运维发展历程与工业革命异曲同工,工业的三次革命分别是机械化、电气化与信息化,运维则是原始手工、脚本与自动化工具。那么工业4.0悄然来临的今天,智能化又将会给运维带来哪些影响?坦白讲,AIOps是新概念,目前并没有准确且广泛使用的定义,对AIOps的认知也会随实践、反思和讨论的不断积累发生演变。但AIOps所指代的整体趋势是毋庸置疑的,智能化将逐步走进IT行业乃至社会生活的各个方面。
今天, 由51CTO 主办的第十六期以“Tech Neo”为主题的技术沙龙活动如期举行,此次沙龙邀请了来自陌陌科技SRE团队负责人王景学、去哪儿网DevOps工程师叶璐和ThoughtWorks高级咨询师顾宇。希望讲师们这些基于平台、建站、深度学习等不同方式的自动化运维实践经验,多少可以为运维/开发人员带来一些的新思路。
自动化运维与 DevOps”沙龙现场
陌陌在k8s容器方面的实践
首位演讲的是王景学老师,主要分享陌陌在k8s容器方面的实践和应用迁移方面的一些经验。当时陌陌选用k8s进行实践的主要原因是,应用发布时间过长、紧急扩容吃力,效率低且应用运行环境软件版本不一致,配置复杂,维护成本比较高,硬件资源利用率不高,总体成本比较高。

k8s方面的设计目标有五点,分别是:提高服务的可用性,可管理性、使用k8s来管理docker集群、开发不需要关心服务器、提高资源隔离性,实现服务混合部署,应用级别基础资源监控,服务平滑迁移等。针对这些问题和目标,通过自研发布系统,基于docker和k8s的容器管理平台,便于开发者便捷地部署自己的应用程序。
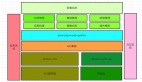
如下图,是K8s架构
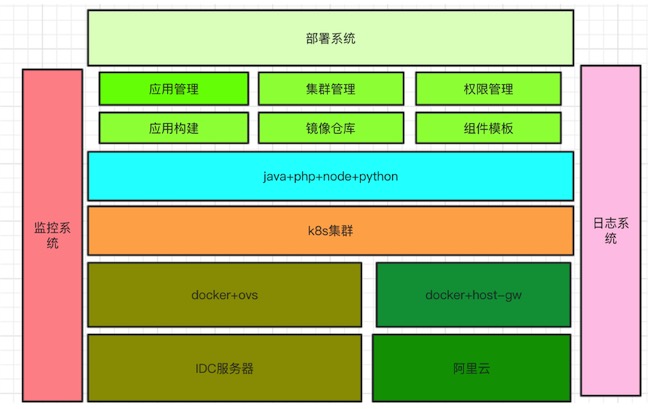
针对K8s架构,王景学老师还分享了基于location和group标签的集群调度、基于ovs的网络节点架构和实现、集群在阿里云扩展和支持,测试环境中有状态应用的尝试、容器基础资源监控方面的指标等,还有在应用迁移过程中,遇到了Swap、cpu软中断及资源利用率,应用白名单等问题。
于未来,希望可以实现对应用请求量,线程数,流量等指标的监控。基准值部分,达到单实例可承载请求量,线程数,流量。伸缩方面,做到最小保留实例数,最大扩容实例数,根据监控反馈和基准值计算需要扩容和缩容的实例数, 按照各个集群资源余量按比例伸缩。
去哪儿网基于Kubernetes/Ceph的机器学习云实践
第二位演讲者是有丰富云平台建设、运维、容器云落地等经验的叶璐老师,演讲的主题是去哪儿网基于Kubernetes/Ceph的机器学习云实践。

叶璐老师以深度学习的兴起为演讲开端,这要涉及深度学习的概念、兴起的原因、深度学习加速器-GPU等方面的内容。紧接着分享了深度学习在Qunar的应用,像智能客服,拿去花用户信用评级,酒店推荐等都是经典实践。
演讲最核心的部分是如何应对GPU使用资源的一系列问题,如环境无隔离、采购周期长、 资源利用率低、各种工具的环境部署成本高等。
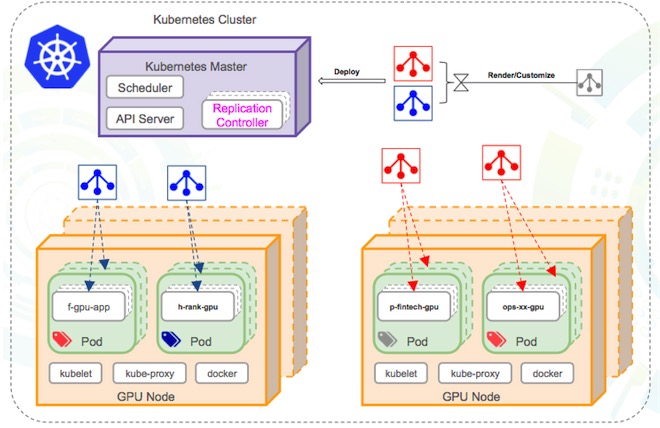
针对这些问题,去哪网采用的方式是构建GPU云,第一期的目标是GPU资源云化, 持业务线同学快捷定制机器学习应用,秒建秒删,一键释放GPU资源,建立统GPU 资源申请和管理等入口到Portal,降低业务线同学的接入和学习成本。做到环境隔离同时保证训练数据在分布式环境下的持久化和可靠性,以及支持Tensorflow全工具链。
如下图,是机器学习应用的一种部署情况
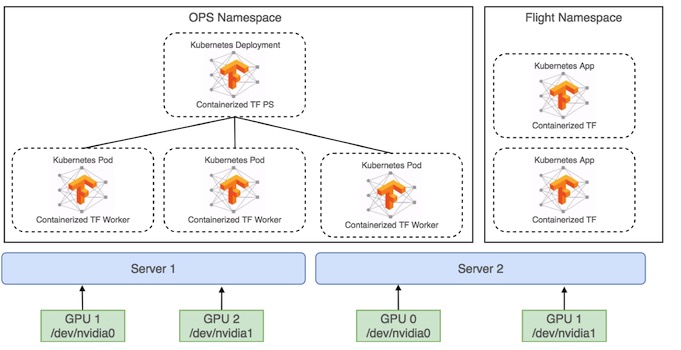
叶璐表示,目前一期已经完成正在公测中,使用前后对比,在环境秒起秒删、环境隔离给开发同学提供极大的便利。在对接Ceph后,数据的可用性和可靠性大大提升,不用担心因为更换机器带来的训练数据迁移,丢失。
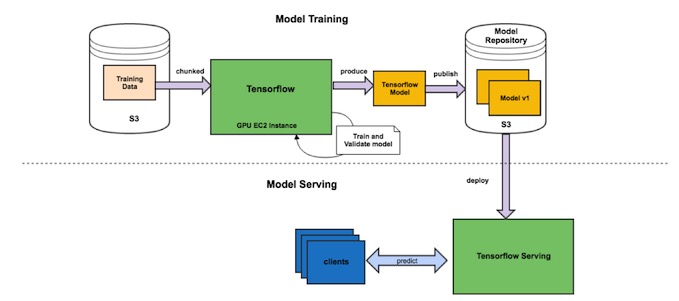
GPU云基础环境固化,让开发同学免受环境安装之苦是第一步。现在Spectrum第二期也在开发中,开发工程师随时固化到Kubernetes Post-Install,提供了更高的环境定制自由度;同时Tensorflow serving的上线,为机器学习应用真正落地提供了更完整的pipeline,同时还有其他的优化,上下游的数据获取管道,预处理流程优化,Jupyter插件系统集成。
用基础设施即代码自动化架构迁移
最后一位演讲人是专注于 DevOps、持续交付,微服务以及全功能产品团队的设计、实践、落地以及经验推广的顾宇老师。他的演讲主题是用基础设施即代码自动化架构迁移。

演讲由一个真实的架构迁移案例展开,分享了在一个东南亚互联网企业并购案例中的 DevOps 的实施案例。通过在 AWS上使用 Ansible 和 CloudFormation作为基础设施即代码的工具实现产品架构的迁移。
在互联网企业的并购过程中,不光是组织结构的融合,更是产品架构和产品团队的融合。然而在不同的企业文化、技术能力甚至是不同的国家法律法规上的融合更多的是看不到的隐形成本。
通过 DevOps 的基础设施即代码实践,把架构以及开发/运维实践固化为配置和代码。让所有的团队和成员能够依照同样的规则进行开发和运维。通过自动化的手段加速团队和产品和架构的融合过程,提升整个组织的技术水平。
首先,根据康威定理,组织和架构和基础设施架构要保持一致,就可以根据未来的组织结构设计系统架构,可以减少系统架构演进中的适应性浪费。
其次,把整个架构分层次封装:基础设施、应用和数据 三种类型分别进行封装:
- 基础设施通过配置管理技术封装在 Ansible 的 Playbook里,把 Ansible 作为 Cloudformation的引擎。
- 应用通过 Docker 镜像进行封装,根据不同的地区在构建过程中进行合并。
- 数据通过自动化的备份脚本和自动化的迁移脚本(Migration Scripts)实时保证可用性。
然后,根据使用场景,设计基础设施即代码的架构。能够自动的把整个架构自动的搭建和还原。根据使用场景设计安全策略,避免人为操作,减少人为故障。
顾宇老师表示,基础设计即代码和基础设施是类和对象的关系。根据不同的场景,可以采用面向对象原则进行逻辑分层。隔离不同场景的关注点。例如:持续交付关注Docker 镜像的部署和变更,应用维护关注日志的查询和操作。
最后在该案例中,顾宇老师总结了利用基础设施即代码技术的几个关键要点:
- 架构迁移要为组织结构迁移服务
- 把自动化和基础设施即代码当做制度使用(康威定理和逆定理)
- 把基础设施即代码当做一个产品开发
- 安全的架构和架构的安全
- 基础设施逻辑分层基础设施即代码本质上是一套类库,从面向对象的原则考虑基础设施的设计。
- 构建每日可用架构
活动结束时,现场很多开发者还意犹未尽,围着诸位老师就自动化运维的部署、迁移等方面问题,进行探讨交流。
随智能化在各个应用领域的落地及实践,IT运维也将迎来一个智能化运维的新时代。让我们共同见微知著、未雨绸缪,当机器能越来越智能地工作,我们也要变得越来越聪明。
51CTO Tech Neo技术沙龙是51CTO在2016年开始定期组织的IT技术人员线下交流活动,目前仅限北京地区,周期为每月1次,每期关注一个话题,范围涉及大数据、云计算、机器学习、物联网等多个技术领域。