十一结束,假期开工返乡潮仍在继续。就在昨日,一则视频刷爆朋友圈。
视频里,北京、广州、上海、成都、武汉的火车站都相继开通自助“刷脸”进站通道。
乘客惊呼“连化妆和美瞳都能识别出来,太神奇!”
其实,刷脸早已不是什么新鲜事了!我们今天来聊一个更好玩的事儿,那就是你说话,AI给你配表情。让你做个真正的虚拟人儿。
文章略枯燥,技术性的话术有点多,普通小白估计看起来够呛。技术宅们,上!
SIGGRAPH 2017曾经收录过英伟达的一篇关于3D动画人物面部表情研究的论文:Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion,在该论文中,英伟达展示了通过音频输入实时、低延迟驱动3D面部表情的机器学习技术,从而实现了虚拟人物面部表情和音频输入***配合。
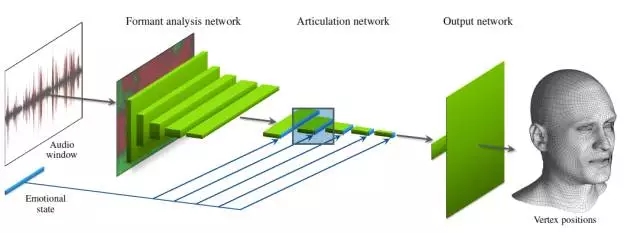
图1. 根据语音推断脸部动画的深度神经网络
让我们先从这张图开始吧。以下“我们”一词为论文作者的***人称。
当网络的输入为时长大约半秒的音频时,输出是与音频窗口的中心相对应的固定拓扑网格的3D顶点位置。该网络还有一个用于描述情绪状态的二次输入。其神经网络直接从训练数据中学习情绪状态,不进行任何形式的预标记(pre-labeling)。
我们提出了一种通过低延迟的实时音频输入驱动3D面部动画的机器学习算法。我们的深度神经网络可以学习从输入音频波形到脸部模型的3D顶点坐标的映射,同时还能找到一个简洁的隐藏代码,这个代码可以用来区分只根据音频无法解释的面部表情变化。在进行干预时,隐藏代码可以作为面部动画情绪状态的直觉控制(intuitive control)。
我们使用基于视觉的传统表演捕捉法(performance capture methods)获取了3-5分钟的高质量动画数据,并用这些数据对神经网络进行了训练。我们的主要目标是模拟单个表演者的说话风格;在用户研究中,当我们用不同性别、口音或讲不同语言的说话者的语音驱动模型时,我们也能得到不错的结果。这些结果可应用于游戏对话、低成本本地化、虚拟现实头像和远程呈现等技术中。
CCS 概念: • 计算方法论→动画;神经网络;基于回归的监督学习;学习隐藏表征;其他关键词:面部动画、深度学习、音频
端对端网络架构
下面我们将阐述该网络的架构,以及关于音频处理和从语音内容中分离出情绪状态的细节。
输入一小段音频窗口,神经网络的任务是推断该音频窗口(window)中心的面部表情。我们将表情直接表示为面部固定拓扑网格中某一无情绪姿态(neutral pose)的逐顶点差分向量。当训练好网络后,我们通过在音频轨道滑动窗口来将网格变成动画,在每个时间步长上对网络进行独立评估。虽然网络本身没有关于前几帧动画的记忆,但是在实践中它可以生成暂时稳定的结构。
架构概览
我们的深度神经网络由一个特殊用途层、10个卷积层以及2个完全连接层构成。我们将其切分为3个概念单元,如图1和表1所述。
我们先将音频窗口输入到一个共振峰分析网络中,生成一个随时间变化的语音特征序列,之后我们会用这个序列驱动发音。该神经网络先利用固定函数自相关分析从音频中提取出原始共振峰信息(请看原文第3.2节),然后再用其中5个卷积层优化这些信息。通过训练,卷积层可以学习提取对面部动画有用的短期特征(shortterm features),例如语调、重读和特定音素。第5个卷积层的输出就是此类特征随时间变化的抽象表示。
接下来,我们将结果输入到一个发音神经网络中。这个网络由5个卷积层构成,这些卷积层可以分享特征的时序变化,并最终确定一个用于描述音频窗口中心面部姿态的抽象特征向量。
将情绪状态的(学习)描述作为二次输入连接到该发音神经网络中,用以区分不同的面部表情和说话风格(请看原文第3.3节)。我们将情绪状态表示为一个E维向量,直接将其与发音神经网络每层的输出连接在一起,这样之后的层就可以相应地改变它们的行为。
每个l层都会输出 Fl×Wl×Hl激活函数,其中Fl 是抽象特征映射的数量,Wl是时间轴的维度,Hl是共振峰周的维度。在共振峰分析网络中,我们使用1×3的strided convolution逐渐减小Hl,逐渐增加Fl,也就是使原始共振峰信息向抽象特征偏移,直到Hl= 1且Fl = 256为止。同样,在发音神经网络中,我们利用3×1卷积减小Wl,也就是通过结合不同时间域(temporal neighborhood)的信息来对时间轴进行二次采样(subsample)。
我们选择了表1中列出的特定参数,因为我们发现这些参数在用数据集训练的过程中始终表现良好,同时也保证了合理的训练次数。虽然得出的结果对层数或特征映射并不是很敏感,但是我们发现我们必须对两个不同阶段中的卷积进行调整以避免出现过度拟合。重要的是,共振峰分析网络在时间轴的每一个点上都执行相同的操作,因此我们可以在不同的时间偏移(time offsets)中使用相同的训练样本。
发音神经网络输出一系列共同表示目标面部姿态的256+E抽象特征,。我们将这些特征输入到一个输出神经网络(output network)中,以在跟踪网格中生成5022个控制顶点的最终3D位置。该输出网络是一对可以对数据进行简单线性转换的全连接层。***层将输入特征集映射到线性基本函数的权重上,第二层计算对应基向量(basis vectors)的加权总和,用它来表示最终顶点位置。我们将第二层预设为150个预先计算的PCA模块,这些模块总体可以解释训练数据99.9%的变化。理论上,我们可以用一个固定的基准来有效地训练先前的层,生成150个PCA系数。但是我们发现,在训练中任由基向量自行变化得出的结果反而更好一些。
音频处理
网络的主要输出是语音音频信号,在信号输入到网络之前我们将其转换为16 kHz单声道信号。在试验中,我们对每个声道的音量(volume)进行正则化,以确保可以利用完整的动态范围[-1,+1],但是我们并没有进行任何诸如动态范围压缩、降噪任何处理或预加强滤波器(pre-emphasis filter)的处理。
表1中的自相关层将输入音频窗口转化为一个简洁的2D表达,之后的卷积层。《语音生成source–filter模型》(filter model of speech production)[Benzeghiba等人. 2007;Lewis 1991]这篇论文启发我们提出了这种方法,他们将音频信号建模为线性滤波器(声道)和激励信号(声带)的混合体。众所周知,线性滤波器的共振频率(共振峰)携带有关于语音的音素内容的重要信息。激励信号可以表示说话者声音的音调、音色和其他特征,我们假设对面部动画而言这种信号并不重要,因此我们主要借助共振峰来改善网络对不同说话者的泛化。
线性预测编码(LPC)执行信号滤波器分离(source–filter separation)的标准方法。LPC将信号断为数个短帧信号,根据***自相关系数K计算出每帧信号的线性滤波器系数,并执行反向滤波以提取激励信号。滤波器的共振频率完全取决于自相关系数的值,因此我们选择跳过大部分处理步骤,将自相关系数直接作为瞬时共振峰信息的表征。这种方法在直觉上可行,因为自相关系数本质上表示的是一种压缩形式的信号,其频率信息与原始信号的频谱(power spectrum)基本匹配。这种表示非常适合卷积网络,因为卷积层可以轻易地学习如何估计特定频带的瞬时频谱。
在试验中,我们将520ms的音频作为输入(关于预计输出姿态的260ms历史样本和260ms未来样本)。我们选择这个数值的原因是,它可以使我们在不向网络提供过多数据(这样会导致过度拟合)的情况下捕捉到诸如音素协同发音的相关效应。我们将输出音频窗口分为64个重叠为2x的音频帧,这样每帧音频都对应16ms(256个样本),并且连续的帧数之间间隔8ms(128个样本)。在每帧音频中,我们移除直流分量(DC component),用标准Hann窗口减缓时间域混叠效应(temporal aliasing effects)。***,我们计算出自相关系数K = 32,总共获得了64×32个输入音频窗口标量。虽然自相关系数小一点(例如K = 12)也足以确认单个音素,但是我们选择更多地保留关于原始信号的信息,以确保之后的层也可以检测出音调变化。
我们的方法不同于语音识别领域先前的绝大多数方法,这些方法的分析步骤通常都基于某一种专用的方法,例如梅尔频率倒谱系数(MFCC)、感知线性预测系数(PLP)和rasta filtering [Benzeghiba等人. 2007]。这些方法之所以被广泛采用是因为它们可以很好地线性分离音素,非常适合隐马尔科夫模型(Hidden Markov Models)。在我们的早期测试中,我们尝试了几种不同的输入数据表征,结果发现我们方法的自相关系数明显更好。

图2.表演者不说话时动画是什么样?这些是从表演者不说话的训练集中抽取的样本帧。
情绪状态的表征
根据语音推断面部动画本身就是一个不明确任务,因为同一语音可以对应不同表情。这一点尤其体现在眼睛和眉毛上,因为它们与语音的生成无任何直接关系。用深度神经网络处理此类不明确任务相当困难,因为训练数据必然会涵盖几乎相同的语音输入生成大不相同的输出姿态的情况。图2给出了几个当输入音频剪辑完全无声音时产生矛盾训练数据的实例。如果网络除了音频数据还有其他可用的数据,它就会学习输出矛盾输出的统计均值。
我们解决这些不明确任务的方法是向网络提供一个二次输入。我们将每个训练样本都与一小部分附加的隐藏数据关联起来,这样网络就有足够的信息用来明确地推断出正确的输出姿态。理想情况下,这些附加数据应编码给定样本时间域内所有无法根据音频本身推断出的动画相关特征,包括不同的表情、说话风格和自相关模式等。通俗地说,我们希望二次输入能代表表演者的情绪状态。除了能消除训练数据中的歧义,二次输入还对推断很有帮助——它可以使我们能够将不同的情绪状态于同一给定声带混合并匹配在一起,以有效地控制得出的动画。让动画实现情绪状态的其中一种方法是,根据明显的情绪对训练样本进行标记或分类[Anderson等人. 2013;Cao等人. 2005;Deng等人. 2006;Wampler 等人. 2007]。
这种方法并不算理想,但是因为它无法保证预定义的标记可以充分消除训练数据中的歧义。我们并没有选择依赖预定义的标记,而是采用了一种由数据驱动的方法。在这种方法的训练过程中,网络自动学习情绪状态的简明表征。这样只要给出足够多样的情绪,我们甚至可以从in-character片段(in-character footage)中提取出有意义的情绪状态。我们将情绪状态表示为E维向量,其中E是一个可调参数,在测试中我们将其设定为16或24,并初始化从高斯分布中提取出的随机值的分量(components。)。
给每个训练样本都分配这样一个向量,我们将保存这些隐藏变量的矩阵称为“情绪数据库”。如表1所示,发音神经网络所有的层的激活函数后都附有情绪状态。这样情绪状态就作为损失函数(请看原文第4.3节)computation graph(计算图)的一部分;由于E是一个可训练的参数,因此在进行反向传播时它会随着网络权重的更新而更新。E维度两种效应之间的均衡。如果E太低,情绪状态就无法消除训练数据变化的歧义,导致出现不理想的音频反映。如果E太高,所有情绪状态就会变得太过狭义,无法用于一般推断(请看原文第5.1节)。
情绪数据库的有这样一个潜在问题:如果我们不能有效地限制情绪数据库,它可能会学习明确地保存音频中呈现的信息。如果不加限制,它可能会保存确定大部分面部表情的E blend形状权重(E blend shape weights),弱化音频的作用,并使网络无法处理训练中未出现出的数据。
按照设计,音频数据提供的信息应仅限于520ms间隔内的短期效应。因此,我们可以通过禁止情绪状态包含短期变化来防止它们包含重叠信息。情绪状态专门包含长期效应对推断也很有帮助——当情绪状态保持不变时,我们也希望网络能生成合理的动画。为此,我们可以通过在损失函数中引入一个专用的正则项来惩罚情绪数据库中的快速变化,这样在训练过程中情绪状态就会逐渐平缓。我们的方法有一个较大的局限,我们无法正确模拟眨眼和眼部动作,因为它们与音频无任何关系,也无法通过缓慢变化的情绪状态来表示。
虽然在发音神经网络所有的层上都连接情绪状态似乎有些多余,但是我们发现在实践中这样做可以大幅改善结果。我们认猜测这是因为情绪状态的作用是在多个抽象层(abstraction level)上控制动画,通常抽象层越高学习难度就越大。连接靠前的层可以实现对精细动画特征(如协同发音)的精确控制,而连接靠后的层则只能加强对输出姿态的直接控制。直觉上,当单个姿态得到很好的表示时,情绪状态训练早期应连接靠后的层,而到了训练后期则应连接靠前的层。