













照例甩一波链接。
今天开始进入一个全新的领域,嗯,叫基数估计。
什么叫基数估计呢?
基数是指一个一大堆值集合中,不同的值的个数。
我们之前讲的,都是精确的统计,有一说一有二说二,直接去重统计就可以了。
基数估计,故名思议,估计,意思就是使用概率论的思想,用更低空间更低时间的成本,以一个很低很低的误差率来估计数据的基数。
能不能说说人话呢?
好好好,你长得好看说什么都对。
加入一个集合长这样
{大蕉,小蕉,小蕉,大大蕉,小蕉}
统计思想会这样说。
啊大蕉,嗯,1个。
小蕉,没出现过,嗯,2个。
小蕉,出现过了,嗯,2个。
大大蕉,没出现过,嗯,3个。
小蕉,出现过了,嗯,3个。
概率论思想会这样说。
我夜观天象,掐指一算,公子是个喜脉。
呸呸呸。掐值一算,有99%的概率是3个。
但是又有小伙伴开始说了,我特么把手都快掐出血了,也不知道你吖是怎么估算的。
年轻人不要太着急嘛。
我们今天几乎所有算法的启蒙。Linear Counting(LC)
来自于1900年一个叫 KY · Whang 的大湿的一篇名叫《A linear-time probabilistic counting algorithm for database applications》的论文。
This algorithm has O(q) time complexity, where q is the number of values including duplicates, and produces an estimation with an arbitrary accuracy prespecified by the user using only a small amount of space. Traditionally, accurate counts of unique values were obtained by sorting, which has O(q log q) time complexity. Our technique, called linear counting, is based on hashing.
意思就是,啊传统的精确统计至少要O(q log q)这么死鬼多时间,我们只需要O(q) ,你不觉得很厉害吗?然后我们是用 Hash 实现的,嗯,可牛逼了。
怎么做的呢?
我们先创建一个长度为m的数组,每一个bit都设置为0,然后搞个Hash算法把这些值的位置所对应的0改为1。
比如字符串 “小蕉写得这么给力你不点个赞吗”,经过 Hash 算法1、Hash 算法2、Hash 算法3,生成了数字,1、11、21。
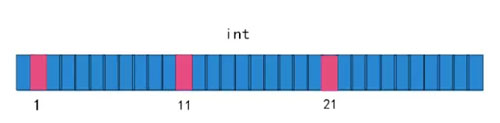
这时候又来了一个字符串 “小蕉写得这么给力你不点个赞”,经过 Hash 算法1、Hash 算..
你等等等等等,这不是BitMap吗?你特么在说啥。
年轻人不要太着急嘛。
我急!这辈子就现在!最!急!
好好好我来了我来了。上面这个数组比BitMap所需要的数组小很多很多很多。然后我们假设最终有u个位置还是0。我们给出一个极大似然估计,估计一下n的估计(下面这个是极大似然估计)就长这样。
![]()
好了我要睡觉了,拜拜。
至于详细的数学推导及误差分析推导,且听下回分...
【本文为51CTO专栏作者“大蕉”的原创稿件,转载请通过作者微信公众号“一名叫大蕉的程序员”获取授权】















