存储跨数据中心双活的方案更是双活数据中心架构方案中最重要且最艰难的一项,为了帮助企业IT架构师理清和解决存储跨中心双活方案架构的难点,twt社区特别组织线上交流,邀请专家逐一对难点进行解析和解答。
存储跨中心双活方案设计阶段如何尽量降低对整体性能的影响?
性能影响问题:因为双活系统在写入数据时,会写两次数据,尤其是通过复制功能写到远端存储的过程,传输链路的性能也会影响整体性能。在选型设计阶段该如何解决该难点?尽量降低对整体性能的影响?
解析和解答
邓毓 某农信社资深骨干工程师
这个问题实际上存储双活不可避免要遇到的问题,相比单存储直接提供读写来说,存储双活一定会增加读写响应时间,更别说存储还是跨两个不同数据中心的,随着距离的增加,理论上每增加100KM,会增加1ms的RTT(往返延迟时间),通常单个IO总耗时在1-3ms左右,就会认为单个存储I/O处理处于比较高性能的模式,如果加上其他因素,如“数据头处理”和“并发”,1ms的“理论”延时增加的影响会成倍增加,将原本处于高性能模式的IO响应时间拉高,对应用或者数据库来说,“变慢”了。所以存储双活的初衷是只是为了高可用性和提高总体并发、吞吐量,并不是为了降低读写响应时间。那么我们在设计、选型存储双活方案时,就需要考虑如何尽量降低双活的存储所带来的性能降低影响。
我们先来看看一些存储双活方案的读写流程:
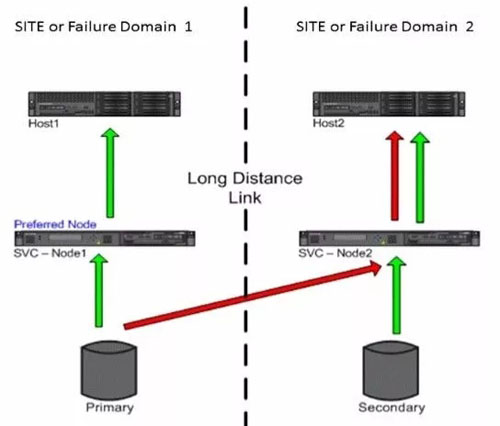
(1)IBM SVC Enhanced Stretch Cluster(ESC)和HDS GAD等
IBM SVC ESC和HDS GAD的读写方式都很类似,这里就放在一起来看。
SVC ESC:
HDS GAD:
读:
ESC和GAD在两个存储拉开到两个数据中心,形成AA模式的架构,对于读来说,是两个数据中心分别对各自中心的存储本地读,这样读来说不存在跨站点的RTT,读性能跟单存储是一样的。
写:
某数据中心的写操作会先写到本地控制节点缓存,然后再跨站点同步至另一控制节点缓存中,并原路返回,告诉主机写操作完成,等到缓存达到一定的水位时,再刷入各自底层存储当中,这时的写操作存在1倍的跨站点RTT。当两个数据中心都要对某一数据块写操作时,会先在缓存表对应的数据块中加锁,并同步锁信息至对端缓存表,实现双活存储的写并发。所以写也是本地写的方式,性能跟单存储比是降低的。
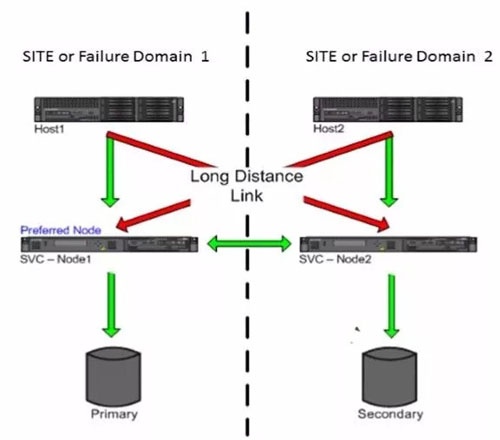
(2)SVC HyperSwap
SVC HyperSwap的HyperSwap卷有master和aux之分,读写复杂度也高很多,master卷所在站点的主机读写是本地读本地写,而aux卷所在站点的主机读写方式是转发模式。
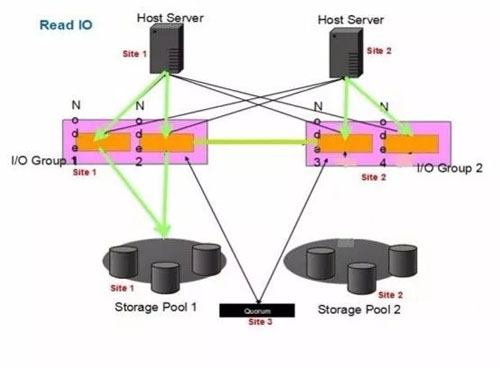
假设初始化后,Site1的卷为Master卷,Site2的卷为Aux卷
读:
Site1读I/O
1.主机向SVC I/O Group1的任意一个节点发送读请求
2.SVC I/O Group1将该请求传至Storage Pool1
3.Storage Pool1响应请求,并将数据传至SVC I/O Group1
4.SVC I/O Group1将数据结果传至主机
Site2读I/O
1.主机向SVC I/O Group2的任意一个节点发送读请求
2.SVC I/O Group2将该请求转发至SVC I/O Group1
3.SVC I/O Group1将请求传至Storage Pool1
4.Storage Pool1响应请求,并将数据传至SVC I/O Group1
5.SVC I/O Group1将数据回传给SVC I/O Group2
6.SVC I/O Group2将数据结果传至主机
所以可以看到AUX卷所在站点的主机需要跨站点读对端存储,存在1倍的RTT,而MASTER卷所在的主机读IO和单存储性能相差无几。
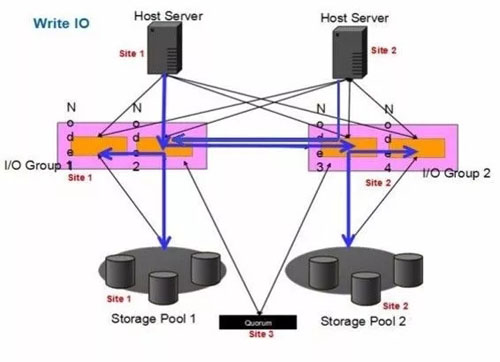
写:
Site1写I/O
1.主机向Site1的其中一个SVC节点2发送写I/O请求
2.该SVC节点2将写I/O写入缓存
3.该SVC节点2将写I/O同步至节点1缓存,并同时通过MM发送写I/O至站点2的节点3和节点4
4.SVC节点1、3、4陆续回复节点2的写响应
5.SVC节点2回复主机写响应
6.两个站点的SVC节点分别将缓存写入各自站点的存储当中
Site2写I/O
1.主机向Site2的其中一个SVC节点3发送写I/O请求
2.该SVC节点3将写I/O转发至Site1的任意SVC节点2
3.SVC节点2将写I/O写入缓存
4.该SVC节点2将写I/O同步至节点1缓存,并同时通过MM发送写I/O至站点2的节点3和节点4
5.SVC节点1、3、4陆续回复节点2的写响应
6.SVC节点2回复SVC节点3的转发响应
7.SVC节点3回复主机的写响应
8.两个站点的SVC节点分别将缓存写入各自站点的存储当中
同理,AUX卷所在站点的主机需要跨站点写对端存储,并且回写AUX卷底层存储,总共存在2倍的RTT,而MASTER卷所在的主机写IO和单存储性能相差无几。
所以很明显,SVC HYPERSWAP的SVC节点是跨站点双活,而存储则为ACTIVE-STANDBY。
(3)NetApp MCC
MCC的双活方式实际上是两个数据中心的存储互为镜像,各自提供不同的存储服务。
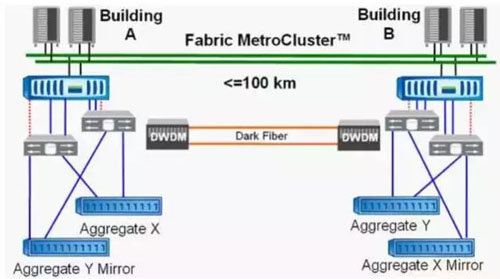
对于AGGX来说,为站点A的主机提供本地读和本地写,并通过集群节点的NVRAM写日志同步至站点B,维持数据一致性,也是等到日志达到水位线,刷入底层存储当中。
对于AGGY来说,也是类似,为站点B的主机提供本地读和本地写,并同步NVRAM的写日志至站点A。MCC通过这种方式实现两个站点存储的双活,MCC集群节点也是双活,但对于某一应用主机来说,实则只在一个站点活动。
性能方面,MCC的读性能和单存储类似,写性能存在1倍的RTT。
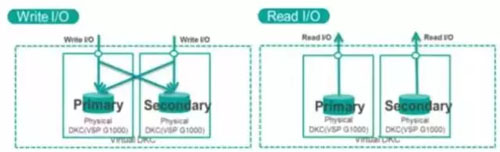
(4)SVC Vplex Metro
Vplex Metro和其他三种方式都不一样,是一种分布式的存储双活/多活架构。Vplex没有写缓存,有了分布式缓存,标榜为access anywhere
没有写缓存就意味了,主机对VPLEX的写是透写模式,主机的写IO只是经过VPLEX的虚拟化直接落入到底层存储,并在分布式缓存目录表中记录这个写IO是通过哪个VPLEX引擎写入的。当需要对该数据块进行读操作时,先是在分布式缓存目录中查找数据块是通过哪个VPLEX引擎写入的,然后再通过本地的VPLEX引擎转发该读请求至上一次写入该数据块的VPLEX引擎,通过它来读取它后端的存储,最终原路返回。另外,对于写入的IO,透穿过VPLEX写底层存储时,还将同步一份IO副本至另一VPLEX引擎的底层存储。
所以可以看到,对于某数据中心VPLEX的读操作来说,如果刚好上次该数据块的写操作时也是发在该VPLEX中,那么读是本地读,亲和性好。如果刚好上次该数据块的的写操作不是在该VPLEX,那么就需要跨站点进行读操作,亲和性弱,存在1倍的跨站点RTT;对于写,都是本地写,只不过需要将该写IO同步至另一站点的底层存储,也存在1倍的跨站点RTT。
好了,写了这么多,将几种主流的存储双活架构的读写操作流程写清楚了。简单对比如下:

归根到底,我们最想要的存储跨中心双活,就是为了让两个数据中心的主机对存储的读写,尽量本地读和本地写,或者本地读,减少跨中心写。这是“尽量降低对整体性能的影响”的最直接的方法!
首先是读写比例问题,不能将读写比例过小的应用放到双活存储系统中。
再是距离对读写RTT的放大问题,读写响应时间越敏感,距离越不能过远。
***是想尽办法,减少跨中心写,这里有很多办法,比如通过数据库的分库分表,将应用分割至两个站点,热点数据分离;增大缓冲池,尽量减少直接的写存储操作等。