「多体问题」(又叫 N 体问题)是看似简单,实际上在当今数学中极难攻克的问题。多体问题是指多个相互作用的实体。在物理学中,任何三体问题都没有一个封闭的形式或解析解(见:https://en.wikipedia.org/wiki/Three-body_problem)。像这样简单的问题反映了我们分析工具的局限性。这并不意味着它是不可解的,它只意味着我们必须诉诸于近似和数值技术来进行计算。可以用足够精确的数值计算分析太阳、月球和地球之间的三体问题以帮助宇航员登陆月球。
在深度学习领域,我们也有一个新兴的 N 体问题。许多更先进的系统现在正在处理多代理系统的问题。每个代理都可能有与全局目标合作或竞争的目标(即目标函数)。在多代理深度学习系统中,甚至在模块化的深度学习系统中,研究人员需要设计可扩展的合作方法。
Johannes Kepler 大学、DeepMind、OpenAI 和 Facebook 最近纷纷发表论文探讨了这个问题的各个方面。
在 Johannes Kepler 大学的团队,包括 Sepp Hochreiter(LSTM 的提出者)已提出利用模拟库仑力(即电磁力大小与反向距离的平方成比例)作为一种训练生成对抗网络(GAN)的替代目标函数。
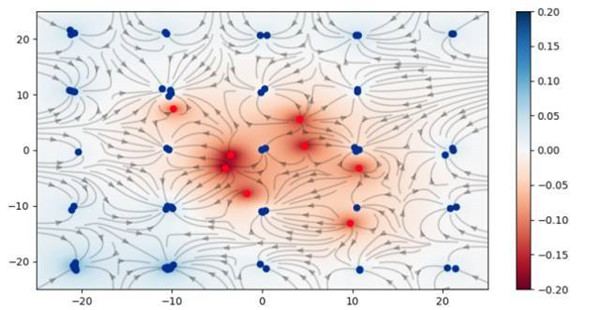
找到两个对抗网络之间的平衡状态是一个热门的研究课题。在深度学习中解决二体问题相当困难。研究发现,使用这种方法可以防止「模式崩溃」的不良情况。此外,设置确保收敛到一个***的解决方案,而且只有一个恰好也是全局的局部极小值。Wasserstein 目标函数(又名 Earth Mover Distance)可能是一个更好的解决方案,这在几个月前极其热门。这个团队已经把他们的创造命名为「库仑 GAN」。
微软 Maluuba 发表了一篇论文介绍了一个人工智能玩吃豆人游戏的系统,它的水平已经超过了人类。研究人员挑战的吃豆人游戏跟此类游戏最初的版本类似,人物在收集小球和水果的同时避免怪物。论文的题目是「强化学习的混合式奖励架构」。本文介绍了不同于典型的强化结构的强化学习(RL)的实现(即 HRA):

这篇文章令人惊讶的是所使用的目标函数的数量。本文描述了使用 1800 值函数作为其解决方案的一部分,也就是说,每个小球、每个水果和每个怪物都使用了代理。微软的研究表明使用数以千计的微型代理将问题分解成子问题并实际解决它是有效的!在这个模型中,代理之间的耦合显然是隐式的。
DeepMind 解了具有共享内存的多代理程序的问题。在论文《Distral: Robust Multitask Reinforcement Learning》中,研究人员通过「思想融合」灵感的代理协调方法来解决一个共同的问题。为此,研究人员采用了一种封装每个代理的方法。然而,它们允许一些信息通过代理的封装边界,希望狭窄的通道更具伸缩性和鲁棒性。
我们提出了多任务联合训练的新方法,我们称之为 distral(提取和迁移学习)。我们不建议在不同的网络之间共享参数,而是共享一个「提取」的策略,以捕获跨任务的共同行为。每个网络都被训练用来解决自己的任务,同时受限于近似共享的策略,而共享策略通过提取训练成为所有任务策略的中心。

其结果引出了更快,更稳定的学习,从而验证了狭窄通道的方法。在这些多代理(N 体问题)开放性问题是这种耦合的本质。DeepMind 的论文表明了更低的耦合相对于原生的紧耦合的方法的有效性(即权重共享)。
OpenAI 最近发表了在他们的系统中训练模型匹配其他代理的多系统的有趣的论文。论文题目为《Learning with Opponent-Learning Awareness》。该论文表明,「以牙还牙」战略的出现源自赋予多代理系统社会意识能力。尽管结果具有弹性问题,但它确实是一种非常令人着迷的方法,因为它解决了人工智能的一个关键维度(参见:多维智能)。
总而言之,许多领先的深度学习研究机构正在积极探索模块化深度学习。这些团体正在探索由不同的对象函数组成的多代理系统,所有这些都用于合作解决单一的全局目标函数的。仍然有许多问题需要解决,但显然,这种做法确实非常有希望取得进展。去年,我发现博弈论的变化对未来进步***指导意义。在今年,我们将看到更多探索多代理系统的松散耦合尝试。