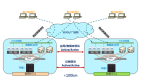
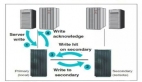
存储跨中心双活最关键、最难点就是链路质量,如何把控该风险?
双中心间通讯不可控问题:一是链路稳定状况不可控;二是IO延时指标不可控。这些不可控因素非常容易造成灾难性影响,轻则导致数据库读写性能灾难,重则导致数据库节点直接处于僵死状态。另外,链路的不稳定会导致存储链路频繁切换,甚至会导致集群仲裁频繁发生,这对于业务连续性更是一个灾难。
解析和解答
邓毓 某农信社资深骨干工程师
无论什么双活,只要上升到了跨中心的层面,就必然需要跨中心的链路作为双活的通讯介质。这个通讯不但要求高可用性和冗余度,而且又对通讯质量要求又很高。并且链路所带来的风险隐患又是巨大的,中断或者响应时间高都将可能导致双活集群发生脑裂仲裁,出于保护的目的,将IO HANG住一段时间,将所有没有落入磁盘的数据全部刷盘,才继续在某个存活的站点继续恢复读写访问。所以阻碍存储跨中心双活技术发展的最直接的因素就是双中心间链路不可控。尤其对风险、稳定性要求苛刻的金融机构来说,更加不敢轻易做跨中心的双活。所以链路成为了存储双活的最难点,如何既提高链路稳定性,又保证链路的性能,还又有合理的故障保障机制,是每一个存储厂商和企业用户都要深思的关键点。
在这里我也不刻意去解决该难题,而是提出些许我的想法。
1.链路冗余度
通常我们企业做双活,都是自己购买波分设备,然后租用运营商的裸光纤,作为通讯的链路。所以波分设备需要冗余,裸光纤也要冗余,波分设备好办,购买即可。裸光纤通常租用两家或两家以上的运营商线路,比如电信和联通,电信的裸光纤也需要冗余,联通的裸光纤也需要冗余,防止单根裸光纤意外割断或者损坏。然而单家运营商的裸纤都通常在一个弱点井中,一起意外割断的事情常有,所以需要两家运营商互相冗余。这两家运营商裸纤的路线还不能一致,弱电井需要在不同的街道,并且分别走不同的路线到达目的地。所以可以看到,由于我们是租用,根本不可能要求运营商完全达到你的要求,***的方式只能自建,成本太高,好像根本不现实。
示意图:
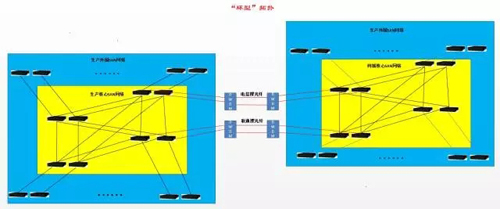
2.链路质量
链路质量包括光衰、抖动和带宽等。一方面,光衰和抖动无法控制,只能靠波分设备去探测,发现光衰和抖动,立即中断该链路,切向备链路,这对后端的SAN网络无感知,但对波分设备的要求很高,需要购买和建设时注意。至于带宽,可以监测,达到带宽预警阈值后,可向运营商申请提升带宽。另一方面,对于链路质量的监测机制一定要在建设存储双活或者其他双活之前建立,由于是运营商的链路,链路经过了多少中继、多少设备我们是不得知的,我们只能在波分端建立有效的监测机制,有些波分设备也有专门的监控软件支持。而且也要要求和运营商建立监测联动机制,运营商监测到链路质量(是质量而不是中断)有问题,也需要***时间告知,做出合理的决策。
3.存储双活控制器的机制
由于跨中心的双活控制器间的通讯是实时的,完整写周期必须两个站点的控制器都完成写操作。他们间的通讯又是靠链路完成的,链路质量和链路中断都将导致性能波动甚至超时,对于中断,控制器的处理机制都还不错,对于质量,控制器的处理机制往往不够,需要长时间的尝试,才会做出合理的决策,甚至没有决策,导致上层数据库或者应用磁盘IO超时,而异常挂起甚至宕机。所以这个机制是决定好的双活体系的重要因素,有时候宁可立即放弃一边,也要保住RTO,但目前为止我还未发现双活存储控制器有好的链路质量处理机制。知道的也请分享。
4.双活存储上端的OS、应用和数据库合理的超时参数
OS识别磁盘、应用访问文件系统、数据库访问裸设备或者文件系统,存储IO HANG住,将导致层层超时,尤其是数据库,超时将彻底中断宕机,甚至出现逻辑损坏等莫名奇妙的问题。有时候超时响应慢是可以等,而不是中止,所以需要OS、数据库层进行合理的超时联动设置。
5.尽量避免跨站点读,减少跨站点写频率
没有跨站点读,就意味着本地可读,对链路质量没有要求;减少跨站点写频率,就意味着,性能影响弱化,被控制器、数据库、操作系统等层层缓存暂存的写数据,会减少跨站点写的次数,进一步弱化链路质量所会带来的影响。