













Hello哈,又好久没聊大数据相关的东西了,是不是又忘记了吖?这次聊聊B-树的升级版,B+树。前面的内容小伙伴可以回顾一下。
所谓B+树,跟B-树主要有这么几个差别。
1、只有叶子节点会保存数据,根节点和子节点都只把子树最小的值(或***值)作为索引
2、t阶B+树,除根节点外,每个子节点最多可以保有2t个关键字(索引或数据)
3、叶子节点除了数据外,还有卫星数据(比如一些属性啊什么的)
4、每个叶子节点都有指向下一叶子节点的指针,方便遍历和range 搜索。
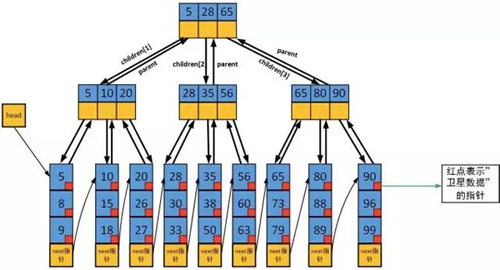
怎么去找到一个数据呢?
从根节点开始搜索,找到其中一个子树,然后继续遍历,直到叶子节点。遍历叶子节点的所有数据,从而找到对应的数据。若需要附属数据,则直接拿卫星数据。若需要继续遍历这棵树,则使用next指针进行树的遍历。
那现在有哪些成熟的场景在用B+树呢?
1、数据库索引。
比如Mysql,Oracle等。
2、文件系统索引。
比如NTFS。
3、搜索引擎索引。
比如Lucene以前用B+,现在用FST(Finite State Transducer)了
ElasticSearch是基于Lucene,也就随着变了。
那为什么这些场景会使用B+树呢?跟B-树比起来又有什么差别?
1、搜索更加稳定。B+树的一切搜索都需要付出树的高度那么多的次数来进行遍历,而B-树可能快也可能慢。
2、数据存储更加密集。B+树的一切数据都存在叶子节点中,不同与B-树的数据非常分散,所以同一块硬盘可以比B-树种存储的数据更加集中连续,这样磁盘的手臂就不需要移动太远。
3、数据附属有了根基。B+树的叶子节点有卫星数据,可以用来存放一些不需要被索引但是需要被查询出来的数据,比如数据库的整一行数据。
4、树的遍历更加方便。B+树的叶子节点中,有指向下一个叶子节点的指针。与B-树比较,B-树在遍历的时候只能遍历整棵树进行多个IO操作,而B+树只需要顺序往下对比即可。因为叶子节点都是有序的,所以作为范围查找也比较方便。
那问题来了,这跟大数据计数又有什么关系呢?
请参照上一篇B-树,跟B-树一样。都是将数据存储起来,然后进行搜索,搜索不到就添加到树中。
下一篇可能理论性比较强了,知识难度跳跃性比较高,小伙伴们做好准备。
【本文为51CTO专栏作者“大蕉”的原创稿件,转载请通过作者微信公众号“一名叫大蕉的程序员”获取授权】
















