的启动周期时间或者发生了丢包,进行DRAIN状态
- 在DRAIN状态下,如果flight_size(发送出去但还未确认的数据大小) >cwnd,继续保证DRAIN状态,如果flight_size<cwd,进入PROBE_BW状态
- 在PROBE_BW状态下,如果未发生丢包且flight_size<cwnd * 1.25,将维持原来的cwnd,并进入StartUp,如果发生丢包或者flight_size > cwnd,将cwnd = cwnd * 1.25,如果发生丢包,cwnd = cwnd * .075
- 在Startup/DRAIN/PROBE_BW三个状态中,如果持续10秒钟的通信中没有出现RTT <= min_rtt,就会进入到PROBE_RTT状态,并将cwnd = 4 *MSS
- 在PROBE_RTT状态,会在收到ACK返回的时候持续判断flight_size >= cwnd并且无丢包,将本次统计的最小RTT作为min_rtt,进入Startup状态。
BBR是通过以上几个步骤来周期性计算cwnd,也就是网络***吞吐量和最小延迟,然后通过pacing rate来确定这一时刻发送端的码率,最终达到拥塞控制的目的。BBR适合在随机丢包且网络稳定的情况下做拥塞,如果在网络信号极不稳定的WIFI或者4G上,容易出现网络泛洪和预测不准的问题,BBR在多连接公平性上也存在小RTT的连接比大RTT的连接更吃带宽的情况,容易造成大RTT的连接速度过慢的情况。BBR拥塞算法在三角平衡关系中是采用Expense换取latency和Quality的案例。
-
webRTC gcc
说到音视频传输就必然会想到webRTC系统,在webRTC中对于视频传输也实现了一个拥塞控制算法(gcc),webRTC的gcc是一个基于发送端丢包率和接收端延迟带宽统计的拥塞控制,而且是一个尽力可靠的传输算法,在传输的过程中如果一个报文重发太多次后会直接丢弃,这符合视频传输的场景,借用weizhenwei同学一张图来看个究竟:

图8
gcc的发送端会根据丢包率和一个对照表来pacing rate,当loss < 2%时,会加大传输带宽,当loss >=2% &&loss <10%,会保持当前码率,当loss >=10%,会认为传输过载,进行调小传输带宽.
gcc的接收端是根据数据到达的延迟方差和大小进行KalmanFilter进行带宽逼近收敛,具体的细节不介绍了,请查看http://www.jianshu.com/p/bb34995c549a
这里值得一说的是gcc引入接收端对带宽进行KalmanFilter评估是一个非常新颖的拥塞控制思路,如果实现一个尽力可靠的RUDP传输系统不失为是一个很好的参考。但这种算法也有个缺陷,就是在网络间歇性丢包情况下,gcc可能收敛的速度比较慢,在一定程度上有可能会造成REMB很难反馈给发送端,容易出现发送端流控失效。gcc在三角平衡关系算一个以Quality和Expense换取latency的案例。
-
弱窗口拥塞机制
其实在很多场景是不用拥塞控制或者只要很弱的拥塞控制即可,例如:师生双方书写同步、实时游戏,因为本身的传输的数据量不大,只要保证足够小的延时和可靠性就行,一般会采用固定窗口大小来进行流控,我们在系统中一般采用一个cwnd =32这样的窗口来做流控,ACK确认也是通过整个接收窗口数据状态反馈给发送方,简单直接,也很容易适应弱网环境。
传输路径
RUDP除了优化连接、压榨带宽、适应弱网环境等以外,它也继承了UDP天然的动态性,可以在中间应用层链路上做传输优化,一般分为多点串联优化和多点并联优化。我们具体来说一说。
-
多点串联relay
在实时通信中一些对业务场景对延迟非常敏感,例如:实时语音、同步书写、实时互动、直播连麦等,如果单纯的服务中转或者P2P通信,很难无法满足其需求,尤其是在物理距离很大的情况下。在解决这个问题上SKYPE率先提出全球RTN(实时多点传输网络),其实就是在通信双方之间通过几个relay节点来动态智能选路,这种传输方式很适合RUDP,我们只要在通信双方构建一个RUDP通道,中间链路只是一个无状态的relay cache集合,relay与relay之间进行路由探测和选路,以此来做到链路的高可用和实时性。如下图:

图9
通过多点relay来保证rudp进行传输优化,这类场景在三角平衡关系里是典型的用expense来换取latency的案例。
-
多点并联relay
在服务与服务进行媒体数据传输或者分发过程中,需要保证传输路径高可用和提高带宽并发,这类使用场景也会使用传输双方构建一个RUDP通道,中间通过多relay节点的并联来解决,如下图所示:

图10
这种模型需要在发送端设计一个多点路由表探测机制,以此来判断各个路径同时发送数据的比例和可以用性,这个模型除了链路备份和增大传输并发带宽外,还有个辅助的功能,如果是流媒体分发系统,我们一般会用BGP来做中转,如果节点与节点之间可以直连,这样还可以减少对BGP带宽的占用,以此来减少成本问题。
后记
到这里RUDP的介绍也就结束了,说了些细节和场景相关的事,也算是个入门级的科普文章。RUDP的概念从提出到现在也差不多有20年了,很多从业人员这希望通过一套完善的方案来设计一个通用的RUDP,我个人觉得这不太可能,就算设计出来了,估计和现在TCP差不多,这样做的意义不大。RUDP的价值在于根据不同的传输场景进行不同的技术选型,可能选择宽松的拥塞方式、也可能选择特定的重传模式,但不管怎么选,都是基于Expense(成本)、Latency(时延)、Quality(质量)三者之间来权衡,通过结合场景和权衡三角平衡关系RUDP或许能帮助开发者找到一个比较好的方案。
【作者简介】
袁荣喜,学霸君资深架构师,16年的C程序员,Golang爱好者,好求甚解,善于构建高性能服务系统和系统性能调优,喜好解决系统的疑难杂症和debug技术。早年痴迷于P2P通信网络、TCP/IP通信协议栈和鉴权加密技术,曾基于P2P super node技术实现了视频实时传输系统。2015年加入学霸君,负责构建学霸君的智能路由实时音视频传输系统和网络,解决音视频通信的实时性的问题。专注于存储系统和并发编程,对paxos和raft分布式协议饶有兴趣。尤其喜欢数据库内核和存储引擎,坚持不懈对MySQL/innoDB和WiredTiger的实现和事务处理模型进行探究。热衷于开源,曾为开源社区提过些patch。业余时间喜欢写技术长文,喜欢唐诗。