前言
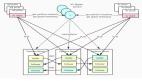
分布式存储是近几年的热门话题之一,它和传统SAN/NAS存储的区别是,分布式存储使用标准硬件(比如x86服务器和10GbE网络),而传统SAN/NAS存储使用的是专有硬件。使用标准硬件的好处是通用,不会受限于产商,而且成本上也更便宜,还可以做到按需扩容。
存储系统有一大铁则,即非不可抗力情况下不能发生数据丢失,亦即要求数据可靠一致——这往往也被称之为存储系统的生命线或底线。分布式存储因物理结构跟传统存储的不同,会有不一样的实现数据高可靠的方法。本文就这个话题做一些初步探讨。
在进一步之前,我们先来明确一下概念,本文中所说的“分布式存储”,是指采用标准x86服务器和网络互联,并在其上运行相关存储软件的系统。近几年云计算是热门之一,“云存储”也是大家常见的名词。在国内云计算平台常见的就是OpenStack,而云存储往往是指结合OpenStack使用的分布式存储,如Ceph、GlusterFS或Sheepdog等。
除了“云计算”和“云存储”之外,ServerSAN也是近几年热点之一,它和“云存储”概念上比较接近,也是通过一组x86服务器互联,并对外提供传统SAN-like的存储接口。国内几个涉足ServerSAN的厂商,也是通过包装Ceph等分布式存储系统对外提供产品或服务的。
缘起
为了提供数据可靠性,分布式存储系统一般通过数据存储多个副本(一般是3个副本)或者EC(本质上也是副本)来实现。比如用户存储一个txt文档,在底层分布式存储系统中,这份文档会被存储3个副本,并放置在不同故障域的不同硬盘上。这样即使损坏一块硬盘,数据不会丢失。即使同时损坏不同故障域的两块硬盘,数据仍然不会丢失。不过在硬盘损坏后,存储系统一般会及时感知并补全丢失的副本。
多副本带来了数据的可靠性,同时也带来了一致性方面的问题。比如给定数据A的三个副本A1、A2和A3,如何能保证它们的内容是一致的。如果内容不一致,往往代表出现了问题。比如:
- A1内容:hello world
- A2内容:hello wor
- A3内容:hello w
假设A1是用户真正写入的数据,如果A1突然损毁,此时即使有A2、A3两个副本在,数据仍然发生了丢失。
“承诺”和“遵守”
那么如何保证副本间的数据一致性?
首先,先确定合法的数据。这里的关键词是“承诺”。比如用户要写入“hello world”,数据通过网络发给存储系统,在存储系统没有反馈之前,用户不能确定写入是否成功,更不能假设写入已经成功。只有当存储系统反馈给用户“你的hello world写入成功”之后 ,数据才算写入成功 —— 这里称之为“承诺”,即底层分布式存储系统承诺数据已经写入,且由多副本机制保护,不会出现错乱或丢失,用户能够读到自己之前写入的数据。
其次,分布式存储系统要遵守“承诺”。在反馈写入成功之后,即使发生部分副本硬件损坏,也不能发生数据丢失。如果出现上述例子中A1损坏,则就是数据丢失,因为余下A2、A3的数据都是跟“承诺”不一样的。
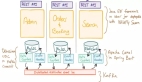
如何做到“遵守”,是分布式存储系统的核心之一。我们举例说明这个问题,以Ceph为例,数据写入请求最终是要发送给三个副本,不过Ceph为这三个副本建立了一主两从的主从关系,数据会单独发送给主副本,再由主副本转达给另外两个从副本。另外数据在三个副本节点上写入的时候,都会先以直写方式写入本地Journal,然后再以非直写的方式写入数据盘。
这里有两个疑问:
1. 为什么采用“一主两从”这样的主从模式?
2. 为什么要写Journal?
先讨论***个问题“为什么采用主从模式”。首先主副本作为一个结果收集点和用户反馈人。三个副本写入的结果如何,需要有人统一汇总、处理并反馈给用户。如果用户自己来收集和处理,则相当于副本机制侵入到了用户的业务逻辑中,明显不合理。如果另外使用一个专门的节点Cordinator作为中心协调人,三个副本写入的结果都先反馈给Cordinator,再由Cordinator处理和反馈给用户,这样缺点之一是IO路径上多了Cordinator这一跳,则增加了每次IO的耗时。缺点之二是增加了物理资源投入。缺点之三是如果Cordinator故障后,三个副本群龙无首,且Cordinator的重新选取将面临各种不便。
如果使用主从模式,三个副本一主两从,首先避免了上面提到的缺点之一和缺点之二。对比上述缺点之三,主从模式下主副本故障之后,重新选主会更自然轻松。
再讨论第二个问题“为什么要写Journal”。Ceph中“臭名昭著”的double write现象,正是因为写Journal引起的。数据副本在写入时,要求先以直写方式写入Journal,然后再以非直写方式写入文件。如此成本高昂,却仍不得不为之,正体现了Ceph存储系统对数据可靠这一生命线的尊重。因为Ceph Journal的主要作用类似于数据库中的WAL(Write Ahead Log),提供数据写入的原子性,避免故障时造成无法回溯的中间数据。
不过,进一步思考,会产生新的疑问。Journal能避免故障时产生中间数据,即使用Journal之后,数据写入要么完全成功,要么完全失败,不会部分成功。但我们仍然不能判定故障恢复后,副本数据分别是处于“完全成功”还是“完全失败”。Ceph是通过pglog来决定的,pglog由主副本生成并在副本间同步的,它包含了本次数据写入的版本号,并也会被持久化到Journal中。因此故障后副本会比较数据中的版本信息和Journal中的版本信息,由此判定是“完全成功”还是“完全失败”,为集群级别的故障恢复流程提供明确的输入。
综上所述,“遵守”“承诺”并非易事,从其中可见Journal至关重要,没有Journal的分布式存储系统,其数据一致性都将存疑。
结语
本文尝试从日常思维的角度,简述多副本机制的必要性和带来的数据一致性挑战,并举例Ceph如何应对这个挑战。不过说来容易做来难,分布式存储系统中,编程实践也尤为重要。