最近发现越来越多的歌曲下载都需要缴费了,对维护正版是好事。但有的时候也想钻个空子,正好最近在学习python,随手写了一个建议爬虫,用来爬取某播放软件的在线音乐。
主要思路就是爬取播放页里的播放源文件的url,程序可以读取用户输入并返回歌单,,,因为在线网站包含大量js,requests就显得很无奈,又懒得手动解析js,于是寄出selenium大杀器。
selnium是一款很强大的浏览器自动化测试框架,直接运行在浏览器端,模拟用户操作,目前selenium支持包括IE,Firefox,Chrome等主流浏览器及PhantomJS之类的无头浏览器,selenium+phantomjs也是现在很火的一个爬虫框架。
代码不长,做的有些简陋,以后可以加个GUI。。。。
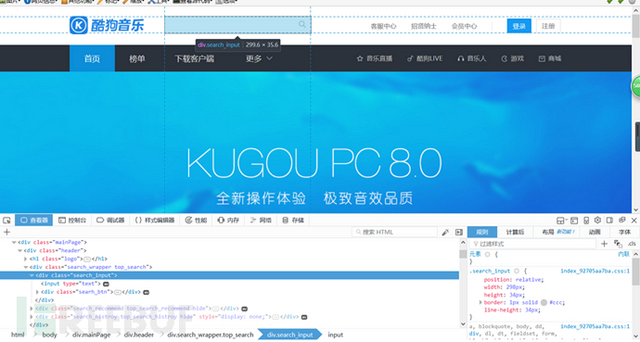
步骤一:
进入酷狗主页,F12查看元素,,通过selenium.webdriver的send_keys()方法给send_input类传参,即用作用户的输入,然后通webdriver.click()方法点击搜索按钮,得到搜索结果列表。这里会有一个js重定向,通过webdriver.current_ur就可以了,,切记一点!传入的参数需要经过unicode编码(.decode(‘gb18030′))效果一样),否则如果有中文会乱码。。(来自被深深困扰的我)
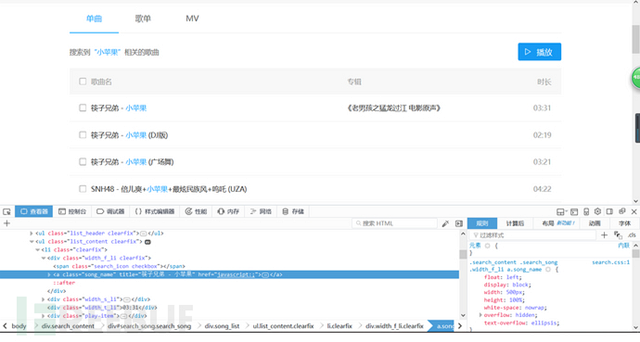
步骤二:
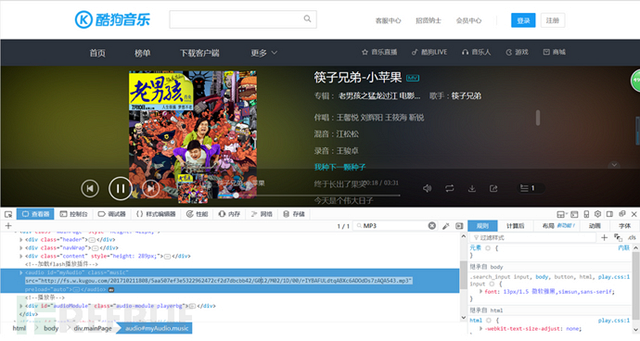
查看元素里每首歌的路径,发现每首歌的路径只有<li>不同,于是通过对li的迭代来获取每一首歌的xpath,并输出歌曲名字的元素,然后依旧通过webdriver的click()方法点击歌曲链接,得到歌曲播放页面,这里没有什么难点,都是常规操作。需要注意的是,这里的歌曲链接也包含一个js的重定向,但不一样的是浏览器会打开一个新的页面(至少火狐会),可以在click()方法后通过webdriver.switch_to_window()方法跳转到新打开的页面
步骤三:
进入播放页面后通过xpath找到播放源文件链接(强推firepath,xpath神器啊)但发现这里依然有一个js渲染,来生成播放源链接,直接提取<src>标签会显示为空,于是继续webdriver,调用的浏览器会自动解析js脚本,解析完成后提取<src>得到歌曲链接,使用urllib的urlretrueve()下载即可
代码如下:
- #coding=utf-8
- from selenium.webdriver.remote.webelement import WebElement
- from selenium import webdriver
- from selenium.webdriver import ActionChains
- from selenium.common.exceptions import NoSuchElementException
- from selenium.common.exceptions import StaleElementReferenceException
- from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
- from selenium.webdriver.common.by import By
- import time
- import urllib
- #歌曲名
- mname = ''
- #JS重定向
- def wait(driver):
- elem = driver.find_element_by_tag_name('html')
- count = 0
- while True:
- count += 1
- if count > 20:
- print('chao shi le')
- return
- time.sleep(.5)
- try:
- elem == driver.find_element_by_tag_name('html')
- except StaleElementReferenceException:
- return
- #获取url
- def geturl():
- input_string = raw_input('>>>please input the search key:')
- driver = webdriver.Chrome()
- url = 'http://www.kugou.com/'
- driver.get(url)
- a=driver.find_element_by_xpath('html/body/div[1]/div[1]/div[1]/div[1]/input') #输入搜索内容
- a.send_keys(input_string.decode('gb18030'))
- driver.find_element_by_xpath('html/body/div[1]/div[1]/div[1]/div[1]/div/i').click() #点击搜索
- result_url = driver.current_url
- driver.quit()
- return result_url
- #显示搜索结果
- def show_results(url):
- driver = webdriver.Chrome()
- driver.get(url)
- time.sleep(3)
- for i in range(1,1000):
- try:
- print '%d. '%i + driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%i).get_attribute('title') #获取歌曲名
- except NoSuchElementException as msg:
- break
- choice = input(">>>Which one do you want(you can input 'quit' to goback(带引号)):")
- if choice == 'quit': #从下载界面退回
- result = 'quit'
- else:
- global mname
- mname = driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%choice).get_attribute('title')
- a = driver.find_element_by_xpath(".//*[@id='search_song']/div[2]/ul[2]/li[%d]/div[1]/a"%choice)
- actions = ActionChains(driver)
- actions.move_to_element(a)
- actions.click(a)
- actions.perform()
- #wait(driver)
- driver.switch_to_window(driver.window_handles[1]) #跳转到新打开的页面
- result = driver.find_element_by_xpath(".//*[@id='myAudio']").get_attribute('src') #获取播放元文件url
- driver.quit()
- return result
- #下载回调
- def cbk(a, b, c):
- per = 100.0 * a * b / c
- if per > 100:
- per = 100
- print '%.2f%%' % per
- def main():
- print'***********************欢迎使用GREY音乐下载器********************************'
- print' directed by GreyyHawk'
- print'**************************************************************************'
- time.sleep(1)
- while True:
- url = geturl()
- result = show_results(url)
- if result == 'quit':
- print'\n'
- continue
- else:
- local = 'd://%s.mp3'%mname
- print 'download start'
- time.sleep(1)
- urllib.urlretrieve(result, local, cbk)
- print 'finish downloading %s.mp3'%mname + '\n\n'
- if __name__ == '__main__':
- main()
效果:

总结:
当网页包含大量js的时候,selenium就会非常的方便,但经过实践发现好像phantomjs解析js的效率没有世纪浏览器的高,还会出错,后来换成调用火狐就好了,,不知道为啥,,也许是脸黑吧,,总之selenium真的是一款非常强大的框架,对爬虫有兴趣的同学一定要了解一下。