无监督特征学习的当前趋势概览:回归到随机目标的流形学习,发掘因果关系以描述视觉特征,以及在强化学习中通过辅助控制任务增强目的性和通过自我模拟进行预训练。从无标注数据中可以挖掘的信息有很多,看起来我们目前的监督学习只不过是掠过了数据蛋糕的表面奶油而已。
2017 年,在无监督学习领域发生了什么?在本文中,我将从个人角度概览一些最近工作进展的。
「无监督学习是机器学习中一场旷日持久的挑战,被视为人工智能的关键要素。」Yann LeCun 解释道。相当程度上,我们在无标注数据中忽略了非常多的信息,而且通常也认为,人类大脑在学习的大部分时间中都不是处于监督状态并能处理无标注信息。或许看看下面这幅著名的「Yann LeCun 的蛋糕」,你能得到更好的理解。

事实上,通过相当数量的标注样本训练机器也许对理解我们的学习机制很有帮助,但是在寻找现象的内部规律的时候;被反常现象震惊并试图寻找其中规律的时候;被好奇心牵动的时候;通过游戏训练技能的时候,这些场景都不需要有人明确地告诉你理论上哪些是好的,哪些是坏的。没错,这些例子选取有些随意,但以上就是我从本文涉及到的论文中找到的一些想法。
下文中提及的所有想法都有共同的基础:从未接触过的数据中找到一种自监督的方法是不太可能的。那么,我们需要寻找在没有标签的数据中寻找哪些信号呢?或者说,如何在没有任何监督的情况下学习特征呢?
《Unsupervised learning by predicting the noise》这篇论文给出了一个很异乎寻常的答案,就是噪声。我认为这篇论文在今年的 ICML 大会上是最重要的研究之一。论文的构想如下:每一个样本都相当于超球面上的一个向量,向量标注了数据点在其上的位置。实际上,学习的过程就相当于将图像和随机向量匹配对应,通过在深度卷积网络里训练,并通过监督学习最小化损失函数。
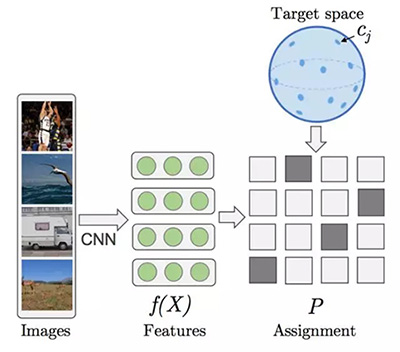
特别是,训练的过程在以网络的参量进行梯度下降和不同图像的伪目标重置之间交替,最终也是为了最小化损失函数。这里展示的图像特征的结果来自 ImageNet。两者都是在 ImageNet 上训练一个 AlexNet 得到的结果,左边的基于目标函数,右边使用的是其提出的无监督学习方法。

这个方法可以说代表了迁移学习算法探索的***进技术水平,但为什么这种方法能奏效呢?我的解释是:网络学会了用新的表征空间重新表示超球面上的矩阵。这可称为一种内在的流形学习。通过打乱布置进行优化是非常关键的方法,毕竟在新的表征空间中,不恰当的匹配不能够使相似的图像位于相近的位置。此外,正如通常情况一样,网络必须作为一个信息瓶颈。否则,模型会由于容量限制而学习成信息不全的一一对应,给表征增加很多噪声干扰(感谢 Mevlana 强调这一点)。
如此富有成效的结果竟然出自这样反常的想法-我的意思是,论文的作者就是想要这种效果,看看标题就知道了-正是在不断的强调着,你不应该用标注去寻找数据中的模式,即使目标具有很复杂的视觉特征。参见论文《Optimizing the Latent Space of Generative Networks》。
从图像中发现因果关系[Lopez-Paz et al. CVPR17] (https://arxiv.org/abs/1605.08179)
我接下来的发现来自 Léon Bottou 一次极富启发性和争议性的报告 Looking for the missing signal
(https://www.youtube.com/watch?v=DfJeaa--xO0&t=12s)(没错,本文作者偷了他的题目)发现的另外一半来自于他们的 WGAN,是关于因果关系的。但是在讨论之前,我们先回顾一下看看因果关系如何与我们的讨论联系起来。参见论文《Discovering Causal Signals in Images》。
如果你是通过机器学习理解因果关系的,你很快会得出图中整个区域缺少了某样东西,而较少关注它的背景。我们创造了一整套方法,只需要在训练数据中关注它们的联系,就可以将它们互相关联并得出预测结果。但实际上很多种情况下这都不奏效。如果我们可以在模型训练中加入因果关系的考虑的话又会如何呢?根本上说,我们可以阻止我们的卷积网络宣布图中的动物是一只狮子,因为背景表明这是一片典型的热带大草原吗?
很多人都在朝这个方向努力。这篇文章也想证实这样的观点,「图像数据的高级统计描述可以理解因果关系」。更精确的说,作者们猜想,物体特征和非因果特征是紧密联系的,而环境特征和因果特征并不需要互相关联。环境特征提供背景,而物体特征则是在数据集中的边界特性。在图中,它们分别指热带大草原和狮子的鬣毛。
另一方面,「因果特征是指导致图中物体如此表现的原因(就是说,那些特征决定了物体的类别标签),而非因果特征则是由图中物体的表现所导致(就是说,那些特征是由类别标签所决定)。」在我们的例子中,因果特征是热带大草原的视觉模式,非因果特征是狮子的鬣毛。
他们是怎么进行实验的呢?太简短的说明会有偏差,我将尽量避免。首先,我们需要训练一个探测器寻找因果的方向,这个想法源于大量过去工作所证实的,「加法因果模型」会在观察数据中遗留关于因果方向的统计痕迹,可以依次在学习高级时间点的过程中被探测到。(如果听起来太陌生,我推荐先看看参考文献)这个想法意在通过神经网络学习捕捉这些统计痕迹,可以用来辨别因果和非因果特征(进行二进制分类)。
只有拥有了真实因果关系标注的数据才能训练这样的网络,而这样的数据是很稀有的。但是实际上,通过设置一对因果变量并以一个记号指示因果关系,这样的数据是很容易合成的。目前为止,还没有人这样使用过数据。
第二,两个版本的图像,无论是目标还是屏蔽目标后的图片,都被标准的深度残差网络特征化。一些目标和背景评分都被设计为特征顶端,作为表示目标/背景的信号。

现在我们可以将图像中物体和环境通过因果或者非因果关系联系起来。这样导致的结果是,举例来说,「拥有***非因果分数的特征比起拥有***因果分数的特征,表现出更高的物体分数。」通过实验性的证实这个猜想,结果暗示了,图像中的因果性实际上是指物体和背景之间的差异。这个结果展现了其开辟新的研究领域的潜力,理论上,当数据的分布改变的时候,一个更好的探测因果方向的算法应该能更好的提取和学习特征。参见论文:《Causal inference using invariant prediction: identification and confidence intervals》、《Causal Effect Inference with Deep Latent-Variable Models》。
无监督辅助任务的强化学习:《Reinforcement Learning with Unsupervised Auxiliary Tasks》这篇论文以现在标准看来也许有点不够新颖,毕竟在本文写成的时候,它已经被引用过 60 次-自 11 月 16 日发表在 arXiv 上以来。但是实际上针对这个想法已经出现了新的工作,而我并非在其基础上讨论更加复杂的方法,只是由于其基本和新颖的见解而引用了它。
这个方案就是强化学习。强化学习的主要困难就是奖励的稀疏和延迟,那么为什么不引进辅助任务以增强训练信号呢?当然是因为,伪奖励必须和真实目标关联并且在执行过程中不依赖人为的监督。
论文给出了很直接和实在的建议:遍历所有辅助任务并增强目标函数(***化奖励)。在总体表现的意义上,该策略会在整体表现的前提下学习。实际上,有一些模型会同时接近于主策略与其他策略,以完成额外任务;这些模型会共享它们的参数。例如,模型的***层可以共同学习,将其视觉特征都展开。「让智能体平衡提高总体奖励的表现和提高辅助任务的表现是很有必要的」。
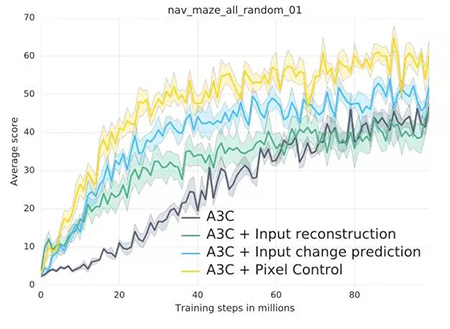
以下所示是论文中所探索的辅助性任务。首先是像素控制,智能体通过独立的决策***的改变输入图像的每一个像素点。其基本原理是「感知流中的改变通常和环境中的重要事件有关。」因此学习控制改变是很有意义的。第二个是特征控制,智能体被训练预测价值网络的一些中间层的隐藏单元的活化值。这个想法很有趣,「因为一个智能体的决策或者价值网络能学习提取环境中任务相关的高级特征。」第三个是奖励预测,智能体学习预测即时到来的奖励。这三种辅助任务通过智能体过去经验缓存的不断重新体验来学习。
其它细节暂且不提,这一整套方法被称作 UNREAL。在 Atari 游戏和 Labyrint 的测试中,它表现出了很快的学习速度,并能做出更好的决策。
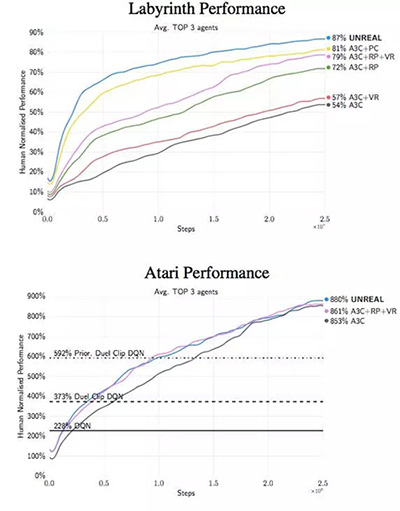
论文***的洞见是关于像素控制的有效性,而不是简单通过重构损失函数来进行预测的。可以将这些行为视为视觉自监督,但这是另一种层次的抽象概念。「学习重构只能让刚开始的学习速度很快,但***得到的效果却更差。我们的假设是输入重构会降低***的表现效果,因为它过于关注重构视觉输入的不相关部分,而不是能得到奖励的视觉线索。」
通过非对称自我模拟的内在动机形成和无意识学习:论文《Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play》。***我想强调的一篇论文是强化学习中关于辅助任务的想法。不过,关键是,相比明确的扭曲目标函数,智能体被训练完成完整的自我模拟,在确切的范围内可以自动生成更简单的任务。
自我模拟的最初形态是将智能体分离成「两个独立的意识」而建立的,分别称作 Alice 和 Bob。作者假定自我模拟中环境是(几乎)可逆的或者是可以重置到初始状态的。在这个案例中,Alice 执行了一个任务然后叫 Bob 也做同样的事,即根据 Alice 结束任务时的位置,到达世界中的同一个可观测状态。例如,Alice 可以走动然后捡起一把钥匙,打开一扇门,关掉灯然后停在一个确切的位置;Bob 必须跟随 Alice 做同样事情然后和 Alice 停在同一个位置。***,可以想象,这个简单环境的根本任务是在灯打开的时候在房间里拿到旗子。
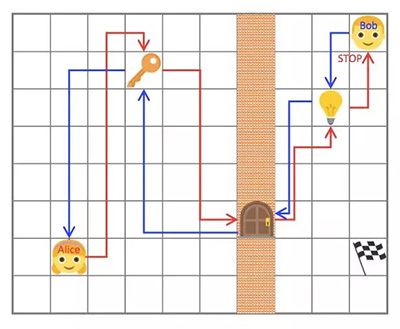
那些任务由 Alice 设定并强迫 Bob 学会与环境互动。Alice 和 Bob 都有明确的奖励函数。Bob 必须将完成任务的时间最小化,而在 Bob 完成了任务的前提下又更费时的时候,Alice 反而能得到更多的奖励。这些决策的相互作用使他们「自动构建起探索的过程」。再次提醒,这是特征学习的自我模拟的另一种实现的想法。
他们在几种环境中测试了这个想法,并在星际争霸的无敌人模式中也尝试了一下。「目标任务是制造新的机枪兵,为了实现目标,智能体必须按特定的次序进行一系列操作:(i)让 SCV 去挖矿;(ii)累积足够的水晶矿,建立一座兵营,以及(iii)一旦兵营建好,开始制造机枪兵。」这其中有多种决策选择,人工智能可以训练更多 SCV,让采矿速度加快,或者修建补给站扩充人口上限。在经过 200 步的训练后,人工智能每建立一个 就能得到加 1 分的奖励。
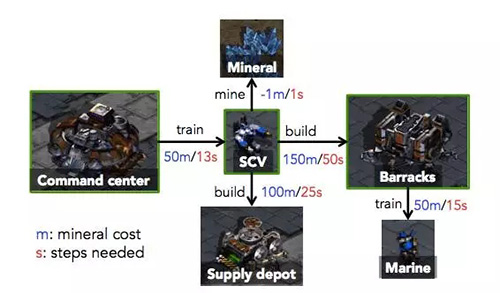
虽然完全匹配真实游戏中的状态几乎是不可能的,Bob 成功与否只取决于游戏中的全局状态,其中包括了每种单位的编号(包含建筑),以及矿物资源的累积程度。因此 Bob 的目标是在自我模拟中,完成 Alice 在最短时间内能建造的机枪兵数量和累积矿物的数量。在这个方案中,自我模拟确实有助于加快强化学习,并且在收敛行为上表现上,比起强化学习+一个更简单的决策预训练的基线方法的组合,要更好:
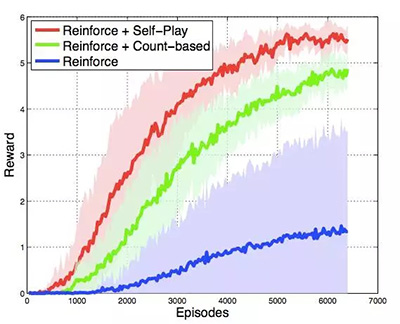
这里要注意的是图中并没有显示决策预训练的时间消耗。参见论文《Teacher-Student Curriculum Learning》。
***一提,并不是说无监督学习就总是困难的,实际上对其行为的测量更为困难。正如 Yoshua Bengio 所说:「我们不知道什么样的表征才是好的表征。[...] 我们甚至对判定无监督学习工作好坏的合适的目标函数都没有一个明确的定义。」
实际上,几乎所有的关于无监督学习都在间接使用监督学习或者强化学习去测量其中的特征是否有意义。在无监督学习还处在提高训练质量和加快训练速度以训练预测模型的阶段的时候,这么做是合理的。但是,在经过一个视频和文本必须使用不可见的数据部分进行一般表征之后,一切都不同了。这和迁移学习的鲁棒性特征的想法如出一辙。
原文:http://giorgiopatrini.org/posts/2017/09/06/in-search-of-the-missing-signals/
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】