自容器推出以来,它给软件开发带来了极具传染性的振奋和创新,并获得了来自各个行业、各个领域的巨大的支持——从大企业到初创公司,从研发到各类 IT 人员等等。
知名跨境电商平台小红书随着业务的铺开,线上部署单元的数量急剧增加,以 Jenkins 调用脚本进行文件推送的部署模式已经不能适应需求。
本文介绍小红书如何以最小的投入,最低的开发量快速的实现容器化镜像部署,以及由此带来的收益。
图 1
小红书是一个从社区做起来的跨境电商,目前已经有 5 千万的用户,电商平台的 SKU 已经上到了十万级。用户喜欢在我们的平台上发布关于生活、健身、购物体验、旅游等相关帖子,每日有 1 亿次笔记曝光。
我们从社区里的用户创建的笔记生成相关的标签,关联相关商品,同时在商品页面也展示社区内的和这商品有关的用户笔记。
小红目前还处在创业阶段,我们的技术团队规模还不大,当然运维本身也是一个小团队,团队虽小,运维有关的技术方面却都得涉及。
小公司资源有限,一个是人力资源有限,二是我们很多业务往前赶。在如何做好 CI/CD,怎么务实的落地方面,我们的策略就是开源优先,优先选择开源的产品,在开源的基础上,发现不满足需求的地方再自行开发。
小红书应用上线流程
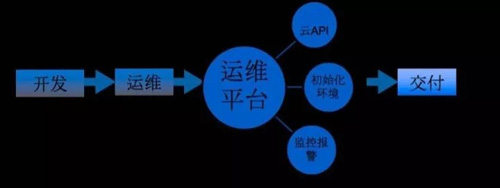
图 2
如图 2 是之前应用上线的过程,开发向运维提需求,需要多少台服务器,运维依据需求去做初始化并交付给开发。
我们现在有一个运维平台,所有服务器的部署都是由这个平台来完成,平台调用腾讯云 API 生成服务器,做环境初始化,配置监控和报警,最后交付给开发的是一个标准化好的服务器。

图 3
开发者拿到服务器准备线上发布时,采用 Jenkins 触发脚本的方式:用 Jenkins 的脚本做测试,执行代码推送。
当需要新加一台服务器或者下线一台服务器,要去修改这个发布脚本。发布流程大概是:Jenkins 脚本先往 Beta 环境发布,开发者在 Beta 环境里做自测,自测环境没有问题就全量发布。
我们遇到不少的情况都是在开发者自测的时候没有问题,然后在线上发,线上都是全量发,结果就挂了。
回退的时候,怎么做呢?只能整个流程跑一遍,开发者回退老代码,再跑一次 Jenkins 脚本,整个过程最长需要 10 来分钟,这段过程线上故障一直存在,所以这个效率很低。
以上的做法其实是大多数公司的现状,但是对于我们已经不太能适应了,目前我们整个技术在做更迭,环境的复杂度越来越高。
如果还是维持现有的代码上线模式,显然会有失控的风险,而且基于这样的基础架构做例如自动容量管理等,都是很难做到的。
技术团队的问题与需求
首先,我们整个技术团队人数在增加,再加上技术栈在变。以前都是纯 Python 的技术环境,现在不同的团队在尝试 Java、Go、Node。
还有就是我们在做微服务的改造,以前的单体应用正在加速拆分成各个微服务,所以应用的数量也增加很多。
拆分微服务后,团队也变得更细分了,同时我们还在做前后端的拆分,原来很多 APP 的页面是后端渲染的,现在在做前后端的拆分,后端程序是 API,前端是展示页面,各种应用的依赖关系也变得越来越多。
再加上电商每年大促销,扩容在现有模式也很耗时耗力。所以现在的模式已经很难持续下去。
我们团队在两三个月以前就思考怎么解决这些问题,怎么把线上环境和代码发布做得更好一点。我们需要做如下几点:
- 重构“从代码到上线”的流程。
- 支持 Canary 发布的策略,实现流量的细颗粒度管理。
- 能快速回退。
- 实践自动化测试,要有一个环境让自动化测试可以跑。
- 要求服务器等资源管理透明化,不要让开发者关心应用跑在哪个服务器上,这对开发者没有意义,他只要关心开发就可以了。
- 要能够方便的扩容、缩容。
快速实现容器化镜像部署的方法
我们一开始就考虑到容器化,就是用 Kubernetes 的框架做容器化的管理。
为什么是容器化?因为容器和微服务是一对“好朋友”,从开发环境到线上环境可以做到基本一致。
为什么用 Kubernetes?这和运行环境和部署环境有关系,我们是腾讯云的重度用户,腾讯云又对 Kubernetes 提供了非常到位的原生支持。
所谓原生支持是指它有如下几个方面的实现:
- 网络层面,Kubernetes 在裸金属的环境下,要实现 Overlay 网络,或者有 SDN 网络的环境,而在腾讯云的环境里。它本身就是软件定义网络,在网络上的实现可以做到在容器环境里和原生的网络一样的快,没有任何的性能牺牲。
- 在腾讯云的环境里,负载均衡器和 Kubernetes 里的 service 可以捆绑,可以通过创建 Kubernetes 的 service 去维护云服务的 L4 负载均衡器。
- 腾讯云的网盘可以被 Kubernetes 管理,实现 PVC 等,当然 Kubernetes 本身提供的特性是足够满足我们的需求的。

图 4
我们作为创业公司都是以开源为主,在新的环境里应用了这样的一些开源技术(图 4),Jenkins、GitLab、Prometheus 和 Spinnaker。Jenkins 和 GitLab 大家应该都听说过,并且都在用,Prometheus、Docker 也都是目前很主流的开源产品。
这里重点介绍两个比较新,现在相当火的开源技术:
- Spinnaker,这是一个我个人认为非常优秀的开源的发布系统,它是由 Netflix 在去年开源的,是基于 Netflix 内部一直在使用的发布系统做的开源,可以说是 Netflix 在 CD 方面的最佳实践,整个社区非常活跃,它对 Kubernetes 的环境支持非常好。
- Traefik,在我们的环境里用来取代 Nginx 反向代理,Traefik 是用 Go 写的一个反向代理服务软件。
01.Spinnaker
Spinnaker有如下几个特点:
Netflix 的开源项目。Netflix 的开源项目在社区一直有着不错的口碑。
有开放性和集成能力。它原生就可以支持 Jenkins、GitLab 的整合,它还支持 Webhook,就是说在某一个环境里,如果后面的某个资源的控制组件,本身是个 API,那它就很容易整合到 Spinnaker 里。
拥有较强的 Pipeline 表达能力。它的 Pipeline 可以复杂到非常复杂,Pipeline 之间还可以关联。
有强大的表达式功能。可以在任何的环节里用表达式来替代静态参数和值,在 Pipeline 开始的时候,生成的过程变量都可以被 Pipeline 的每个 stage 调用。
比如说这个 Pipeline 是什么时候开始的,触发时的参数是什么,某一个步骤是成功还是失败了,此次要部署的镜像是什么,线上目前是什么版本,这些都可以通过变量访问到。
界面友好,支持多种云平台。目前支持 Kubernetes、OpenStack、亚马逊的容器云平台。
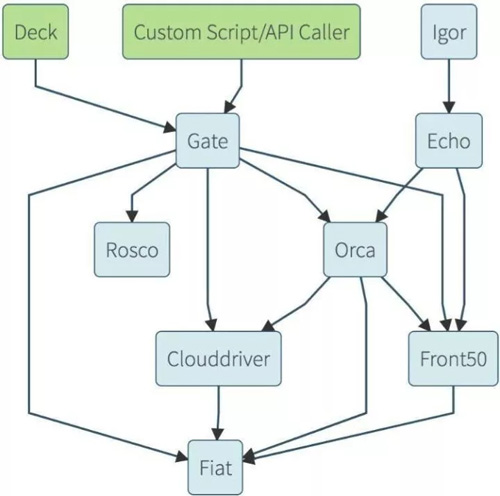
图 5
图 5 是 Spinnaker 的架构,它是一个微服务的架构,里面包含用户界面 Deck,API 网关 Gate 等。
API 网关是可以对外开放的,我们可以利用它和其他工具做一些深度整合。Rosco 是它做镜像构建的组件,我们也可以不用 Rosco 来做镜像构建。Orca 是它的核心,就是流程引擎。
Echo 是通知系统,Igor 是用来集成 Jenkins 等 CI 系统的一个组件。Front52 是存储管理,Cloud driver 是它用来适配不同的云平台的,比如 Kubernetes 就有专门的 Cloud driver,也有亚马逊容器云的 Cloud driver。Fiat 是它一个鉴权的组件。
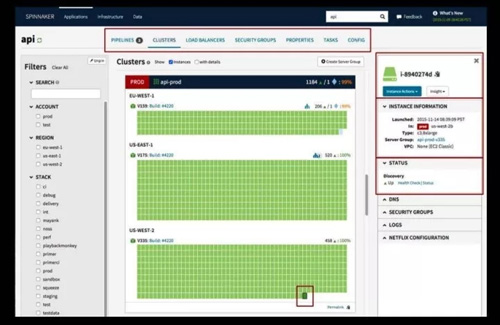
图 6
图 6 是 Spinnaker 的界面,界面一眼看上去挺乱,实际上它还是有很好的逻辑性。
这里每一个块都有三种颜色来表示 Kubernetes 环境里的某个实例的当前状态。绿色代表是活着的实例,右边是实例的信息,包括实例的 YML 配置,实例所在的集群,实例的状态和相关 event。
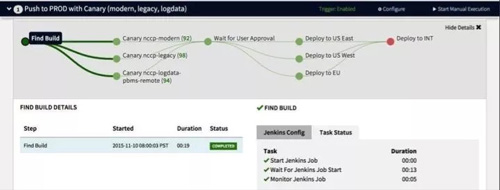
图 7
图 7 是 Pipeline 的界面。首先,我觉得这个界面很好看很清晰。二是 Pipeline 可以做得非常灵活,可以在执行了前几个步骤之后,等所有的步骤执行完了再执行某个步骤。
这个步骤是某个用户做某个审批,再分别执行三个步骤其中的一个步骤,然后再执行某个环节。也可以发布还是回退,发布是走发布的流程,回退就是回退的流程。
总之在这里,你所期待的 Pipeline 的功能都可以提供,如果实在不行,还有 Webhook 的模式让你方便和外部系统做整合。
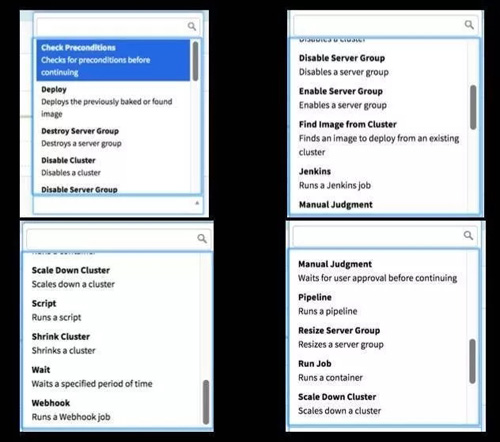
图 8
图 8 是 Pipeline 步骤的类型。左上 Check Precondltions 前置条件满足的时候才执行某个步骤。
例如当前面的第一次发布里所有的实例都存活的时候,才执行某个步骤。或者当前面的步骤达到了某个状态,再执行下一个步骤。
Deploy 是在 Kubernetes 环境里生成的 Replication Set,可以在 Deploy 里更新一个服务器组、禁用一个集群、把集群的容量往下降、往上升等等。
也可以跑某一个脚本,这个脚本是在某一个容器里,有时候可能有这样的需求,比如说 Java,这个 Java 跑起来之后并不是马上能够接入流量,可能要到 Java 里跑一个 job,从数据库加载数据并做些初始化工作后,才开始承接流量。
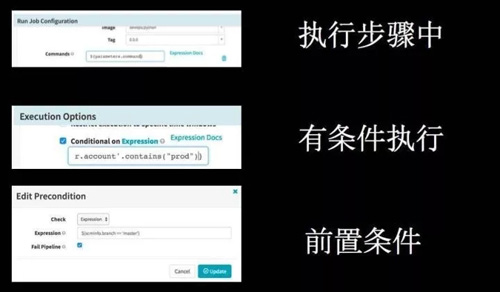
图 9
Pipeline 表达式很厉害,它的表达式是用 Grovvy 来做的。Grovvy 是一个动态语言,凡是 Grovvy 能用的语法,在有字符串的地方都可以用。
所以,这些步骤中,可以说这个步骤参数是来自表达式;也可以说有条件的执行,生成环境的时候才做这样的东西;也可以有前置条件,当满足这个条件的时候,这个流程和 stage 可以继续走下去。
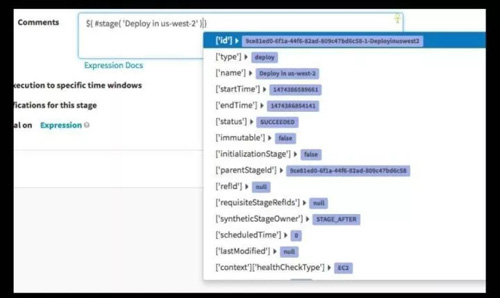
图 10
如图 10 是各种类型的表达式,从现在来看,基本上各种需求我们都能满足了。
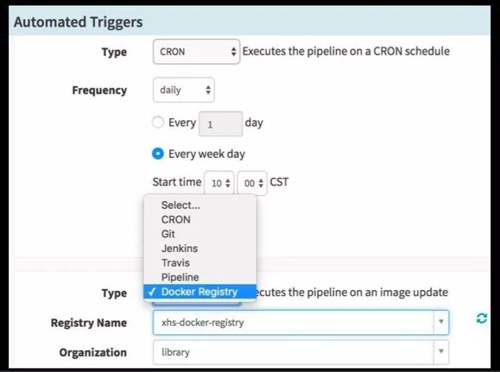
图 11
Pipeline 可以自动触发(图 11),可以每天、每周、每月、每年,某一天的时候被自动触发,做一个自动发布等等;也可以在镜像有新 tag 推送到镜像仓库时,Pipeline 去做发布。
02.Spinnaker 和 Kubernetes 的关系

图 12
Spinnaker 和 Kubernetes 有什么关系?它有很多概念是一对一的,Spinnaker 有一个叫 Account 的,Account 对应到 Kubernetes 是 Kubernetes Cluster。
我们的环境里现在有三个 Kubernetes 的 Cluster,分别对应到开发、测试和生产,它也是对应到 Spinnaker 的 三个 Account;Instance 对应到 Kubernetes 里是 Pod,一个 Pod 就是一个运行的单元。
还有 Server Group,这个 Server Group 对应的是 Replica Set 或者是 Deepionment。然后是 Load Balance,在 Spinnaker 里称之为 Load Balance 的东西在 Kubernetes 里就是 Service。
03.Traefik
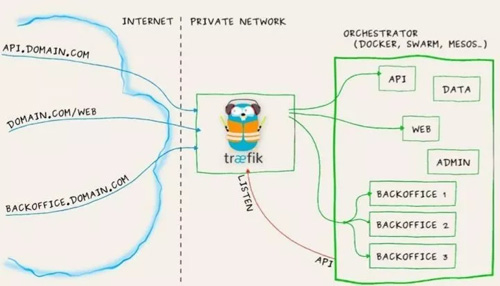
图 13
Traefik 的几个亮点:
- 配置热加载,无需重启。为什么我们用 Traefik 而不用 Nginx 做反向代理呢?首先 Traefik 是一个配置热加载,用 Nginx 时更新路由规则,做后端服务器的上线、下线都需要重载,但 Traefik 不需要。
- 自带熔断功能。Traefik 自带熔断功能,可以定义后端某个实例错误率超过比如 50% 的时候,主动熔断它,请求再也不发给它了。
traefik.backend.circuitbreaker:NetworkErrorRatio() > 0.5
- 动态权重的轮询策略。它会记录 5 秒钟之内所有后端实例对请求的响应时间或连接数,如果某个后端实例响应特别慢,那接下来的 5 秒钟就会将这个后端的权重降低,直到它恢复到正常性能,这个过程是在不断的调整中,这是我们需要的功能。
traefik.backend.loadbalancer.method:drr
因为上了容器之后,我们很难保证一个应用的所有实例都部署在相同处理能力的节点上,云服务商采购服务器也是按批量来的,每一批不可能完全一致,很难去保证所有的节点性能都是一致的。
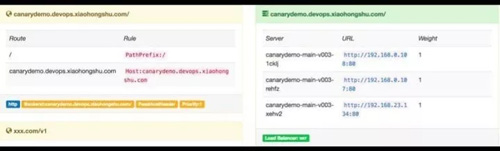
图 14
图 14 是 Traefik 自带的界面。我们定义的规则,后端实例的情况都可以实时的展现。
04.为什么在 Kubernetes 环境里选择了 Traefik?
Traefik 和 Kubernetes 有什么关系呢?为什么在 Kubernetes 环境里选择了 Traefik?我们总结了如下几点:
- Kubernetes 集群中的 Ingress Controller。Traefik 在 Kubernetes 是以 Ingress Controller 存在,大家知道 Kubernetes 到 1.4 之后就引进了 Ingress 的概念。
Kubernetes 原来只有一个 Service 来实现服务发现和负载均衡,service 是四层的负载均衡,它做不到基于规则的转发。
- 动态加载 Ingress 更新路由规则。在 Kubernetes 里 Ingress 是属于七层 HTTP 的实现,当然 Kubernetes 本身不去做七层的负载均衡,它是通过 Ingress Controller 实现的,Traefik 在 Kubernetes 里就是一种 Ingress Controller。
- 根据 Service 的定义动态更新后端 Pod。它可以动态加载 Kubernetes 里的 Ingress 所定义的路由规则,Ingress 里也定义了一个路由规则所对应的 Service,而 Service 又和具体的 Pod 相关。
- 根据 Pod 的 Liveness 检查结果动态调整可用 Pod。Pod列表是根据 Pod 的 Liveness 和 Readiness 状态做动态的调整。
- 请求直接发送到 Pod。Traefik 据此可以将请求直接发送给目标 Pod,无需通过 Service 所维护的 iptables 来做转发。
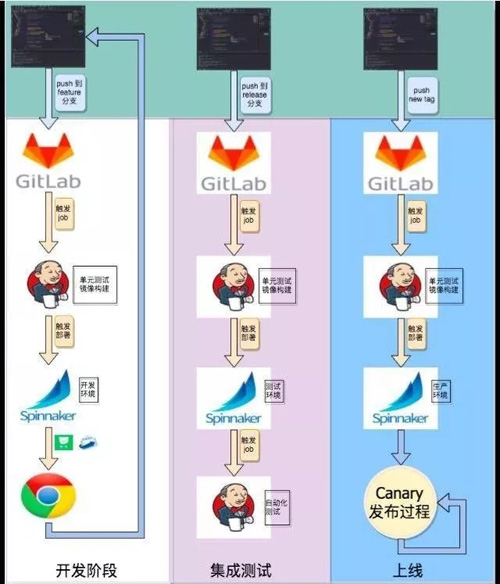
图 15
图 15 是新发布的一个流程或者是开发的流程。我们有如下三个环节:
- 开发阶段。
- 集成测试。
- 上线。
开发阶段,开发者在迭代开始时生成一个 Feature 分支,以后的每次更新都将这个 Feature 分支推送到 GitLab 。
GitLab 里配置的 Webhook 触发一个 Jenkins job,这个 job 做单元测试和镜像构建,构建成一个 Feature 分支的镜像,给这个镜像一个特定的 tag。生成新的镜像之后,触发 Spinnaker 的部署,这个部署只在开发环境里。
开发者怎么访问刚刚部署的开发环境呢?如果这是个 HTTP 应用,假设应用叫做 APP1,而分支名称叫 A,那开发者就通过 APP1-A.dev.xiaohongshu.com 就可以访问到 Feature A 的代码。
在整个周期里可以不断的迭代,最后开发者觉得完成了这个 Feature 了,就可以推送到 release。一旦把代码推往 release 就触发另一个构建,基本上和前面的过程差不多。
最后会有一个自动化的测试,基本上是由测试团队提供的自动化测试的工具,用 Spinnaker 调用它,看结果是什么样。
如果今天很有信心了,决定往生产发了,可以在 Git 上生成一个 tag,比如这个 tag 是 0.1.1,今天要发 0.1.1 版了,同样也会触发一个镜像的构建。
这三个不同的阶段构建的镜像 tag 不一样,每生成一个新 tag, Spinnaker 会根据 tag 的命名规则触发不同的 Pipeline,做不同环境的部署。
05.Canary
最重要的是我们有一个 Canary 的发布过程,我们在 Spinnaker 的基础上,开发了一套 Canary 的机制。
Canary 和 Beta 差不多,但 Canary 是真实引入流量,它把线上用户分为两组:
- 稳定版的流量用户。
- Canary 版的用户。
他们会率先使用新版本,我们的具体策略是先给公司、先给我们自己办公室的人来用,这个灰度如果没问题了,用户反馈 OK,看看监控数据也觉得没有问题,再按照 1%-10%-20%-50%-100% 的阶段随机挑选线上用户继续灰度。
在这整个过程都有监控数据可以看,任何时候如果有异常都可以通过 Spinnaker 进行回退。
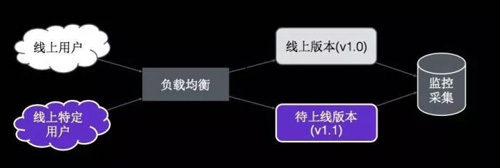
图 16
这个是 Canary 的示意图,线上用户被分成两组,大部分用户访问老版本,特定用户通过负载均衡转发到特定的版本里,后台有监控数据方便去比较两个版本之间的差异。
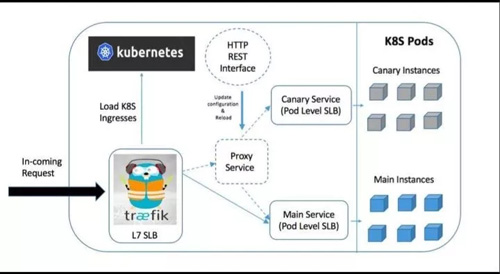
图 17
这是我们在容器环境里实现的 Canary 的架构(图 17),用户请求从前面进来,首先打到 Traefik,如果没有做 Canary 的过程,Traefik 是直接把请求打到组实例。
如果要发布一个新的版本,有一个 HTTP 的 API 控制 project service,决定把什么样的流量可以打到这个里面版本。
我们的策略可能是把办公室用户,可以通过 IP 看到 IP,或者把线上的安卓用户,或者线上 1% 的安卓用户打给它,这些都是可以定义的。
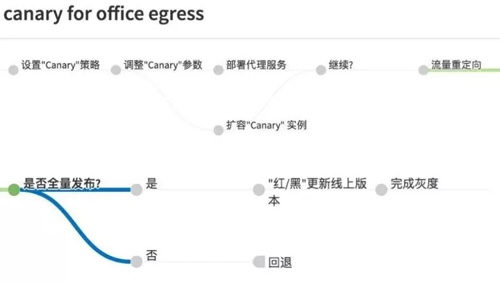
图 18
如图 18 所示是线上真实的部署流程。首先是要设置一个 Canary 策略,这个策略可以指定完全随机还是根据用户的特定来源。
比如说是一个办公室用户,或者所有上海的用户等等,然后去调整参数,是 1% 的上海用户,还是所有的上海用户。
然后开始部署服务,接下来把这个 Canary 实例做扩展,在流量进来之前,实例的容量一定要先准备好。
进来之后把流量做重新定向,把流量从原来直接打给后端的 Pod 改成打到 Canary 代理服务上,由 Canary 代理服务根据策略和用户来源做进一步的流量分发。
整个过程不断的迭代,有 1% 的线上用户开始慢慢到达 100%。在达到 100% 后,就采用红黑的策略替换掉所有旧版本:先把所有的新版本实例生成出来,等所有的新版本通过健康检查,都在线了,旧的版本再批量下线,这样完成一个灰度。
如果中途发现问题不能继续,马上就可以回退,所谓的回退就是把流量打回到线上版本去。

图 19
如上图(图 19)是我们的 Canary 策略。这是我们自己实现的一套东西,图中的例子是把来自指定网段一半的 iPhone 用户进行 Canary。
用户分组的维度还可以有其他规则,现在我们支持的是完全随机/特定 IP/特定设备类型,这些规则可以组合起来。
我们的用户分组是有一致性保证的,一旦为某个用户分组了,那在当前灰度期间,这个用户的分组不会变,否则会影响用户体验。
未来发展
我们下一步打算做两件事情:
- 做自动灰度分析,叫 ACA,现在 AIOps 概念很热门,自动灰度分析可以说是一个具体的 AIOps 落地。
在灰度的过程中,人肉判断新版本是否正常,如果日志采集够完整的话,这个判断可以由机器来做,机器根据所有数据来为新版本做评分,然后发布系统根据评分结果自动继续发布或者终止发布并回退。
- 再往下可以做自动的容量管理,当然是基于 Kubernetes 的基础上,做自动容量管理,以便更好的善用计算资源。
最后总结一下:一个好的 CD 系统应该能够控制发布带来的风险;我们在人力资源有限的情况下倾向于采用开源的方法解决问题,如果开源不满足的话,我们再开发一些适配的功能。
孙国清
小红书运维团队负责人
浙大计算机系毕业,曾在传统企业 IT 部门工作多年,最近几年开始在互联网行业从事技术及技术管理工作,曾就职于携程基础架构,负责 Linux 系统标准化及分布式存储的研究和落地,目前在小红书带领运维团队,负责业务应用、基础架构以及IT支持。个人接触的技术比较杂,从开发到运维的一些领域都有兴趣,是 Scala 语言的爱好者,曾翻译了“The Neophyte's Guide to Scala”,有上千 Scala 开发者从中受益,到小红书后开始负责系统化落地 DevOps 和提高运维效率。