58 私有云平台是 58 同城架构线基于容器技术为内部服务开发的一套业务实例管理平台。
它支持业务实例按需扩展,秒级伸缩,平台提供友好的用户交互过程,规范化的测试、上线流程,旨在将开发、测试人员从基础环境的配置与管理中解放出来,使其更聚焦于自己的业务。
本文和大家分享在私有云平台实施过程中的相关容器技术实践,主要从以下三个部分来进行讨论:
- 背景:当前存在哪些问题,为什么使用容器技术。
- 整体架构:整个容器技术的架构方案。
- 核心模块的设计方案:一些核心模块的选型决策与解决方案。
为什么使用容器技术
在没有用容器化技术之前,我们存在这些问题:
01资源利用率问题
不同业务场景对资源的需求是不一样的,有 CPU 密集型、内存密集型、网络密集型,这就可能导致资源利用率不合理的问题。比如,一个机器上部署的服务都是网络密集型,那么 CPU 资源和内存资源就都浪费了。
有些业务可能只聚焦于服务本身而忽略机器资源利用率的问题。
02混合部署交叉影响
对于线上服务,一台机器要混合部署多个服务,那么服务之间可能存在相互影响的情况。
比如,一个服务由于某些原因突然网络流量暴涨,可能把整个机器的带宽都打满,那么其他服务就会受到影响。
03扩/缩容效率低
当业务节点需要进行扩/缩容时,从机器下线到应用部署、测试,周期较长。当业务遇到突发流量高峰时,机器到手部署后,可能流量高峰已经过去了。
04多环境代码不一致
由于过去内部开发流程的不规范,存在一些问题,业务提测的代码在测试环境测试完毕后,在沙箱可能会进行修改、调整,然后再打包上线。
这就会导致测试的代码和线上运行的代码是不一致的,增加了服务上线的风险,也增加了线上服务故障排查的难度。
05缺少稳定的线下测试环境
在测试过程中,会遇到一个问题,服务依赖的其他下游服务都没有提供稳定的测试环境。
这导致无法在测试环境模拟整个线上流程进行测试,所以很多测试同学会用线上服务进行测试,这里有很高的潜在风险。

为了解决上述问题,架构线云团队进行了技术选型与反复论证,最终决定使用 Docker 容器技术。
58 私有云整体架构
58 私有云的整体架构如下图:
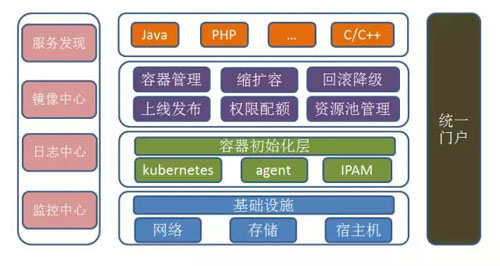
01基础设施
整个私有云平台接管了所有的基础设施,包括服务器、存储和网络等资源。
02容器层
基础设施之上提供了整个容器初始化层,容器初始化层包含 Kubernetes、Agent、IPAM;Kubernetes 是 Docker 的调度和管理组件。
Agent 部署在宿主机上,用于系统资源和底层基础设施的管理,包含监控采集、日志采集、容器限速等。IPAM 是 Docker 的网络管理模块,用于管理整个网络系统的 IP 资源。
03资源管理
容器层之上是资源管理层,包含容器管理、缩扩容、回滚降级、上线发布、配额管理、资源池管理等模块。
04应用层
运行用户提交的业务实例,可以是任意编程语言。
05基础组件
私有云平台为容器运行环境提供必备的基础组件,包含服务发现、镜像中心、日志中心、监控中心。
06服务发现
接入云平台的服务提供统一的服务发现机制,便捷业务接入云平台。
07镜像中心
存储业务镜像,分布式存储,可弹性扩展。
08日志中心
中心化收集业务实例日志,提供统一的可视化入口,方便用户分析与查询。
09监控中心
汇总全部的宿主和容器监控信息,监控视图化,报警定制化,为智能化调度提供基础。
10统一门户
可视化的 UI 门户页面,规范化整个业务流程,简洁的用户流程,可动态管理整个云环境的所有资源。
全新的架构带来全新的业务流转方式:
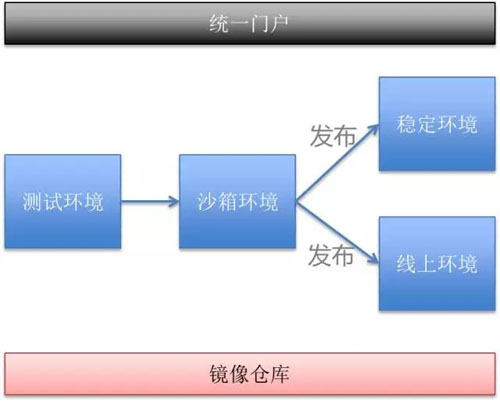
平台定义了四套基础环境:
- 测试环境:测试人员进行功能测试,对接到线下环境。
- 沙箱环境:程序预发布环境,对接到线上环境。
- 线上环境:提供服务的线上环境。
- 稳定环境:运行在线下环境的实例,为其他上游服务提供稳定的测试环境实例。
业务基于 SVN 提交的代码构建镜像,镜像的整个生命周期就是在 4 个环境中流转。因为是基于同一个镜像创建实例,所以可以保证测试通过的程序与线上运行的程序是完全一致的。
核心模块的设计方案
开发 58 私有云平台需要考虑很多细节,这里主要和大家分享下其中的五个核心模块:
- 容器管理。
- 网络模型。
- 镜像仓库。
- 日志收集。
- 监控告警。
有了这几个核心模块,平台就有了基础框架,可以运转起来。
01容器管理
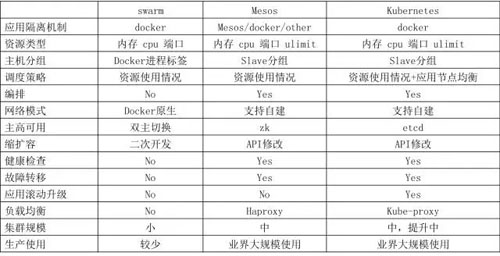
我们调研的基于 Docker 的管理平台主要有三个:Swarm、Mesos、Kubernetes,通过对比,我们最终选择了 Kubernetes。
Swarm 功能过于简陋,所以最早就 pass 了,Mesos + Marathon 是一个成熟的解决方案,但是社区不够活跃,而且使用起来要熟悉两套框架。
Kubernetes 是专门针对容器技术提供的调度管理平台,更专一,社区非常活跃,配套的组件与解决方案较多,使用它的公司也越来越多,通过和一些公司沟通,他们也在逐步的将 Docker 应用从 Mesos 迁移到 Kubernetes 上。
下面表格为我们团队关注点的一些对比情况:
02网络模型
网络模型是任何云环境都必须面对的问题,因为网络规模一旦扩大之后,会带来各种问题。网络选型这块,针对 Docker 和 Kubernetes 的特性,对六种组网方式进行了对比,如下所示:
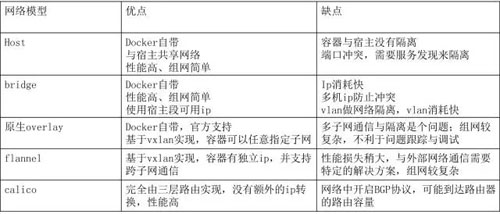
针对每种网络模型,云团队都做了相应的性能测试,Calico 除外,因为公司所用的机房不支持开启 BGP 协议,所以没有进行测试。
iPerf 测试网络带宽结果如下:
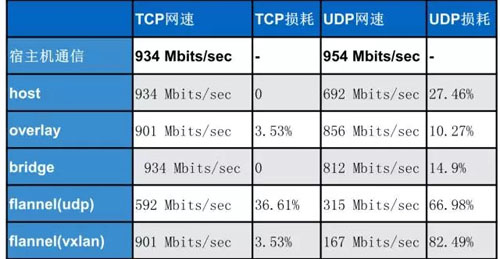
Qperf 测试 TCP 延迟结果如下:
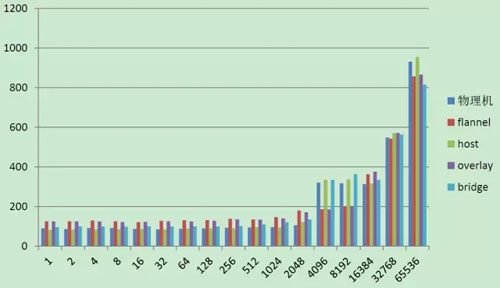
Qperf 测试 UDP 延迟结果如下:
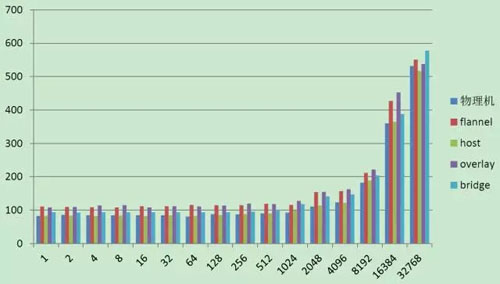
通过测试结果可以看出:Host 模式和 Bridge 模式性能与宿主机是最接近的,其他组网模式还是有一些差距的,这和 Overlay 的原理有关。
私有云平台最终选择了 Bridge + VLAN 的组网方式,原因如下:
- 性能较好,组网简单,可以与现有网络无缝对接;可以很好的实现容器与容器、容器与宿主互通。
- 故障易于调试,传统的 SA 即可解决;适应任意物理设备,可大规模扩展。
- 公司内部服务之间都是基于 RPC 协议,有自己的服务发现机制,可以很好的兼容;现有内部框架改动小。
由于 VLAN 最多有 4096 个,所以 VLAN 是有个数限制的,这也是为什么会有 VLAN 的原因。
在云平台当前的网络规划中,VLAN 是够用的,未来随着使用规模的扩大,技术的发展,我们也会深入研究更合适的组网方式。
网上也有同学反馈 Calico 的 IPIP 模式网络性能也很高;但是考虑到 Calico 当前的坑比较多,需要有专门的网络组来支撑,而这块是云团队所欠缺的,所以没有深入调研。
这里还有一个问题,默认的使用 Bridge 模式是每个宿主机配置不同网段的地址,这样就可以保证不同宿主机上为容器分配的 IP 不冲突,但是这样也会导致出现大量的 IP 浪费。
机房的内网环境 IP 资源有限,没有办法这样配置网络,所以只能开发 IPAM 模块进行全局的 IP 管理。
IPAM 模块的实现参考了开源项目 Shrike 的实现,将可分配的网段写入 etcd 中,Docker 实例启动时,会通过 IPAM 模块从 etcd 中获取一个可用 IP,在实例关闭时,会对 IP 进行归还,整体架构如下所示:

另外,由于 Kubernetes 不支持使用 CNM,所以我们针对 Kubernetes 源码进行了修改。网络方面还有一个点需要考虑:就是网络限速。
03镜像仓库
Docker 的镜像仓库使用官方提供的镜像仓库,但是后端提供的存储系统我们进行选型,默认的存在本地磁盘的方式是无法应用到线上系统的。具体的选型如下:
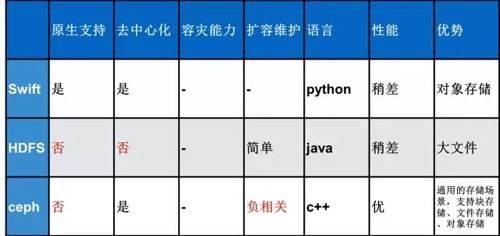
通过对比,可以看出 Ceph 是最合适的,但是最终云团队选择使用 HDFS 作为镜像仓库的后端存储,原因如下:
- Swift 是官方默认提供支持的存储类型,但是搭建一套 Swift 并保证其稳定运行需要专人深入研究,由于人员有限所以暂没使用,Ceph 也是基于同理没有进行选择。
- HDFS 系统公司有专门的数据平台部门在管理和维护,他们更专业,云团队可以放心的将 Docker 镜像托管到 HDFS 上。
但是 HDFS 本身也存在一些问题,比如压力大时,NameNode 无法及时响应,未来我们会考虑将后端存储迁移到架构线部门内部自研的对象存储中,以提供稳定高效的服务。
04日志系统
传统服务迁移到容器环境,日志是一个大问题。因为容器即用即销,容器关闭后,容器的存储也会被删除。
虽然可以把容器中的日志导出到宿主机上的指定位置,但是容器会经常漂移,在排查故障时,我们还需要知道历史上的某一时刻,某个容器在哪台宿主机上运行,并且由于使用方没有宿主机的登陆权限,所以使用方也没法很好的获取日志。
在容器环境下,需要新的故障排查方式。这里,一个通用的解决方案就是采用中心化的日志解决方案,将零散的日志统一进行收集存储,并提供灵活的查询方式。
私有云平台采用的方案如下:

使用方在管理门户上配置要采集的日志,私有云平台通过环境变量的方式映射到容器中,宿主机上部署的 Agent 根据环境变量获取要采集的日志,启动 Flume 进行采集。
Flume 将日志统一上传到 Kafka 中,上传到 Kafka 中的日志保证严格的先后顺序。
Kafka 有两个订阅者,一个将日志上传到搜索服务中,供管理门户查询使用;一个将日志上传到 HDFS 中,用于历史日志的查询和下载,使用方也可以自己编写 Hadoop 程序对指定日志进行分析。
05监控告警
资源的监控和报警也是一个云平台必不可少的部分。针对容器的监控有很多成熟的开源软件可供选择,58 内部也有专门的监控组件,如何更好的监控,云团队也进行了相应的选型。

最终,云团队选择使用 WMonitor 来作为容器的监控组件,因为 WMonitor 本身集成了物理机和报警逻辑,我们不需要再做相对应的开发,只需要开发容器监控部分的组件,并且针对内部的监控需求,我们可以很好的进行定制。
Heapster + InfluxDB + Grafana 是 Kubernetes 官方提供的监控组件,规模小时用它也没有问题,但是规模大时使用它可能会存在问题,因为它是轮询获取所有节点监控信息的。
后记
以上内容是 58 同城架构线针对容器技术如何落地进行的相关探索,很多技术选型无关优劣,只选择适合 58 相关应用场景的。整个云平台要解决的技术点有很多,这里选取了其中几个关键的点和大家进行分享。