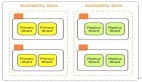
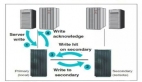
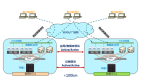
近年来,作为灾备方案中高级别的双活数据中心解决方案逐渐成为了应对传统灾备难题的一把利剑,它能够解决传统的灾备方案中资源利用率低、可用性差、出现故障时停机时间长、数据恢复慢、风险高等问题,但同时也带来了很多难点问题。这其中,存储跨数据中心双活的方案更是双活数据中心架构方案中最重要且最艰难的一项,能否在方案架构选型和设计阶段,顺利地解决和尽量规避这些存储双活的难点问题,对企业IT架构师团队的能力有着极大的考验。
为了帮助企业IT架构师理清和解决存储跨中心双活方案架构的难点,IT架构师和存储专家整理出一些方案设计中较为典型的难点,并特别组织线上交流,邀请专家逐一对这些难点进行解析和解答。
这些难点将包括:
脑裂风险问题、性能影响问题、数据一致性风险问题、双中心间通讯不可控问题、数据同步逻辑错误问题、存储网络故障泛滥问题、集群仲裁一致性问题、存储多路径控制的策略问题、存储双活后的集群保护问题、私有云存储解决方案相结合的问题等。
突破存储跨中心双活方案设计阶段难点(一):脑裂风险
存储跨中心双活方案设计阶段该如何尽量避免脑裂?
如何避免脑裂是每个双机系统都要重视的问题,存储双活系统尤其如此,脑裂会带来长时间的存储读写IO HANG住,轻则导致业务性能下降,重则因磁盘IO超时,导致数据库挂起甚至宕机,对生产业务系统造成重大影响。所以在存储跨中心双活架构设计时,究竟应该如何尽量避免脑裂?
解析和解答:
邓毓 某农信社资深骨干工程师
数据中心脑裂简单说就是两个数据中心间的网络和存储链路同时发生中断,导致两个数据中心内的应用、数据库或者操作系统同时抢占和利用共享的资源,造成资源的数据不一致,产生重大影响。
这个问题是存储跨中心双活方案设计、实施阶段不可避免要遇到的问题。各个存储厂商、存储虚拟化产品厂商都有自己的避免脑裂的方式:
(1)IBM SVC ESC/HYPERSWAP 或者IBM V9000/V7000/V5000 HYPERSWAP
对于上述存储双活方案架构来说,呈现的是一种对称式的整体架构,为了防范脑裂,仲裁站点是必需的。在仲裁站点中,基于IP的quorum节点和物理quorum磁盘都可以提供脑裂的仲裁服务,存储双活集群最多能够拥有3个物理quorum磁盘,也可以选择最多5个基于IP的quorum节点,这个基于IP的quorum节点可以是任何站点的任何服务器,或者公有云的一个虚拟机,在这个服务器内运行一个简单的仲裁JAVA程序即可。所以可以看到,基于IP的仲裁服务其实大大提高了仲裁站点的选择空间,节省了企业双活建设成本,只要求IP可达,延时在80MS内即可。
但是,只有物理quorum磁盘的仲裁方式才能够被用来做T3 Recovery,所有的SVC节点都会将节点的相关信息同步至该物理quorum磁盘,当节点或者集群出现故障时,可以通过该物理quorum磁盘进行T3 Recovery
在SVC集群中有一个概念configuration node---配置节点,是配置SVC集群后,系统自动产生的保存着所有系统配置行为的节点,不能人工更改配置节点,当配置节点失效后,系统会自动选择新的配置节点,配置节点十分重要,它对SVC节点仲裁胜利起着决定性作用,仲裁胜利的排序规则通常如下:
1.配置节点(配置节点获得仲裁胜利的概率***)
2.距离仲裁站点近的节点(探测延时较低的SVC节点获得仲裁胜利的概率次之)
3.距离仲裁站点远的节点(探测延时较低的SVC节点获得仲裁胜利的概率***)
举例:
当两站点间光纤链路中断,第三站点仲裁节点活动时,脑裂发生,将通过投票仲裁选举获胜的站点,按照上述的仲裁胜利规则,configuration node位于节点2,选举站点2优先赢得仲裁,通过站点2恢复业务的正常存储访问。
当第三站点仲裁节点不活动时,不影响主机的正常存储访问,但是此时,两站点间光纤链路也中断了,发生脑裂,这时因为节点2为configuration node,它所拥有候选的Quorum将变为active Quorum,该Quorum选举站点2为仲裁胜利站点,通过站点2恢复业务的正常存储访问。
(2)EMC VPLEX Metro
VPLEX有着自己专属的防脑裂规则:
1.分离规则
分离规则是在与远程群集的连接中断(例如,网络分区或远程群集故障)时,确定一致性组 I/O 处理语义的预定义规则。在这些情况下,在恢复通信之前,大多数工作负载需要特定虚拟卷集,才能在一个群集上继续 I/O 并在另一个群集上暂停I/O。在 VPLEX Metro 配置中,分离规则可以描述静态***群集,方法是设置:winner:cluster-1、winner:cluster-2或 No Automatic Winner(无自动优胜者)(其中,***一项指定无***群集)。如果部署的系统没有 VPLEX Witness,一致性组设备 I/O 将在***群集中继续,并在非***群集中暂停。
2.VPLEX Witness
VPLEX Witness 通过管理 IP 网络连接至两个 VPLEX Metro 群集。VPLEX Witness通过将其自身的观察与群集定期报告的信息进行协调,让群集可区分群集内网络分区故障和群集故障,并在这些情况下自动继续相应站点上的 I/O。VPLEX Witness 仅影响属于 VPLEX Metro 配置中同步一致性组成员的虚拟卷,并且仅当分离规则指明群集1或群集 2 是一致性组***群集时才会影响(也就是说,“无自动优胜者”规则未生效时,VPLEX Witness 不影响一致性组)。没有 VPLEX Witness 时,如果两个VPLEX 群集失去联系,生效中的一致性组分离规则将定义哪个群集继续操作以及哪个暂停 I/O,如上所述。仅使用分离规则来控制哪个站点是优胜者时,可能会在出现站点故障时增加不必要的复杂性,因为可能需要手动干预才能恢复仍正常运行的站点 I/O。VPLEX Witness会动态地自动处理此类事件,这也是它成为扩展 Oracle RAC 部署绝对必要项的原因。它提供了以下几项内容:
a.在数据中心之间自动实现负载平衡
b.主动/主动使用两个数据中心
c.存储层的完全自动故障处理
为了让 VPLEX Witness 能够正确区分各种故障情况,必须使用互不相同的网络接口在独立于任意群集的故障域中安装它。这将消除单个故障同时影响群集和 VPLEX Witness 的可能性。例如,如果将 VPLEX Metro 配置的两个群集部署在同一数据中心的两个不同楼层,请在不同楼层部署 VPLEX Witness。另一方面,如果将 VPLEX Metro 配置的两个群集部署在两个不同的数据中心,请在第三个数据中心部署VPLEX Witness。
(3)HDS HAM/GAD
HDS的HAM/GAD存储双活方案是建立在VSP TrueCopy同步复制技术之上的,整个架构也需要仲裁机制防止脑裂,能保证心跳故障后,整个集群系统能对外提供数据一致性存储服务。目前,HAM/GAD仲裁的实现方式有下面几种:
1、优先级站点方式。这种方式最简单,在没有第三方站点的情况下使用,从两个站点中选一个优先站点,发生脑裂后优先站点仲裁成功。但如集群果发生脑裂后,优先站点也发生故障,就是导致业务中断,因此这种方案并非推荐的方案。
2、软件仲裁方式。这种方式应用比较普遍,采用专门的仲裁软件来实现,仲裁软件放在第三站点,可以跑在物理服务器或VM上,甚至可以部署到公有云上,PureStorage的ActiveCluster就把仲裁软件以OVF文件部署在公有云上。
3、阵列仲裁盘方式。这种方式是在第三站点采用另外一台阵列创建仲裁盘。这种方式稳定性,可靠性比较高。GAD的仲裁机制原理是采用仲裁盘的方式实现。
(4)NETAPP Clustered Metro Cluster(MCC)
MCC的MetroCluster的仲裁软件TieBreak支持装在第三站点的linux的主机上,通过检查对节点Ssh的session对HA pair和集群进行状态监控。TieBreak软件能够在3到5秒内检查到ssh session的故障,重试的时间间隔为3秒。所以这种方式也很灵活,第三站点可以选择两个数据中心中的一个,也可以选择公有云中的一个虚拟机,保证SSH网络可达,还可以选择其他建筑内的任意一台Linux虚拟机。
(5)IBM DS8800系列HYPERSWAP
DS8800 HYPERSWAP架构下的存储为ACTIVE-STANDBY模式,整体是对称式的架构,但是却没有第三仲裁站点,在双数据中心间链路全部中断时,要恢复业务需要人为关闭非存活站点的集群服务,并且修复链路,如下红皮书原文:
Unplanned HyperSwap: Site partition
In the scenario of Site parttion, the workload continues to run on Site_A.Because both sites are partitioned, each site thinks it is the only surviving site, as such, the nodes in each site try to start the workload on each site.
Running the workload at the same time on both nodes results in data corruption. To maintain data integrity, PowerHA SystemMirror supports recovery mode for HyperSwap through manual workload activation. This option indicates that when the link between the sites is down (both sites are down), user intervention for manual recovery is needed, therefore
maintaining data integrity.
When the site is down, because Auto Recovery Action is not supported, the resource groups(RGs) will remain in the ERROR state. User intervention is needed to correct the problem.
The user has to shut down the cluster services on Site_B and fix the connectivity issues. When done, the user can start the cluster services on Site_B.
赵海 大连农商银行 架构师
其实这个问题,我觉得还是要看整体的架构是什么样的?
假设定位到存储双活,那么是不是就割裂了数据库层的仲裁问题。实际上存储最终是为上层数据库及应用服务,如果这个夸中心的架构涉及到数据库、存储两层的组合,比如说存储双活之上是oracle rac,那么就比较复杂了。
首先对于存储本身的仲裁,应该有自己的算法,例如:
1)仲裁中心
2)最坏情况下,默认的算法。
对于夸中心的rac集群,同样有自己的规则:
1)仲裁盘
2)通过网络和磁盘心跳保证获得票数最多的子集活着。
3)实例小的节点存活。
但是当二者结合的时候,就有更复杂的场景可能会出现,尤其是出现两层架构仲裁的结果不一致。
为了避免这个结果出现,那么我们需要攻克以下问题:
1. 如何保障仲裁触发的时间序列一致。
2. 极端情况下的仲裁算法一致性。
例如,你可以通过oracle的仲裁参数misscount结合vplex的仲裁timeout参数来保障时间序列的一致性。
例如,你也可以调整各自默认算法的最终结果落到一边。
例如,你也可以通过二次开发来实现二者的联动。
***,所有的前提条件和策略都需要得到模拟实践的检验。