爬虫和反爬的对抗一直在进行着… 为了帮助更好的进行爬虫行为以及反爬, 今天就来介绍一下网页开发者常用的反爬手段。
1. BAN IP :网页的运维人员通过分析日志发现最近某一个IP访问量特别特别大,某一段时间内访问了无数次的网页,则运维人员判断此种访问行为并非正常人的行为,于是直接在服务器上封杀了此人IP。
解决方法:此种方法极其容易误伤其他正常用户,因为某一片区域的其他用户可能有着相同的IP,导致服务器少了许多正常用户的访问,所以一般运维人员不会通过此种方法来限制爬虫。不过面对许多大量的访问,服务器还是会偶尔把该IP放入黑名单,过一段时间再将其放出来,但我们可以通过分布式爬虫以及购买代理IP也能很好的解决,只不过爬虫的成本提高了。
2. BAN USERAGENT :很多的爬虫请求头就是默认的一些很明显的爬虫头python-requests/2.18.4,诸如此类,当运维人员发现携带有这类headers的数据包,直接拒绝访问,返回403错误
解决方法:直接r=requests.get(url,headers={'User-Agent':'Baiduspider'})把爬虫请求headers伪装成百度爬虫或者其他浏览器头就行了。
案例:雪球网
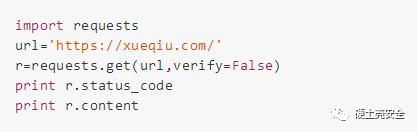
返回的就是
403
403 Forbidden.
Your IP Address: xxx.xxx.xxx.xxx .
但是当我们这样写:
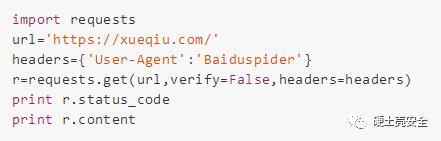
返回的就是
200
< !DOCTYPE html><html …
3. BAN COOKIES :服务器对每一个访问网页的人都set-cookie,给其一个cookies,当该cookies访问超过某一个阀值时就BAN掉该COOKIE,过一段时间再放出来,当然一般爬虫都是不带COOKIE进行访问的,可是网页上有一部分内容如新浪微博是需要用户登录才能查看更多内容。
解决办法:控制访问速度,或者某些需要登录的如新浪微博,在某宝上买多个账号,生成多个cookies,在每一次访问时带上cookies
案例:蚂蜂窝
以前因为旅游的需求,所以想到了去抓一点游记来找找哪些地方好玩,于是去了蚂蜂窝网站找游记,一篇一篇的看真的很慢,想到不如把所有文章抓过来然后统计每个词出现的频率***,统计出最热的一些旅游景点,就写了一个scrapy爬虫抓游记,当修改了headers后开始爬取,发现访问过快服务器就会断开掉我的连接,然后过一段时间(几个小时)才能继续爬。于是放慢速度抓就发现不会再被BAN了。
4. 验证码验证 :当某一用户访问次数过多后,就自动让请求跳转到一个验证码页面,只有在输入正确的验证码之后才能继续访问网站
解决办法:python可以通过一些第三方库如(pytesser,PIL)来对验证码进行处理,识别出正确的验证码,复杂的验证码可以通过机器学习让爬虫自动识别复杂验证码,让程序自动识别验证码并自动输入验证码继续抓取
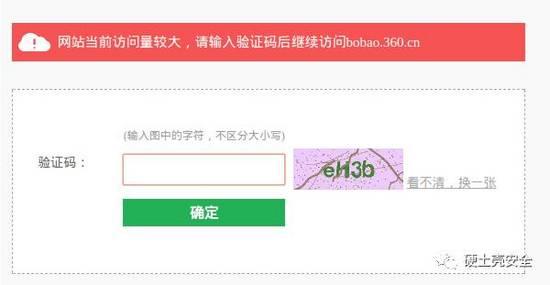
案例:安全客
当访问者对安全客访问过快他就会自动蹦出一个验证码界面。
如下:
5. javascript渲染 :网页开发者将重要信息放在网页中但不写入html标签中,而浏览器会自动渲染<script>标签中的js代码将信息展现在浏览器当中,而爬虫是不具备执行js代码的能力,所以无法将js事件产生的信息读取出来
解决办法:通过分析提取script中的js代码来通过正则匹配提取信息内容或通过webdriver+phantomjs直接进行无头浏览器渲染网页。
案例:前程无忧网
随便打开一个前程无忧工作界面,直接用requests.get对其进行访问,可以得到一页的20个左右数据,显然得到的不全,而用webdriver访问同样的页面可以得到50个完整的工作信息。
6. ajax异步传输 :访问网页的时候服务器将网页框架返回给客户端,在与客户端交互的过程中通过异步ajax技术传输数据包到客户端,呈现在网页上,爬虫直接抓取的话信息为空
解决办法:通过fiddler或是wireshark抓包分析ajax请求的界面,然后自己通过规律仿造服务器构造一个请求访问服务器得到返回的真实数据包。
案例:拉勾网
打开拉勾网的某一个工作招聘页,可以看到许许多多的招聘信息数据,点击下一页后发现页面框架不变化,url地址不变,而其中的每个招聘数据发生了变化,通过chrome开发者工具抓包找到了一个叫请求了一个叫做https://www.lagou.com/zhaopin/Java/2/?filterOption=3的网页,
打开改网页发现为第二页真正的数据源,通过仿造请求可以抓取每一页的数据。

很多网页的运维者通过组合以上几种手段,然后形成一套反爬策略,就像之前碰到过一个复杂网络传输+加速乐+cookies时效的反爬手段。
7. 加速乐 :有些网站使用了加速乐的服务,在访问之前先判断客户端的cookie正不正确。如果不正确,返回521状态码,set-cookie并且返回一段js代码通过浏览器执行后又可以生成一个cookie,只有这两个cookie一起发送给服务器,才会返回正确的网页内容。
解决办法 :将浏览器返回的js代码放在一个字符串中,然后利用nodejs对这段代码进行反压缩,然后对局部的信息进行解密,得到关键信息放入下一次访问请求的头部中。
案例:加速乐
这样的一个交互过程仅仅用python的requests库是解决不了的,经过查阅资料,有两种解决办法:
***种将返回的set-cookie获取到之后再通过脚本执行返回的eval加密的js代码,将代码中生成的cookie与之前set-cookie联合发送给服务器就可以返回正确的内容,即状态码从521变成了200。

直接通过这一段就可以获取返回的一段经过压缩和加密处理的js代码
类似于这种:
所以我们需要对代码进行处理,让其格式化输出,操作之后如下:
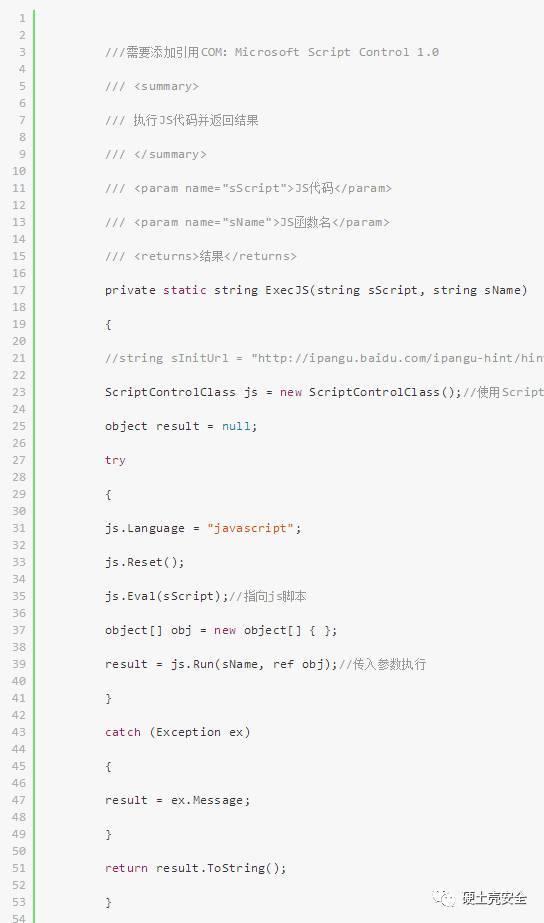
这里我们就需要对这段JS做下修改,假设我们先把这段JS代码存在了string sHtmlJs这个字符串变量里,我们需要把eval这里执行的结果提取出来,把eval替换成 return,然后把整个代码放到一个JS函数里,方式如下:

解密后的代码如下:

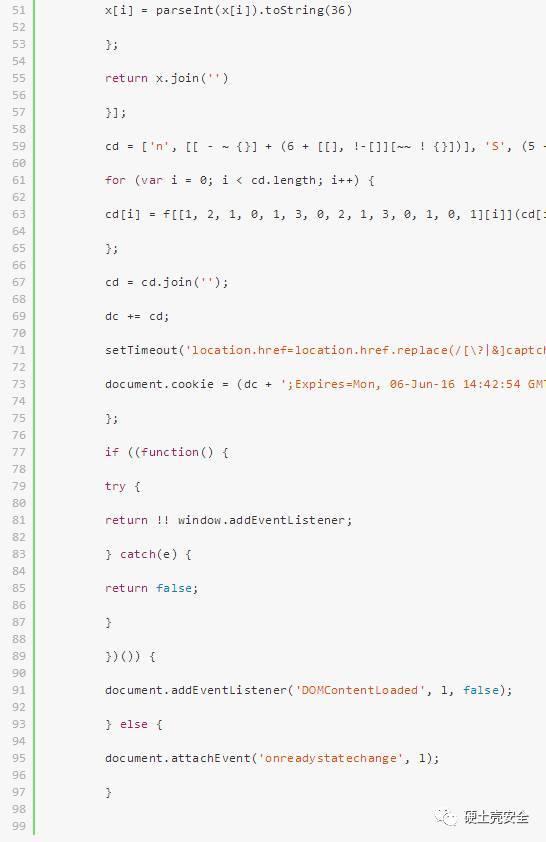
通过观察代码发现了一段:
显而易见,这个dc就是我们想要的cookie,执行JS,让函数返回DC就OK了。
我还发现了其中有一段

当服务器发现浏览器的头部是_phantom或者__phantommas就让浏览器进行死循环,即阻止用selenium操控phantomjs来访问网页。
至此两端加速乐cookie如下:

这个破解方法很麻烦不建议用,所以我想出了第二种方法
第二种办法就是通过selenium的webdriver模块控制浏览器自动访问网页然后输出浏览器头部信息中的cookie,封装在一个字典中,将其通过requests中的jar模块转换成cookiejar放入下一次访问的request中就可以持续访问,因为cookie的时效大约一个小时左右。
以下是处理自动生成一个新的有效cookie的代码:

切记,放在requests中访问的headers信息一定要和你操控的浏览器headers信息一致,因为服务器端也会检查cookies与headers信息是否一致
最厉害的武功是融会贯通,那么最厉害的反爬策略也就是组合目前有的各种反爬手段,当然也不是无法破解,这就需要我们对各个反爬技术及原理都很清楚,梳理清楚服务器的反爬逻辑,然后再见招拆招,就可以让我们的爬虫无孔不入。
谢谢阅读!