












- 背景
SCM(Storage Class Memory)是一种新型的存储介质,其特性与传统的存储介质有很大的不同。如何基于SCM介质的特性,在软件层面做出相关的改变,充分发挥SCM的能力,是下一代超高性能存储系统需要解决的至关重要的问题。
- SCM对存储软件的挑战
SCM对存储软件的挑战是多方面的,其中最关键的挑战是软件栈时延、网络时延以及崩溃一致性,下面分别进行简单的说明。
- 软件栈时延
不同介质的时延如下图所示,在没有SCM出现以前,时延从低到高分别是SRAM、DRAM、NAND(SSD)、Magnetic Disk(HDD)。可以看到,DRAM和NAND之间存在2-3个数量级的差异,这是一个明显的性能鸿沟(Performance Gap)。SCM的时延在在DRAM和SSD之间,它的出现填补了这个性能鸿沟,这使得SCM既能够被当作比较快的存储设备来使用,又可以当作略慢一些的内存(同时有非易失特性)来使用,如下图右侧所示(在图中标为NVM)。
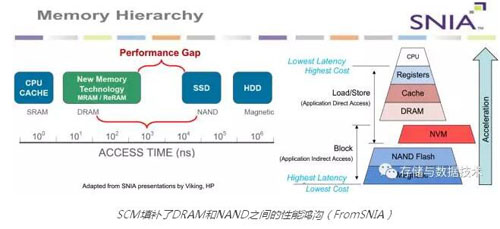
SCM填补了DRAM和NAND之间的性能鸿沟(FromSNIA)
在现有AFA存储系统中,为追求NVMe SSD的极致性能,软件栈本身带来的时延已经无法忽略 。相比SSD,SCM介质的访问时延有几个数量级的差异(从数百微秒级到数百纳秒级),软件栈时延的问题将更为凸显。如传统的从应用到内核的软件栈对功能的分解层级清晰,对于慢速的存储介质是合适的,但对于SCM这样的超高速介质则成为了速度的瓶颈。
- 网络时延
基于同样的原因,网络时延在SCM系统中的占比也成为了影响系统时延的主要矛盾。如何构建高速、稳定的网络,成为了能否在系统中充分利用SCM介质性能的关键因素。
- 崩溃一致性(CrashConsistency)
相对于传统内存,SCM可以提供相同的访问接口(Byte Addressable SCM: Load/Store),同时提供了数据非易失能力。在基于内存的计算机系统中,不需要考虑系统崩溃后内存中数据的恢复问题(系统崩溃后内存数据全部丢失,需要从其他地方恢复数据),而在SCM系统中需要考虑这个问题(如何在系统恢复后直接从SCM中恢复数据?)。这个问题极大影响了软件系统的设计理念,如在数据写入SCM的过程中,由于CPU保存到介质的顺序可能受到硬件的自动调整,需要根据数据在系统崩溃后被使用的顺序来保证数据在存储到SCM时的顺序,或者能够通过其他方式恢复数据的内在一致性,否则就会发生数据损坏。
一个简单的示例如下图所示。程序的意图是先写入数据data[0]和data[1],然后再设置valid标志位为1,表示数据是有效的。然而如果不通过store和fence指令配合指定数据写入SCM的顺序,数据写入SCM就可以被硬件调整。调整后的顺序可能是先写入valid标志,再写入data。如果在写入valid标志后,但data尚未写入之前发生了系统崩溃,则在SCM将会存在错误的信息。在系统恢复后,将会将SCM中的垃圾数据认为是有效数据,从而带来数据一致性的问题:
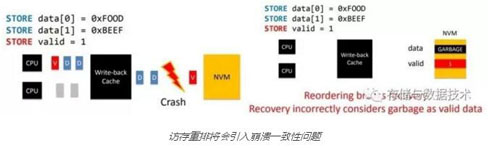
访存重排将会引入崩溃一致性问题
Data数据从Cache 到SCM介质的持久过程,通常需要增加新的commit CPU指令,保障数据真正持久化到了NVM 介质中。但是,在commit操作未执行之前,由于Cache空间不足,引起的不可控、随机的Data数据从Cache到SCM的持久化,让数据不一致问题更复杂了。Commit操作影响了未来存储应用软件设计,甚至成为软件架构设计的关键要素。数据一致性与性能的矛盾仍然是永恒的架构课题。
- 如何应对这些挑战
- 应对软件栈时延的挑战
应对软件栈时延挑战的主要方法,是采用新的软件分层模式,打薄软件栈深度,减少软件消耗。如开源的libpmem(http://pmem.io/)为持久化内存提供了基础的编程框架,在极致性能场景通过bypass传统软件栈的直通方式去除相应的时延消耗,如下图最右侧所示(引自http://pmem.io/2014/08/27/crawl-walk-run.html)。软件可以从用户态通过Load/Store直接访问SCM,绕过内核软件栈,就能够最大程度地减少软件栈的时延开销。
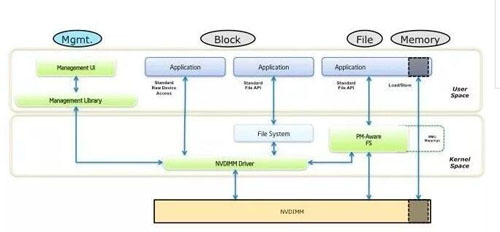
用户态Load/Store直通模式提供最优软件栈时延
所以,软件用户态化,除了带来维护性、App实例编排的好处外,性能优化是更重要的。上图直接访问新介质空间地址的信息,避免了内核过多的操作。 内核调度,系统调用的us级开销,在us级的介质面前,已经过于重载,bypass 内核操作新介质成为必须的选择。
- 应对崩溃一致性的挑战
保证崩溃一致性的最简单方式是在写入数据前先记录日志(Log),并在故障恢复后通过日志回放来恢复数据(Redo)。这个方式只要保证日志在SCM上先持久化即可,其恢复过程相对简单,不易出错,但该方案的缺点是产生了两倍的写I/O,时延也增加了一倍,影响了SCM系统的可靠性和性能。
针对这一缺点,学术界提出了一些能够避免写日志,通过巧妙地组织数据结构的更新顺序来在crash后恢复一致状态的方法。例如Write Optimal Radix Tree(WORT),通过记录节点的层次信息,使得crash后可以检测出不一致的节点,并通过检查其子节点将状态恢复到一致。
下图是在WORT上插入一个新的parent节点的示意图,每个节点最左侧的数字表示节点所在的层次,后面的一个数字标志其子节点共同的prefix长度,其后是子节点共同的prefix本身(这里可以先忽略prefix长度和prefix本身)。图中也标出了插入新的parent节点的操作顺序:
- 先产生新的parent节点C4
- 再更新原来叶子节点B4的层次信息(原来层次为1,现在为3,新的层次为3是因为C4节点进行了prefix压缩)
- 再将A4节点的指针指向C4节点
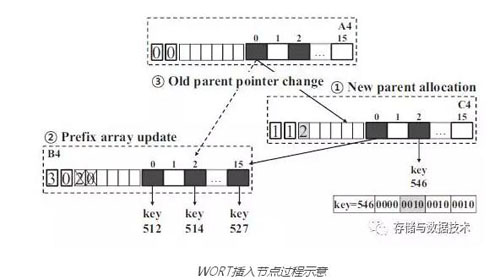
假定在第二步之后第三步之前发生了crash,那么从A4沿着父子节点的指针访问到B4的时候,就会发现期待的层次应该是1,但B4上记录的却是3,这就说明有crash发生过并需要恢复B4。这时可以通过检查B4的任意两个childrenkey的共同prefix,恢复出B4原来记录的prefix长度(2)和prefix值(2, 0),并把层次信息恢复为1。
可以看出,WORT解决了崩溃一致性的问题,但数据结构较复杂,同时其直接更新数据的方式有可能带来介质写入的不均衡,影响SCM寿命。这说明学界在SCM专用数据结构方面的研究,仍有很大的探索空间。
(关于WORT的更详细介绍,请参考https://www.usenix.org/system/files/conference/fast17/fast17-lee.pdf)
- 应对网络时延的挑战
随着RDMA技术的不断成熟,利用RDMA构建低时延网络成为构建高性能存储系统(包括使用SCM的系统)的主要解决方案。通过RDMA通信,可以同时降低网络时延(特别是小数据的网络传输时延)和CPU在网络传输相关动作上的消耗。存储软件需要基于RDMA协议对原有I/O路径进行优化,以获得更高的性能。典型的方案包括使用RDMA实现数据镜像,利用RDMA构造存储节点间的高性能通信机制等。
- 总结
如何利用好SCM特别是Byte Addressable SCM,对存储系统的软件架构设计提出了非常高的要求,这个命题的解法涉及了数据结构,算法,调度,协议,计算机体系架构等多个方面,具有颠覆性影响,也是未来很长一段时间内学界和业界的研究热点。华为也在充分拥抱学界和业界的成果,同时积极追求创新,努力构建SCM介质应用的竞争力:
- 在软件时延上,进行Load/Store访问方式的研究,打薄软件栈。同时进行低时延调度框架的研究,保障SCM访问时延不因为调度而发生大幅度波动,提高时延稳定性。
- 在崩溃一致性方面,进行SCM专用创新性数据结构的研究。当前的成果已能够在性能,磨损等方面进行均衡,相对业界其他数据结构有更好的表现。在今年的Flash Summit大会上,华为针对SCM数据结构的研究做了专题演讲,把研究结果向业界共享:https://www.flashmemorysummit.com/English/Collaterals/Proceedings/2017/20170808_FN11_Zha.pdf
- 在网络方面,结合华为自研网络芯片进行软件栈垂直优化,充分发挥RDMA的优势。
在使用好SCM上,学界和业界都在探索中,华为也将以开放、合作的姿态,加入到这个进程,争取在第一时间实现研究到产品的转化,为客户提供新一代的超高性能存储而持续努力。












