













在Windows下资源管理器查看内存使用的情况,如果使用率达到80%以上,再运行大程序就能感觉到系统不流畅了,因为在内存紧缺的情况下使用交换分区,频繁地从磁盘上换入换出页会极大地影响系统的性能。而当我们使用free命令查看Linux系统内存使用情况时,会发现内存使用一直处于较高的水平,即使此时系统并没有运行多少软件。
这正是Windows和Linux在内存管理上的区别,乍一看,Linux系统吃掉我们的内存(Linux ate my ram),但其实这也正是其内存管理的特点。

free命令介绍
下面为使用free命令查看我们实验室文件服务器内存得到的结果,-m选项表示使用MB为单位:

输出的第二行表示系统内存的使用情况:
Mem: total(总量)= 3920MB,
used(已使用)= 1938MB,
free(空闲)= 1982MB,
shared(共享内存)= 0MB,
buffers = 497MB,
cached = 1235MB
注:前面四项都比较好理解,buffer 和 cache找不到合适的词来翻译,它们的区别在于:
- A buffer is something that has yet to be “written” to disk.
- A cache is something that has been “read” from the disk and stored for later use.
即buffer用于存放要输出到磁盘的数据,而cache是从磁盘读出存放到内存中待今后使用的数据。它们的引入均是为了提供IO的性能。
输出的第三行表示在第二行的基础上-/+ buffers/cache得到的:
– buffers/cache used = Mem used – buffers – cached = 1938MB – 497MB – 1235MB = 205MB
+ buffers/cache free = Mem free + buffers + cached = 1982MB + 497MB + 1235MB = 3714MB
输出的第三行表示交换分区使用的情况:
Swap:total(总量)= 4095MB
used(使用)= 0MB
free(空闲)= 4095MB
由于系统当前内存还比较充足,并未使用到交换分区。
上面输出的结果比较难理解的可能是第三行,为什么要向用户展示这行数据呢?内存使用量减去系统buffer/cached的内存表示何意呢?系统空闲内存加上buffer/cached的内存又表示何意?
内存的分类
我们把内存分为三类,从用户和操作系统的角度对其使用情况有不同的称呼:
|
Memory that is |
You’d call it |
Linux calls it |
|
taken by applications |
Used |
Used |
|
available for applications, and used for something |
Free |
Used |
|
not used for anything |
Free |
Free |
上表中something代表的正是free命令中”buffers/cached”的内存,由于这块内存从操作系统的角度确实被使用,但如果用户要使用,这块内存是可以很快被回收被用户程序使用,因此从用户角度这块内存应划为空闲状态。
再次回到free命令输出的结果,第三行输出的结果应该就能理解了,这行的数字表示从用户角度看系统内存的使用情况。因此,如果你用top或者free命令查看系统的内存还剩多少,其实你应该将空闲内存加上buffer/cached的内存,那才是实际系统空闲的内存。
buffers/cached好处
Linux 内存管理做了很多精心的设计,除了对dentry进行缓存(用于VFS,加速文件路径名到inode的转换),还采取了两种主要Cache方式:Buffer Cache和Page Cache,目的就是为了提升磁盘IO的性能。从低速的块设备上读取数据会暂时保存在内存中,即使数据在当时已经不再需要了,但在应用程序下一次访问该数据时,它可以从内存中直接读取,从而绕开低速的块设备,从而提高系统的整体性能。
而Linux会充分利用这些空闲的内存,设计思想是内存空闲还不如拿来多缓存一些数据,等下次程序再次访问这些数据速度就快了,而如果程序要使用内存而系统中内存又不足时,这时不是使用交换分区,而是快速回收部分缓存,将它们留给用户程序使用。
因此,可以看出,buffers/cached真是百益而无一害,真正的坏处可能让用户产生一种错觉——Linux耗内存!
其实不然,Linux并没有吃掉你的内存,只要还未使用到交换分区,你的内存所剩无几时,你应该感到庆幸,因为Linux缓存了大量的数据,也许下一次你就从中受益。
实验证明
下面通过实验来验证上面的结论:
我们先后读入一个大文件,比较两次读入的实践:
1.首先生成一个1G的大文件
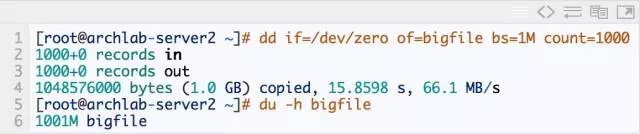
2.清空缓存
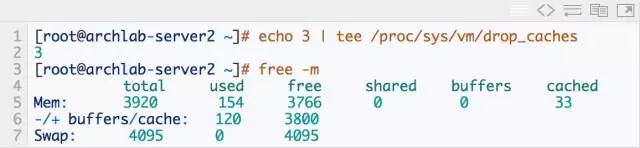
3.读入这个文件,测试消耗的时间
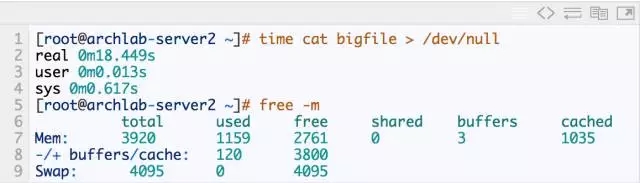
4.再次读入该文件,测试消耗的时间

从上面看出,***次读这个1G的文件大约耗时18s,而第二次再次读的时候,只耗时0.3s,足足提升60倍!

















