这是一篇很难写的文章,因为我希望这篇文章能对大家有所帮助。我不会给大家介绍机器学习,数据挖掘的行业背景,也不会具体介绍逻辑回归,SVM,GBDT,神经网络等学习算法的理论依据和数学推导,本文更多的是在流程化上帮助大家快速的入门机器学习和数据建模。
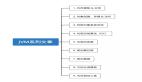
本文主要分为四个部分(限于时间关系会分为上下两篇):
上篇:
- 准备篇,主要涉及环境搭建以及pandas基本知识。
- 应用篇,我会以kaggle上的Titanic为例,从数据源获取,数据清洗,特征处理,模型选择,模型输出与运用。
下篇:
- 优化篇,介绍了几种优化的方法。
- 思考篇,提出几个困扰我的问题,希望能得到大家的帮助吧。
一 准备篇
1环境搭建
整个sklearn的实验环境是:python 2.7 + pycharm + Anaconda。
2 pandas基础
这里只能大家介绍下面会用到的pandas知识,有兴趣的可以去具体的学习。给大家推荐一本参考书:《Python for Data Analysis》。有基础的可以直接跳到应用篇。
pandas主要会用到Series 和DataFrame两种数据结构。Series像是一维的数组,而DataFrame更像是一种二维的表结构。
Series的构造方法:
- label=[1,0,1,0,1]
- data = pd.Series(data=label,index=['a','b','c','d','e'],dtype=int,name="label")
- print data
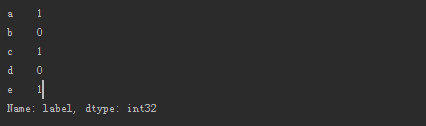
Series取数据,通过index取数
- data['a']
- data[['a','b']]
DataFrame的构造
(1)以字典的形式构造
- frame = pd.DataFrame({'name':['Time','Jack','Lily'],'Age':[20,30,12],"weight":[56.7,64.0,50.0]})
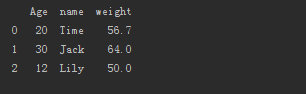
(2)由DataFrame 构建DataFrame
- frame1 = pd.DataFrame(frame,columns=["name","Age"])
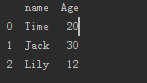
从frame中读取了两列构成新的DataFrame。
DataFrame的操作
1 增加列
- frame1["friends_num"]=[10,12,14]
2 删除列
- frame2 = frame1.drop(["name","Age"],axis=1)
3 查找数据行
- frame1[frame1["friends_num"]>10]
结果如下:
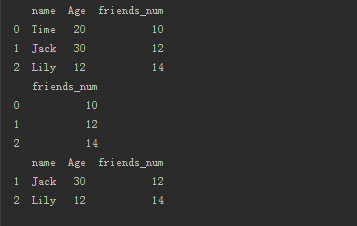
DataFrame的统计方法
1 apply 配合lambda 处理列,如将frame1的Age列进行分段。
- frame1["Age_group"] = frame1["Age"].apply(lambda x: 0 if x < 20 else 1)
2 describe输出统计信息,非常强大
- frame1.describe()
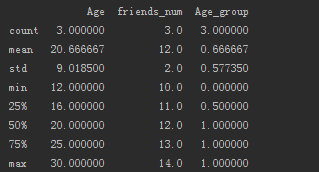
给出了8个统计量,对我们的数据处理特别有用。有个问题,直接使用describe方法只能统计数值类的列,对于字符类的变量没有统计。加个参数就行。
- frame1.describe(include=['O'])
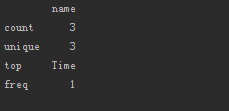
3 缺失值处理
- #以0填充缺失值
- frame1.fillna(0)
- #丢掉任何包含NAN的行
- frame1.dropna()
- #删除全为nan的行
- frame1.dropna(how="all")
二 应用篇
1 数据读取
本例以Titanic作为数据源。大家可以在附件获取到数据。
- data = pd.DataFrame(pd.read_csv(train_path))
- data_test = pd.DataFrame(pd.read_csv(test_path))
- data_test = data_test[["Pclass","Name","Sex","Age","SibSp","Parch","Ticket","Fare","Cabin","Embarked"]]
- x = data[["Pclass","Name","Sex","Age","SibSp","Parch","Ticket","Fare","Cabin","Embarked"]]
- y = data[["Survived"]]
- print x.describe()
- print x.describe(include=['O'])
- print data_test.describe()
- print data_test.describe(include=['O'])
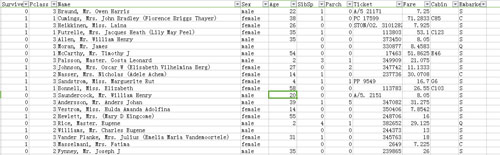
数据的初始统计信息:

2 数据清洗
1 缺失值处理。
Age和Embarked列存在少量缺失值,分别处理。
- #用众数填充缺失值
- data_set["Embarked"]=data_set["Embarked"].fillna('S')
- #用均值填充Age缺失值
- data_set["Age"]=data_set["Age"].fillna(data_set["Age"].mean())
2 删除缺失率较大的列(初步处理时)
Cabin列的缺失率达到了75%,删除改列。
- data_set = data_set.drop([ "Cabin"], axis=1)
3 特征处理
特征处理是基于具体的数据的,所以在特征处理之前要对数据做充分的理解。特征处理没有固定方法之说,主要靠个人的经验与观察,通过不断的尝试和变换,以期望挖掘出较好的特征变量。所以说,特征处理是模型建立过程中最耗时和耗神的工作。
1)单变量特征提取。
- #根据name的长度,抽象出name_len特征
- data_set["name_len"] = data_set["Name"].apply(len)
观察name列

通过观察Name列数据,可以发现名字中带有性别和婚否的称谓信息。提取这些信息(可能是有用的特征)。
- data_set["name_class"] = data_set["Name"].apply(lambda x : x.split(",")[1]).apply(lambda x :x.split()[0])
2)多变量的组合
sibsp 代表兄弟姐妹和配偶的数量
parch 代表父母和子女的数量
因此可以将sibsp和parch结合获得家庭成员的数量
- data_set["family_num"] = data_set["Parch"] + data_set["SibSp"] +1
3)名义变量转数值变量
- #Embarked
- data_set["Embarked"]=data_set["Embarked"].map({'S':1,'C':2,'Q':3}).astype(int)
- #Sex
- data_set["Sex"] = data_set["Sex"].apply(lambda x : 0 if x=='male' else 1)
4)数据分段
根据统计信息和经验分段
- #[7.91,14.45,31.0]根据Fare的统计信息进行分段
- data_set["Fare"] = data_set["Fare"].apply(lambda x:cutFeature([7.91,14.45,31.0],x))
- #[18,48,64]按照经验分段
- data_set["Age"] = data_set["Age"].apply(lambda x:cutFeature([18,48,64],x))
简单的数据处理后,我们得到了如下12维数据:
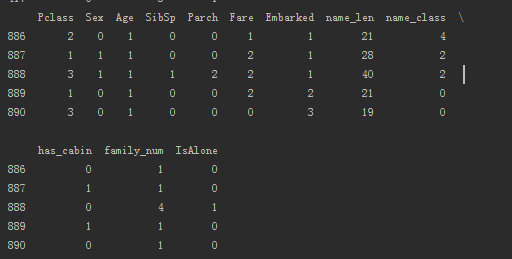
4 模型选择与测试
初步选取了5种模型进行试验
RandomForestClassifier
ExtraTreesClassifier
AdaBoostClassifier
GradientBoostingClassifier
SVC
模型参数:
- #随机森林
- rf_params = {
- 'n_jobs': -1,
- 'n_estimators': 500,
- 'warm_start': True,
- # 'max_features': 0.2,
- 'max_depth': 6,
- 'min_samples_leaf': 2,
- 'max_features': 'sqrt',
- 'verbose': 0
- }
- # Extra Trees 随机森林
- et_params = {
- 'n_jobs': -1,
- 'n_estimators': 500,
- # 'max_features': 0.5,
- 'max_depth': 8,
- 'min_samples_leaf': 2,
- 'verbose': 0
- }
- # AdaBoost
- ada_params = {
- 'n_estimators': 500,
- 'learning_rate': 0.75
- }
- # GBDT
- gb_params = {
- 'n_estimators': 500,
- # 'max_features': 0.2,
- 'max_depth': 5,
- 'min_samples_leaf': 2,
- 'verbose': 0
- }
- # SVC
- svc_params = {
- 'kernel': 'linear',
- 'C': 0.025
- }
模型选择代码:
- classifiers = [
- ("rf_model", RandomForestClassifier(**rf_params)),
- ("et_model", ExtraTreesClassifier(**et_params)),
- ("ada_model", AdaBoostClassifier(**ada_params)),
- ("gb_model", GradientBoostingClassifier(**gb_params)),
- ("svc_model", SVC(**svc_params)),
- ]
- heldout = [0.95, 0.90, 0.75, 0.50, 0.01]
- rounds = 20
- xx = 1. - np.array(heldout)
- for name, clf in classifiers:
- print("training %s" % name)
- rng = np.random.RandomState(42)
- yy = []
- for i in heldout:
- yy_ = []
- for r in range(rounds):
- X_train_turn, X_test_turn, y_train_turn, y_test_turn = \
- train_test_split(x_train, labels_train, test_size=i, random_state=rng)
- clf.fit(X_train_turn, y_train_turn)
- y_pred = clf.predict(X_test_turn)
- yy_.append(1 - np.mean(y_pred == y_test_turn))
- yy.append(np.mean(yy_))
- plt.plot(xx, yy, label=name)
- plt.legend(loc="upper right")
- plt.xlabel("Proportion train")
- plt.ylabel("Test Error Rate")
- plt.show()
选择结果如下:
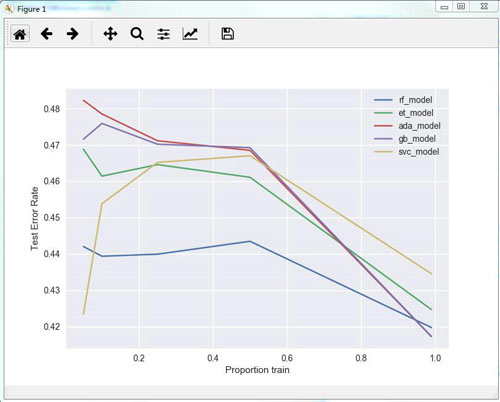
从上图可以看出,randomForest的一般表现要优于其他算法。初步选择randomforest算法。
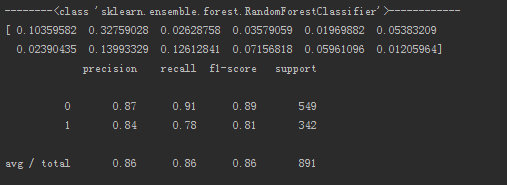
模型的在训练集上的表现:
- def modelScore(x_train,labels_train,x_test,y_test,model_name,et_params):
- print("--------%s------------")%(model_name)
- model = model_name(**et_params)
- model.fit(x_train, labels_train)
- if "feature_importances_" in dir(model):
- print model.feature_importances_
- print classification_report(
- labels_train,
- model.predict(x_train))
- print classification_report(
- y_test,
- model.predict(x_test))
- return model
- modelScore(x_train, labels_train, x_test, y_test, RandomForestClassifier, rf_params)
训练集的混淆矩阵如下图:
测试集的混淆矩阵如下图:
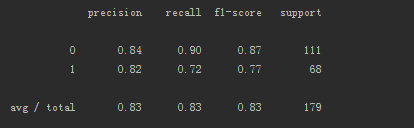
到此,初步的学习模型就建立起来了,测试集的准确度为83%。由于时间关系,优化篇和思考篇将放在下篇文章与大家分享,敬请期待。
原文链接:https://cloud.tencent.com/community/article/229506
作者:赵成龙
【本文是51CTO专栏作者“腾讯云技术社区”的原创稿件,转载请通过51CTO联系原作者获取授权】