













自从深度学习大热,广泛应用于语音识别以来,字幕中的单词错误率急剧下降。尽管如此,语音识别并没有达到人文水平,它仍会出现一些故障。承认这些然后采取措施来解决这些问题对于语音识别的进步至关重要。这是唯一的从可以识别一些人的ASR到识别任何时间任何人的ASR的方式。
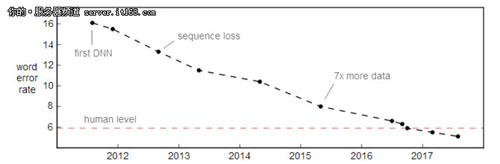
在近期的Switchboard语音识别基准测试中,单词的错误率得到改进。Switchboard集其实是在2000年收集的,它是由两个随机的以英语为母语的人之间的40个电话对话组成。
可以说目前我们已经在会话式语音识别上达到“人类”水平,但仅仅只是在Switchboard方面。这个结果就像是在一个阳光灿烂的日子里的某城市中,只有一个人驾驶着自动驾驶汽车进行测试。最近在这方面取得的进步令人惊讶,但是,关于达到“人类”水平的说法还是太过宽泛,以下是一些仍需要改进的几个方面。
口音和噪音
语音识别中最明显的缺陷之一是处理口音和背景噪声。最直接的原因是,大多数训练数据是由具有高信噪比的美国口音的英语组成。
但是,更多的训练数据可能并不能自行解决这个问题。现实生活中,也有许多方言和口音。因此,用标注数据去应对所有情况是不可行的。构建一个高质量的语音识别器,转录了5000多小时的音频难道只是为了以英语为母语的人?

将转录器与百度的深度语音识别系统Deep Speech 2 比较后发现在转录非美国口音时情况更糟糕。可能是由于美国人在转录时的偏见。
在背景有噪音的情况下,移动汽车的信噪比低至5DB并不罕见。这种环境下,人们也能够很好的听清彼此。另一方面,语音识别器在噪声方面的降解速度更快。在上图中,可以清楚看到人力和模型误差率之间的差距,从低信噪比急剧上升到高信噪比。
语义错误
在语音识别系统中,单词错误率通常不是实际的目标,语义错误率才是我们关注的重点。因为,语义正确与否关系到对他人话语的理解程度。
一个语义错误的例子是,如果有人说“让我们在星期二见面”,但是语音识别器识别为“我们今天就见面”。这是出现了单词错误却没有语义错误,当然,情况也可能反过来。
使用错误率作为代理服务时,必须谨慎。先举一个最坏的例子来说明原因。一个5%的回答可能相当于每20个单词就漏掉一个。那么,如果一句话只有20 个单词的话,那么这句话的错误率可能就是100%。
当将模型与人类进行比较时,检查错误的本质是非常重要的,而不仅仅是将答案视为一个确定的数字。就经验来看,人类的转录要比语音识别器产生更少的语义错误。
微软的研究人员最近比较了人类转录及其人类语言识别器所犯的错误,发现的一个差异在于,该模型混淆了“uh”和“uh huh”。这两个词有完全不同的语义。模型和人力都犯了很多相同类型的错误。
单通道,多个扬声器
由于每个扬声器都使用单独的麦克风进行录音,所以 Switchboard会话任务也更容易。同一音频流中,多个扬声器没有重叠。另一方面,人类可以很好的理解多个扬声器有时在同一时间进行的通话的内容。
一个好的会话语音识别器必须能够根据谁在说话(diarisation)来分割音频。它也应该能够使用重叠的扬声器(音源分离)来理解音频。这是可行的,不需要麦克风每一个扬声器,以便会话语音可以在任意位置都能工作。
域的变化
口音和背景噪声是语音识别器的两个重要的因素,这里还有一些:
- 混响声音环境变化
- 来自硬件的artefacts
- 用于音频和压缩的artefacts
- 采样率
- 说话人的年龄
大多数人甚至不会注意到mp3和普通wav文件之间的区别。在声明人力性能之前,语音识别器也需要对这些变化的来源进行强大的支持。
上下文
你会发现,像“开关板”这样的单词的错误率实际上会很高,如果你和一个朋友交谈,他们误解了每20个字中的1个,那么你就会很难沟通。
其中的一个原因是评估是在上下文中完成的。在现实生活中,我们会使用许多其他线索、结合语境来帮助我们了解某人在说什么。但语音识别器不能识别这些:
- 对话的历史和讨论的话题
- 关于我们正在说话的人的视觉暗示包括表情和唇部运动
- 说话的人的背景
目前,Android的语音识别器已经掌握你的联系人列表,因此它可以识别你的朋友的姓名。地图产品中的语音搜索可以使用地理定位来缩小你可能想要浏览的感兴趣的地点。当使用这种类型的信号时,ASR系统的精度肯定会提高。
部署
当要部署一个新的算法的时候,可以考虑延迟和算法,因为增加计算的算法往往会增加延迟,但为了简单起见,接下来将分别讨论。
延迟:完成转录之后,低延迟是十分常见的,它会显著影响用户的体验。因此,几十毫秒内的延迟要求对于ASR系统来说并不少见。虽然这可能听起来会有些极端,但这通常是一系列昂贵计算的***步,所以,必须谨慎。

将未来信息有效地纳入语音识别的好方法到目前为止仍然是一个开放的问题,有待讨论。
计算:记录话语所需的计算能力是一种经济约束。我们必须考虑到对语音识别器的每一个精度的改进。如果改进不符合经济阈值,则无法部署。
一个从未被部署的持续改进的经典例子是集成。1%或2%的误差降低可能会达到2-8倍的计算增长,现代的RNN语言模型通常也属于这一类。
实际上,并不建议在很大的计算成本上提高准确性,已经有“先慢但准确,然后加速”的工作模式。但关键在于,直到改进足够快,它仍是不可用的。
未来五年
语音识别中还存在许多开放性和挑战性的问题。这些包括:
·扩大新领域,口音和远场,低信噪比
·将更多的上下文融入识别过程
·Diarisation和源分离
·超低延迟和高效推理
期待在今后的五年在这些方面都能取得进展













