













分布式文件系统是分布式存储系统(键值系统、表格系统、数据库系统)的底层基础部件,其所起的主要功能有两个:一个是存储文档、图像、视频之类的Blob类型数据;另外一个是作为分布式表格系统的持久化层。
我们来看看业界是如何构建各家基础的分布式文件系统。
Google文件系统(GFS)
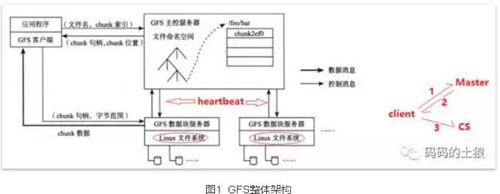
GFS系统的节点可分为三种角色:GFS Master(主控服务器)、GFS ChunkServer(CS,数据块服务器)以及GFS客户端。GFS文件被划分为固定大小的数据块(chunk),由主服务器在创建时分配一个64位全局唯一的chunk句柄。CS以普通的Linux文件的形式将chunk存储在磁盘中。为了保证可靠性,chunk在不同的机器中复制多份,默认为三份。客户端访问GFS时,首先访问主控服务器节点,获取与之进行交互的CS信息,然后直接访问这些CS,完成数据存取工作。需要注意的是,GFS中的客户端不缓存文件数据,只缓存主控服务器中获取的元数据,整体架构如图1所示。
1、租约机制
GFS系统中通过租约( lease)机制将chunk写操作授权给ChunkServer。拥有租约授权的ChunkServe称为主ChunkServer,其他副本所在的ChunkServer称为备ChunkServer。租约授权针对单个chunk,在租约有效期内,对该chunk的写操作都由主ChunkServer负责,从而减轻Master的负载。一般来说,租约的有效期比较长,比如60秒,只要没有出现异常,主ChunkServer可以不断向Master请求延长租约的有效期直到整个chunk写满。GFS为每个chunk维护一个版本号,每次给chunk进行租约授权或者主ChunkServer重新延长租约有效期时,Master会将chunk的版本号加1。
主ChunkServer向Master重新申请租约并增加对应副本的版本号,如果有备副本下线的话,重新上线后如果版本号太低,会被Master发现,从而将其标记为可删除的chunk,Master的垃圾回收任务会定时检查,并通知ChunkServer将此副本回收掉,从以上机制可见,版本号在整个机制中起到了至关重要的作用。
2、一致性模型
GFS主要是为了追加(append)而不是改写(overwrite)而设计的。一方面是因为改写的需求比较少,或者可以通过追加(加上版本号)来实现,比如可以只使用GFS的追加功能构建分布式表格系统Bigtable;另一方面是因为追加的一致性模型相比改写要更加简单有效。这种模式下,可能出现记录在某些副本中被追加了多次,即重复记录;也可能出现一些可识别的填充记录,应用层需要能够处理这些问题(幂等)。GFS的这种一致性模型是追求性能导致的,这增加了应用程序开发的难度。
3、追加流程
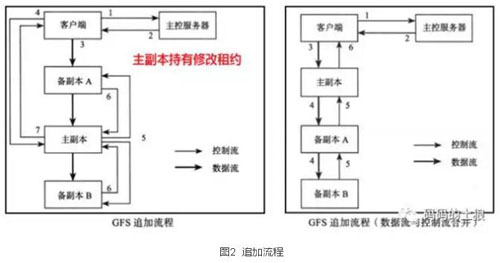
图2中,分离数据流与控制流主要是为了优化数据传输,每一台机器都是把数据发送给网络拓扑图上“最近”的尚未收到数据的节点。
4、容错机制
- Master容错
操作日志+checkpoint+实时热备。GFS Master的修改操作总是先记录操作日志,然后修改内存。当Master发生故障重启时,可以通过磁盘中的操作日志恢复内存数据结构。另外,为了减少Master宕机恢复时间,Master会定期将内存中的数据以checkpoint文件的形式转储到磁盘中,从而减少回放的日志量。所有的元数据修改操作都必须保证发送到实时热备才算成功。
- ChunkServer容错
GFS采用复制多个副本的方式实现ChunkServer的容错,另外,ChunkServer会对存储的数据维持校验和。GFS以64MB为chunk大小来划分文件,每个chunk又以Block为单位进行划分,Block大小为64KB,每个Block对应一个32位的校验和。当读取一个chunk副本时,ChunkServer会将读取的数据和校验和进行比较,如果不匹配,就会返回错误,客户端将选择其他ChunkServer上的副本。
5、Master设计
由于GFS中的文件一般都是大文件,因此,文件命名空间占用内存不多。这也就说明了Master内存容量不会成为GFS酌系统瓶颈;另外,从负载均衡的角度考虑,可以限制每个Chunk-Server“最近”创建的数量;每个chunk复制任务都有一个优先级,按照优先级从高到低在Master排队等待执行;Master会定期扫描当前副本的分布情况,如果发现磁盘使用量或者机器负载不均衡,将执行重新负载均衡操作;在进行副本重均衡时,要注意限制拷贝速度,否则会影响性能。
- 垃圾回收
GFS采用延迟删除的机制,Master定时检查,如果发现文件删除超过一段时间(默认为3天,可配置),那么它会把文件从内存元数据中删除,为了减轻系统的负载,垃圾回收一般在服务低峰期执行,比如每天晚上凌晨1:00开始。系统对每个chunk都维护了版本号,过期的chunk可以通过版本号检测出来。Master仍然通过正常的垃圾回收机制来删除过期的副本。
- 快照
快照( Snapshot)操作是对源文件/目录进行一个“快照”操作,生成该时刻源文件/目录的一个瞬间状态存放于目标文件/目录中o GFS中使用标准的写时复制机制生成快照,也就是说,“快照”只是增加GFS中chunk的引用计数,表示这个chunk被快照文件引用了,等到客户端修改这个chunk时,才需要在ChunkServer中拷贝chunk的数据生成新的chunk,后续的修改操作落到新生成的chunk上。(不改就不拷贝,只引用)
6、 ChunkServer设计
Linux文件系统删除64MB大文件消耗的时间太长且没有必要,因为ChunkServer是一个磁盘和网络IO密集型应用,因此,删除chunk时可以只将对应的chunk文件移动到每个磁盘的回收站,以后新建chunk的时候可以重用。
自动化对系统的容错能力提出了很高的要求,Google在软件层面的努力获得了巨大的回报,由于软件层面能够做到自动化容错,底层的硬件可以采用廉价的错误率较高的硬件,比如廉价的SATA盘,这大大降低了云服务的人力及硬件成本。
Google的成功经验也表明了一点:单Master的设计是可行的。单Master的设计不仅简化了系统,而且还能够较好的实现一致性。另外,Master维护的元数据很多,需要设计高效的数据结构,占用内存小,并且能够支持快照操作。支持写时复制的B树能够满足Master的元数据管理需求,然而,它的实现是相当复杂的。
Taobao File System
TFS设计时采用的思路是:多个逻辑图片文件共享一个物理文件。通过<块ID,文件编号>来唯一确定一个文件。
1、系统架构
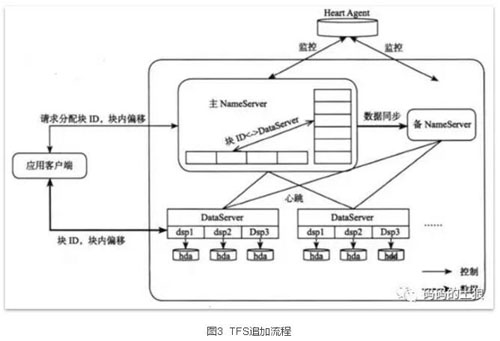
- TFS整体架构
NameServer通过心跳对DataServer的状态进行监测;每个DataServer上会运行多个dsp进程,一个dsp对应一个挂载点,这个挂载点一般对应一个独立磁盘,从而管理多块磁盘,TFS中Block的实际数据都存储在DataServer中,大小一般为64MB,默认存储三份。
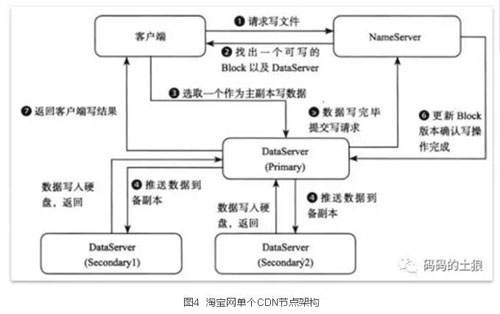
TFS是写少读多的应用,即使每次写操作都需要经过NameNode也不会出现问题,这大大简化了系统的设计,同一时刻每个Block只能有一个写操作,多个客户端的写操作会被串行化。客户端首先向NameServer发起写请求,NameServer需要根据DataServer上的可写块、容量和负载加权平均来选择一个可写的Block,并且在该Block所在的多个DataServer中选择一个作为写入的主副本(Primary),如果所有的副本都修改成功,主副本会首先通知NameServer更新Block的版本号,成功以后才会返回客户端操作结果,整个流程如图3所示。
2、讨论
相比GFS,TFS的写流程不够优化,***,每个写请求都需要多次访问NameServer;第二,数据推送也没有采用流水线方式减小延迟。这也是由特定历史时期的特定业务需求所决定的,淘宝的系统是需求驱动,用***的成本、最简单的方式解决用户面临的问题,TFS NameServer不需要保存文件目录树信息,也不需要维护文件与Block之间的映射关系。
由于用户可能上传大量相同的图片,因此,图片上传到TFS前,需要去重。一般在外部维护一套文件级别的去重系统( Dedup),采用MD5或者SHA1等Hash算法为图片文件计算指纹( FingerPrint)。图片写入TFS之前首先到去重系统中查找是否存在指纹,如果已经存在,基本可以认为是重复图片;图片写入TFS以后也需要将图片的指纹以及在TFS中的位置信息保存到去重系统中。去重是一个键值存储系统,淘宝内部使用Tair来进行图片去重。图片的更新操作是在TFS中写入新图片,并在应用系统的数据库中保存新图片的位置,图片的删除操作仅仅在应用系统中将图片删除。
随着系统的规模越来越大,商用软件往往很难满足需求,通过采用开源软件与自主开发相结合的方式,可以有更好的可控性,系统也有更高的可扩展性。互联网技术的优势在于规模效应,随着规模越来越大,单位成本也会越来越低。
3、内容分发网络
淘宝CDN采用分级存储。由于缓存数据有较高的局部性,在Squid服务器上使用SSD+SAS+SATA混合存储,图片随着热点变化而迁移,最热门的存储到SSD,中等热度的存储到SAS,轻热度的存储到SATA。通过这样的方式,能够很好地结合SSD的性能和SAS、SATA磁盘的成本优势。












