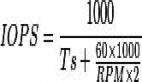写在前面
做过分布式系统的人都知道,想要在大规模集群下处理高并发事务时同时满足CAP(一致性、可用性、分区容错),从理论上来说不可能,当然听说最近谷歌已经实现了这样的分布式系统,但是总的来说确实非常难。对于社交媒体的海量日志文件,如果我们也提出了需要确保高可用、持续写入数据、按照记录顺序返回数据等三条要求,你觉得是否可以实现?FaceBook的LogDevice实现了。
什么是日志
日志是记录一系列序列化的系统行为的信息,我们需要确保它们能够被保存在可靠的地方。对于应用程序来说,日志的作用一般有两个,即Troubleshooting和显示程序运行状态。好的日志记录方式可以提供我们足够多定位问题的依据。对于一些复杂系统,例如数据库,日志可以承担数据备份、同步作用,很多分布式数据库都采用“write-ahead”方案,在节点数据同步时通过日志文件恢复数据。
日志一般具有三个特性:
1、面向记录:写入日志的一定是孤立的行,而不是一个字节。日志实质上是问题的最小单元,用户也一定是读取整行日志。日志的存储原则上按照顺序,即按照LSN(日志顺序数字)存放,但是也不完全这么要求,所以日志系统可以优先高写入需求,对写入失败容错。
2、日志天生就是递增的:也就是说,日志是不会修改的,那么也就意味着,日志系统的设计应该是以高写入、高读取为目标,不需要担心更新操作的数据一致性问题。
3、日志存储周期长:可能是一天,也可能是一个月,甚至于一年。这也就意味着,日志的删除规则一般都是按照时间或者空间进行设定的,具有固定的规则。
来个假如
假如我们要设计一个分布式日志存储系统,你会怎么设计?
日志信息需要传输、存储,为了实现稳定的数据交换,我们可以采用Kafka作为消息中间件。
Kafka实际上是一个消息发布订阅系统。
Producer向某个Topic发布消息,而Consumer订阅某个Topic的消息,进而一旦有新的关于某个Topic的消息,Broker会传递给订阅它的所有Consumer。在Kafka中,消息是按Topic组织的,而每个Topic又会分为多个Partition,这样便于管理数据和进行负载均衡。同时,它也使用了Zookeeper进行负载均衡。
Kafka在磁盘上的存取代价为O(1),即便是普通服务器,每秒也能处理几十万条消息,并且它本身就是分布式架构,也支持将数据并行加载到Hadoop。
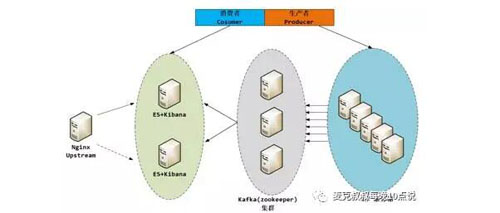
上面这张图是一个典型的采用消息中间件进行日志数据交换的系统设计架构,但是没有实现数据存储,也没有描述数据是如何被抽取并发送到Kafka的。
如果想要实现数据存储,并描述清楚内部处理流程,我们可以采用怎么样的日志处理系统架构呢?这里推荐你FaceBook的Scribe,它是一款开源的日志收集系统,在Facebook内部已经得到大量的应用。它能够从各种日志源上收集日志,存储到一个中央存储系统 (可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。
Scribe最重要的特点是容错性好。当后端的存储系统奔溃时,Scribe会将数据写到本地磁盘上,当存储系统恢复正常后,Scribe将日志重新加载到存储系统中。
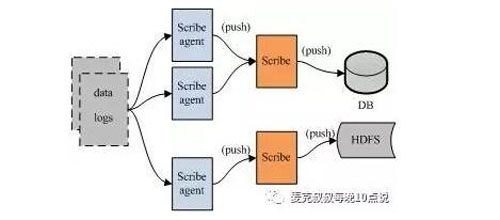
Scribe的架构比较简单,主要包括三部分,分别为Scribe Agent, Scribe和存储系统。Scribe Agent实际上是一个Thrift Client。Scribe接收到Thrift Client发送过来的数据,根据配置文件,将不同topic的数据发送给不同的对象。存储系统实际上就是Scribe中的Store,当前Scribe支持非常多的Store。
貌似市面上已经有很多分布式日志收集系统了,为什么FaceBook还需要推出LogDevice呢?而且FaceBook自己已经有了Scribe,为什么还要继续设计LogDevice?因为Scribe更多实现了日志数据的收集,它不是一个完整的日志处理、存储、读取服务,系统设计也较为死板,存储更多依赖HDFS,使用过程中一定出现了不能满足自身需求的情况。而对于开源的哪些分布式日志收集系统,更多的是集成各个开源组件,共同完成日志存储系统设计需求。对于FaceBook的工程师来说,他们一贯秉承着用于创新的精神,想想Apache Cassandra,其实当时已经有HBase等成熟的NoSQL数据库,但是由于存在中心节点等诸多设计上的限制,FaceBook自己搞了一个全新的无中心化设计的架构,即便在初期饱受质疑,后续也在不断地改进,到目前为止,Cassandra真正进入到了它的黄金时代。