












人工智能是当今的热议行业,深度学习是热门中的热门,浪尖上的浪潮,但对传统 IT 从业人员来说,人工智能技术到处都是模型、算法、矢量向量,太晦涩难懂了。所以本文作者写了这篇入门级科普文章,目标是让 IT 从业者能看清读懂深度学习技术的特点,希望读者能够从中受益,顺利找到自己心仪的工作。
第一. 人工智能的天时地利人和
行业的成熟要靠从业者的奋斗(人和), 也要考虑大环境和历史的进程(天时和地利)。
人工智能技术的井喷并不是单纯的技术进步,而是软件、硬件、数据三方面共同努力水到渠成的结果,深度学习是 AI 技术的最热分支,也是受这三方面条件的限制。
AI 软件所依赖的算法已经存在很多年了,神经网络是 50 年前提出的技术,CNN/RNN 等算法比大部分读者的年龄都要大。AI 技术一直被束之高阁,是因为缺乏硬件算力和海量数据。随着 CPU、GPU、FPGA 硬件的更新,几十年时间硬件算力扩充了万倍,硬件算力被逐渐解放。随着硬盘和带宽的降价提速,20 年前全人类都没几张高清照片,现在单个公司的数据量就能达到 EB 级。大数据技术只能读写结构化日志,要读视频和图片必须用 AI,人类已经盯不过来这么多摄像头了。
我们只有从心里把 AI 技术请下神坛,才能把它当做顺手的工具去用。AI 的技术很深理论很晦涩,主要是这个行业刚刚发芽还未分层,就像 20 年前 IT 工程师需要全面掌握技能,现在的小朋友们连字符集都不用关注。
第二. 关联度模型
深度学习有两步工作,先要训练生成模型,然后使用模型去推测当前的任务。
比如说我用 100 万张图片标记好这是猫还是狗,AI 把图片内各个片段的特征提取出来,生成一个猫狗识别模型。然后我们再给这个模型套上接口做成猫狗检测程序,每给这个程序一张照片它就能告诉你有多大几率是猫多大几率是狗。
这个识别模型是整个程序中最关键的部分,可以模糊的认为它就是一个密封黑盒的识别函数。以前我们写程序都是做 if-then-else 因果判断,但图像特征没有因果关系只看关联度,过去的工作经验反而成了新的认知障碍,还不如就将其当做黑盒直接拿来用。
接下来我放一个模型训练和推测的实验步骤截图,向大家说明两个问题:
需要用客户的现场数据做训练才能出模型,训练模型不是软件外包堆人日就行,很难直接承诺模型训练结果。
训练模型的过程很繁琐耗时,但并不难以掌握,其工作压力比 DBA 在线调试 SQL 小多了,IT 工程师在 AI 时代仍有用伍之地。
第三. 动手实验
本节较长,如果读者对实验步骤和结果没兴趣,而是直接想看我的结论,也可以跳过这一节。
这个实验是 Nvidia 提供的入门培训课程——ImageClassification with DIGITS - Training a model。
我们的实验很简单,用 6000 张图片去训练 AI 识别 0-9 这几个数字。
训练样本数据是 6000 张标号 0-9 的小图片,其中 4500 张是用来做训练(train),1500 张是验证(val)训练结果。
实验数据准备
训练图片很小也很简单,如下图预览,就是一堆数字:
-- 下图是 01 样本图片 --

我做测试的图片是官方教程提供了个白底红字的“2”.
-- 下图是 02 测试图片 --

制作数据集
首先我们要做一个图片识别的数据集,数据集文件放在“/data/train_small”目录下,图片的类型选择“Grayscale”,大小选 28x28,其他都选默认,然后选择创建数据集“minidata”。
-- 下图是 03 初始数据集 --
下面是数据集创建的过程,因为我们的文件很小很少,所以速度很快;如果是几千万张高清大图速度就会很慢,甚至要搭建分布式系统把 IO 分散到多台机器上。
-- 下图是 04 初始数据集中 --
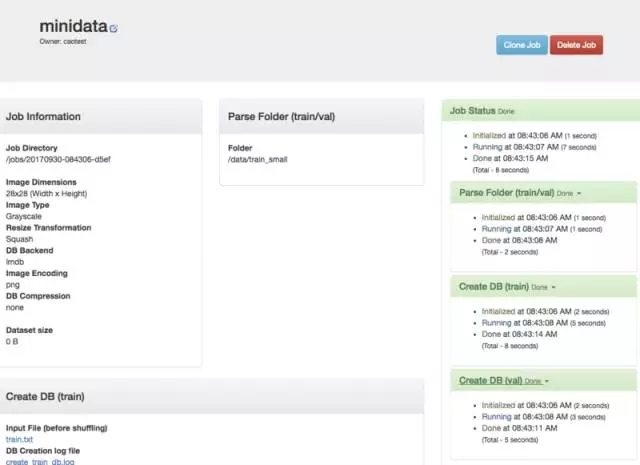
这是创建完成数据集的柱形统计图,鼠标恰好停在第二个柱形上,显示当前标记为“9”的图片有 466 个。
-- 下图是 05 创建完成数据集 --
开始创建模型
有了数据集以后我们就可以创建模型了,我们选择创建一个图像分类模型(Image Classification Model),数据集选之前创建的“minidata”,训练圈数输 30 次,其他选项暂时保持默认。
-- 下图是 06 新建模型 --
到了创建模型的下半段是选择网络构型,我们选择 LeNet 即可,将模型命名为 TestA。
-- 下图是 07 选择 LeNet --
这次 Demo 我们没做细节设置,但生产环境可能要经常修改配置文件。
-- 下图是 08 微调 LeNet --
接下来就开始生成模型了,小数据集简单任务的速度还是很快的,而且验证正确率很高。但是如果是大任务大模型,可能会算上几天时间。
-- 下图是 09 开始生成模型 --
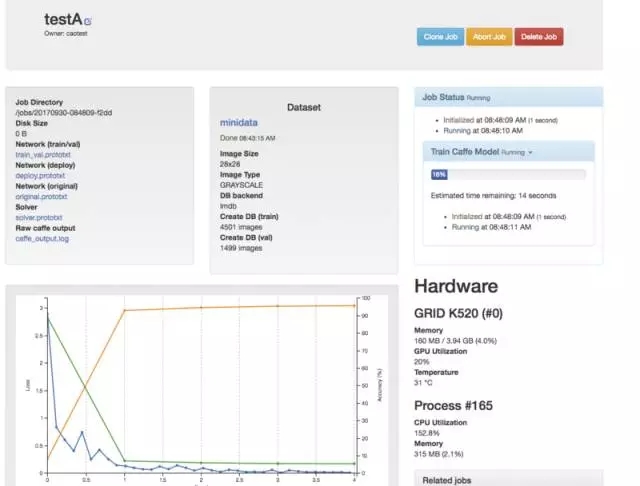
模型生成完成,我们再看一下验证正确率很高了,如果生产环境正确率太低,可能你要微调创建模型的参数。
-- 下图是 10 训练完成后的 accuracy--
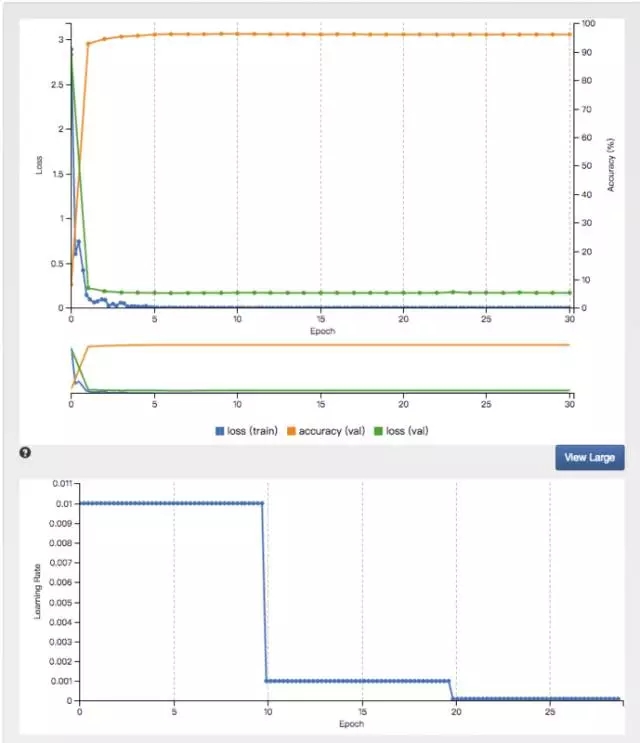
调试模型
在模型页面往下拖就可以看到下载模型、测试模型等按钮,我们选择测试模型,将那个“白底红字 2”提交做个测试。
-- 下图是 11 测试模型 --
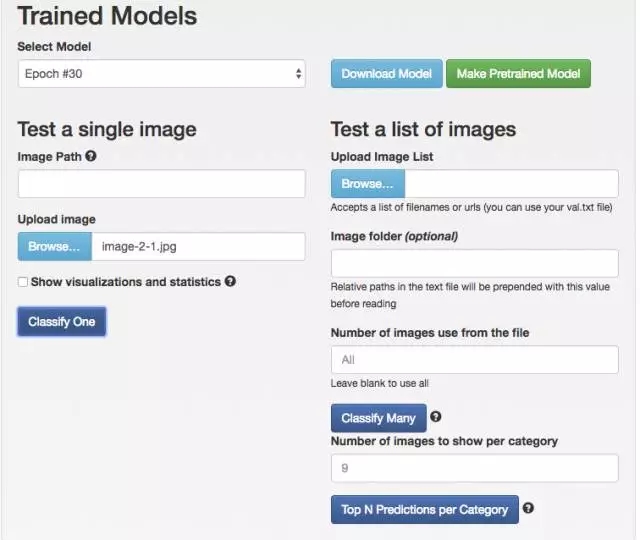
默认是测试 Epoch #30,我们先跑 10 次试试。本来想省点服务器电费,结果只有 20.3% 的几率识别正确。
-- 下图是 12TestA 模型 10 圈结果 --
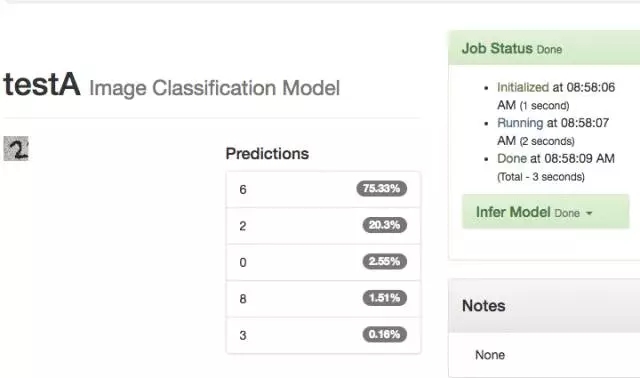
我们提高测试圈数到 25 圈,结果准确率从 20.3% 提高到了 21.9%。
-- 下图是 13TestA 模型 25 圈结果 --
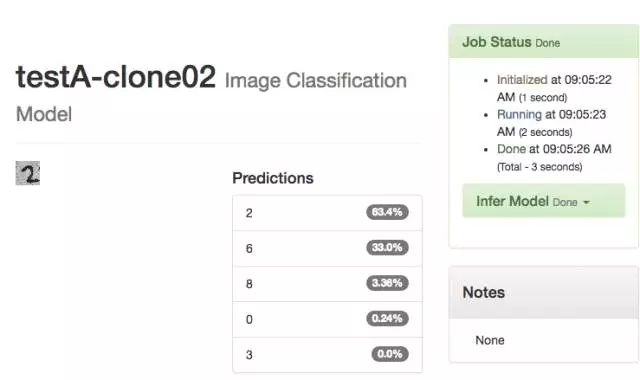
整个模型的上限是 30 圈,正确识别结果也才 21.92%。到了这里我插一句,未正确识别可能是因为我的建模数据是 28*28 的黑白图,而我给测试图片大小和颜色都不对。
-- 下图是 14TestA 模型 30 圈结果 --

更换模型继续调试
在 TestA 这个模型上可以点克隆任务,即制作一个同配置的模型再跑一次;这个按钮有意思啊,我们以前编译程序不通过的时候,retry 十万次也是不通过啊,为什么克隆任务是个面板常用按钮?
-- 下图是 15 克隆模型 TestA --
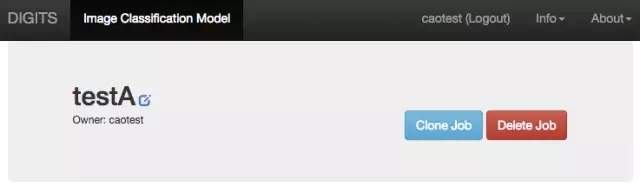
这时好玩的事情发生了,我做出的“TestA-Clone”,识别出数字 2 的几率是 94.81%。
-- 下图是 16 克隆 TestA 结果 --
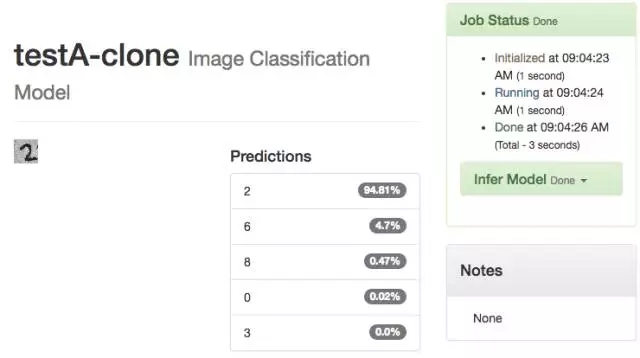
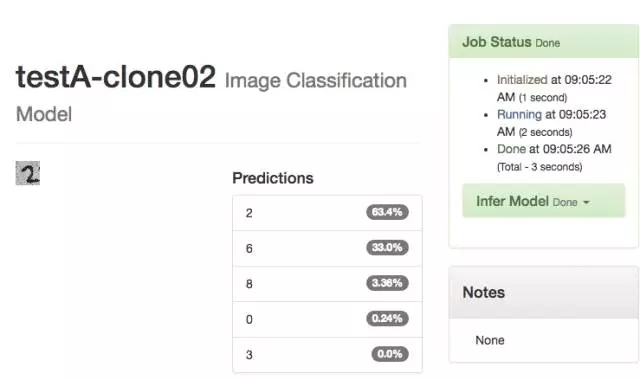
我们再把老模型克隆一次,结果识别出数字 2 的几率是 63.4%。
-- 下图是 17 再次克隆 TestA 结果 --
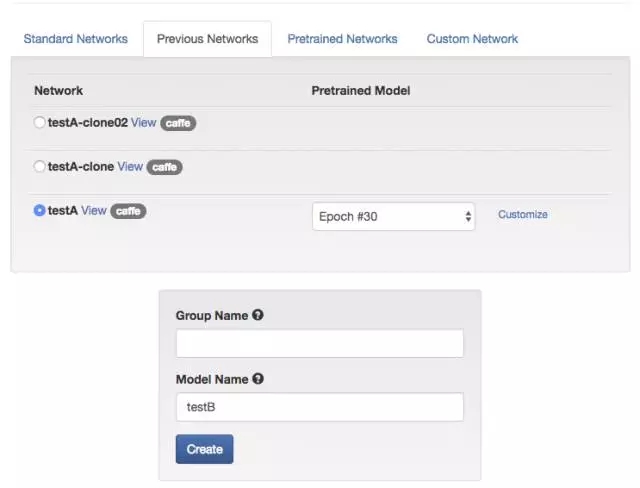
我新建一个模型 TestB,让它在 TestA 的基础上再次训练。
-- 下图是 18 新建 TestB --
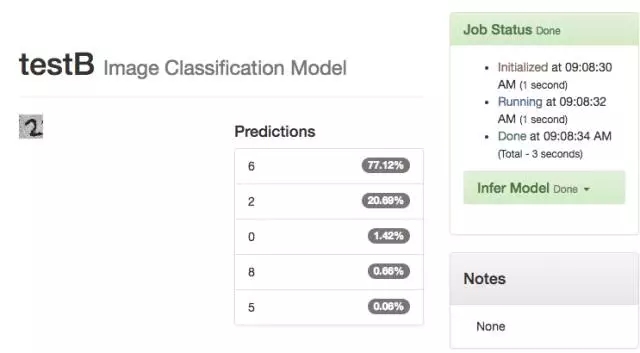
TestB 的训练结果反而不如最早的那一版模型,正确率 20.69%。
-- 下图是 19TestB 的训练结果 --
没有最惨只有更惨,看我新训练的模型 TestC。
-- 下图是 20TestC 训练失败 --
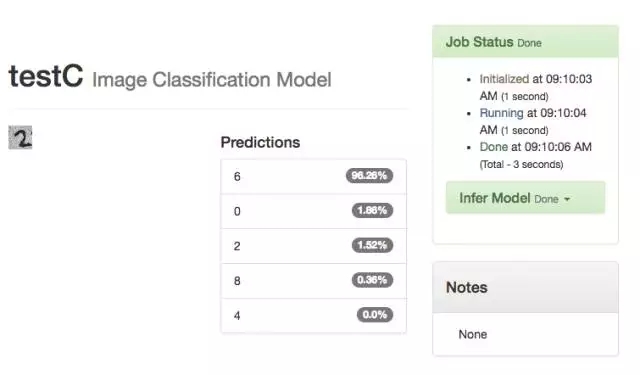
从这次测试看,最好的模型是 TestA-Clone,其次是 Clone2。
-- 下图是 21 模型结果汇总 --
但这就算找到合适模型了吗?我又手写了个数字 2,还特地选的黑底白字 28*28,结果这几个模型没一个识别准确的,全部识别失败。
-- 下图是 22. 新图识别失败 --

第四. 实战才能出模型
本次实验拿到正确率是 94.81% 的模型是意外惊喜,那个模型测其他图片失败倒是意料之中的。因为这次实验的初始样本才几千张,如果样本数量够多,过拟合(即噪音特征被纳入模型)的可能性就越小;我用的全部是默认调试选项,添加其他特征项调试模型可能会减少欠拟合(主特征没提取到)的几率;我并未明确定义该模型的使用场景,即没有明确训练数据、测试文件和生产文件是否相同。
我们看到完全相同配置的模型,只因为点击生成模型的时间不同,对同一个图片的识别结果确千差万别,再次强调这不是因果判断而是相关性计算。实验结论和我上文的主张相同,模型需要拿实战数据进行实际训练,且我们只能预估但不能预测模型生成结果。我做这个实验就是给大家解释,AI 模型训练不是软件外包,不是谈拢了价格就能规划人日预估效果的。
一个 AI 技术供应商简单点就是卖现成的模型,比如说人脸识别模型、OCR 识别模型等等。但如果客户有定制需求,比如说识别脸上有青春痘、识别是不是左撇子签名,那就需要先明确技术场景,再准备数据大干一场。至于练模型的时间是 1 天还是 1 个月不太确定,AI 模型训练像做材料试验一样,可能半年也可能十年才能发现目标。
第五. IT 工程师的新工作
前文我提到两个观点,第二个观点就是训练模型的工作并不难,IT 工程师可以较为容易的学会训练模型的工作,然后我们就能继续扩展从业范围,在 AI 大浪潮中分一杯热羹了。
首先说技术不是门槛,我们举个 IT 工程师能听懂的例子:一个 Oracle DBA 既没读过数据库源码,也还没摸过新业务场景,甚至缺乏理论知识只能做常见操作;现在这个项目可以慢慢上线,让他离线调试 SQL,拿到性能最佳值的点日志保存就完工了。做 AI 模型调试时,懂原理懂算法会让工作更有目的性,但更有目的性只能保证接近而不能保证命中目标。
根据上文的实验,我们可以看到有下列工作是需要人做的:
- 根据客户的要求,提出对原始数据的需求。这里要动业务方向的脑子,比如说想查一下什么人容易肥胖,天然能想到的是每个人的饮食和运动习惯,但专业医生会告诉你要调取转氨酶胆固醇一类的数据。
- 原始数据需要清洗整理和标注,没找到相关性的样本不是未标注的样本。前文试验中 6000 张图片可都是标注了 0-9 的数字的,我们测试模型是为了找到“2”这一组图片的相关性。清洗、整理和标注数据的工作可能是自动也可能是人工,自动做那就是我们写脚本或跑大数据,人工做就是提需求然后招 1500 个大妈给黄图打框,但工程师会对打框过程全程指导。这里还有取巧的方法,友商的模型太贵甚至不卖,那就是直接用友商的公有云 API 接口,或者买友商大客户的日志,让友商帮你完成数据筛检。
- 上文试验中仅仅是图片分类数据集,已经有很多可调整选项了;生产环境不仅有图片还有声音、文字、动作特征等数据集,数据集的设置是否合理,要不要重建数据集都需要多次调试和长期观察。
- 实验中生成模型没怎么调参数也只花了一分钟时间,但生产环境的模型生成参数要经常调整,而生成一个模型的时间可能是几小时甚至几天。
- 验证结果的准确性,如果是柔性需求可以目测几个测试结果就把模型上线了,但如果是刚性业务可能又要组织十万份以上样本进行测试验证。顺路说一句,用来训练模型的硬件未必是适用于来验证和跑生产环境的,如果是高压力测试可能还要换硬件部署。
- 模型也有日常维护,可能随着数据集的更新模型也要定期更新,也可能发现模型有个致命的误判会威胁到业务,这都需要及时处理。
第六. 附赠的小观点
谈到最后再附赠一些个人观点,随机想的,只写论点不写论证过程了:
- 现在搭建和使用 AI 环境很难,但软件会进步和解决这个问题;三年前云计算平台很难部署和维护,现在遍地都是一键部署和 UI 维护的云平台方案。
- 深度学习这个技术领域太吃数据和算力了,人脑不会像 AI 这么笨,可能以后会有新技术出现取代深度学习在 AI 领域的地位。
- 因为需要数据和算力,搞个 AI 公司比其他创业企业更难;现在有名的 AI 创业企业都是单一领域深耕三年以上,让用户提供数据他们只做单一典型模型。同样巨头企业搞 AI 也不容易,即使挖到人 AI 项目也要花时间冷起动,清洗数据不仅消耗体力同样消耗时间。
- 深度学习的计算过程不受控制,计算结果需要人来验证,所以它不能当做法务上的证据。当 AI 发现嫌疑人时警察会立刻采取行动,但它的创造者都无法描述 AI 下一步会如何下围棋。一个婴儿能尿出来世界地图,某人随手乱输能碰对银行卡的密码,AI 会告诉你股市 99.99% 要暴涨,但这些都不能当做独立单责的证据。
- 搞 AI 需要准备大量数据,中国对美国有个特色优势,可以做数据标注的人很多而且价格便宜,但到模型实践这一步,中国的人力成本太低又限制了 AI 走向商用。
- 不要恐慌 AI 会消灭人类,对人类有威胁的 AI 肯定是有缺陷的 AI,但人类一样也选出过希特勒这类有缺陷的领袖。也不要鼓吹 AI 会让人类失业社会动荡的,大家还是老老实实谈星座运势吧,我为什么就不担心自己失业?
- 有些事 AI 的确准率看起来很低实其很高,比如两人对话听能清楚 80% 的字就不错了,AI 只听懂 85% 了的文字已经越超人类了。你看我打倒颠字序并不影响你读阅啊。















