随着深度学习在大规模图像分类数据集上获得巨大成功,越来越多的公司将业务聚焦在图像处理的计算机视觉领域,其中一个关键技术就是图像OCR(optical character recognition,光学字符识别)。
什么是OCR呢?
OCR是指光学设备(扫描仪、数码相机等)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程,其本质就是利用光学设备去捕获图像并识别文字,将人眼的能力延伸到机器上。
OCR在物流、医疗、金融、保险、传统制造业等领域都有着广泛的应用。如此多的领域朝着智能化和物流数字化方向发展,都要求具有高效稳健的OCR技术,通过机器自动识别图片文字的智能化应用前景十分可观。但是图片(包括扫描件和手机照片)往往存在噪声、倾斜、变形、背景复杂、文字多样等各种问题,文字定位和识别的难度很大。华为大数据&AI团队通过强力投入,研发出华为自己的OCR拳头产品。重点应用场景之一是表格单据的识别,通过结构化输出表格单据中的文字信息,在业务审核中给公司节省大量的人力。
华为OCR依托于华为云强大的计算和处理能力,将陆续推出单据类、证件类和通用文本的文字检测和识别服务。
价值在哪?
华为公司在全球每年有几百万份销售订单,使得每年需要处理上百万份单据。现在的单据处理方式还停留在通过人工方式将单据内容手动录入到系统中,人工录入的方式除了效率低以外,还存在员工疏忽或者疲劳导致的误操作。如何快速、准确的处理如此数量庞大的单据成为了一大诉求。通过该OCR技术自动采集关键数据,建立数据资产,并进行大数据分析,可以有效降低华为的运营成本,提升业务效率。通过智能化服务,可帮助华为在全球节省大量人力;分析海关估价等关键信息,控制每年千万美金级的风险敞口,业务流程自动化比例大幅提升。
不仅限于华为内部,华为OCR有效利用华为云计算的优势,基于松耦合、高复用性和易于维护的原则,建设了OCR公有云服务,以统一的网络访问接口方式,对外部应用系统提供满足不同需求的OCR识别服务,可以为医疗、海关、物流、金融、传统制造业等领域的企业提供高效、低成本的数据采集方案,大大节省了人工数据采集、构建信息系统和维护升级的成本,让企业更智能。目前,在金融领域,华为为某知名保险公司提供保单识别、医疗单据识别,帮助保险公司提高工作效率,加快理赔的速度;在传统制造业领域,华为帮助某公司识别药品说明书,帮助公司快速构建药品说明书的信息库。
有什么难点和挑战?
华为的OCR场景包括对扫描的表格单据、手机拍摄的照片进行文字信息提取和识别,考虑到客户和应用场景的多样性,主要面临以下挑战:
- 扫描的单据往往存在虚线干扰、版面缺失、倾斜、暗光、扭曲、噪声等情况,定位难度大。
- 文字千变万化,例如字体、字号、颜色、笔画宽度等不固定,方向任意;小数点、近似英文数字、特殊符号、连接词、艺术字等,容易被漏检或误识别。
- 语言种类繁多,经常是中英文混合,多种语言混合等场景,识别难度加大。
- 表格单据经常存在盖章(印章覆盖文字)、错行(文字溢出表格单元,与表格线交叉)的情况,也造成文字识别干扰,极大影响识别准确率。
- 拍照上传的图片存在噪声、模糊、光线变化、形变、复杂背景干扰等问题,对文字定位和识别的准确度是巨大挑战。
华为有什么关键技术?
对于上述挑战,华为OCR的总体技术方案包括图像预处理、业界领先的深度学习文字定位和文字识别引擎以及后处理纠错模块3部分,并对各个模块进行技术突破,取得了明显的效果:
- 图像预处理技术:针对盖章和错行的问题,通过对Autoencoder自编码器模型的大幅改进,直接分离文字、表格线与盖章3种目标,消除了表格线和盖章对文字的干扰,同时消除噪声,极大简化了后续的文字识别和版面分析过程,提高了准确度。该模型采用FCN(Fully Convolutional Network,全卷积网络)网络结构,并将原始图片输入层与后面多层直接相连,减少信息损失和文字变形。该模型能适应各种尺寸的图片输入,训练和预测速度都很快。
- 文字定位技术:
- 表单文字定位:在处理表单类文本识别场景,采用倾斜矫正算法、最大轮廓提取算法、表格线去干扰算法和文字框定位算法等多种技术手段相互融合。
- 证件文字定位:为支持各种复杂场景下的证件OCR,采用基于深度学习和全卷积网络的关键点定位技术将证件从各种复杂背景中提取出来,并进行方向和透视角度的矫正;然后将文字定位转换成对物体检测问题,改进SSD物体检测框架,以适应文字长宽比极大的特点;采用多尺度输入的方法,进一步提高文字定位的精度。
- 基于视觉注意力的深度学习文字识别技术:采用视觉注意力模型(CNN+LSTM+Attention技术),该模型首先在图像上采用滑动窗口CNN(Convolutional Neural Network,卷积神经网络)的方法进行图像特征提取;然后在CNN的顶部堆叠一个LSTM(Long Short-Term Memory networks,长短期记忆网络)进行序列特征提取;最后,使用注意力模型作为解码器输出最终的文字序列。
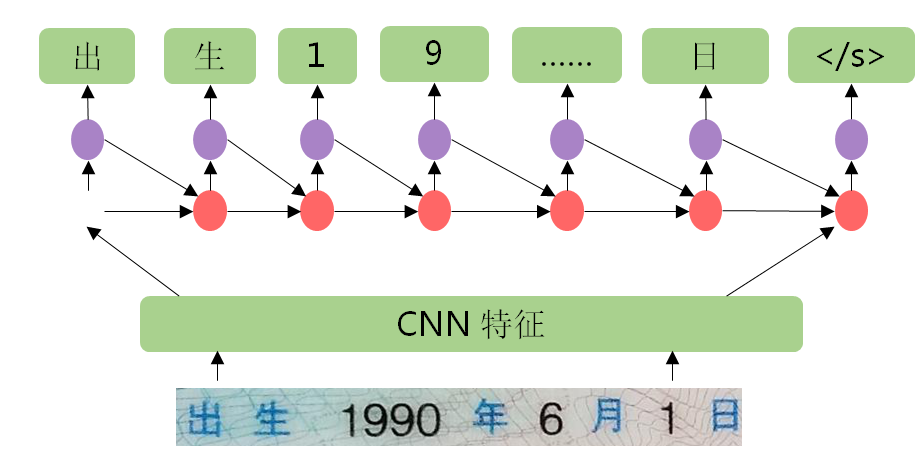
图1基于视觉注意力的深度学习文字识别技术
- 多策略后验纠错技术:对于固定模板的表单或证件,采用词库+编辑距离+集成学习的策略,对常见词进行词典库数据收集,采用编辑距离进行更正。对关键数字部分,采取多个图像预处理手段进行集成学习给出最终结果置信度,并进行可能出错的报警;对于通用的文字识别,特别是中文长句识别,对OCR识别出的Top N结果,采用语言模型+Viterbi算法,计算最短路径,输出概率最高的结果。

图2表格单据OCR解决方案
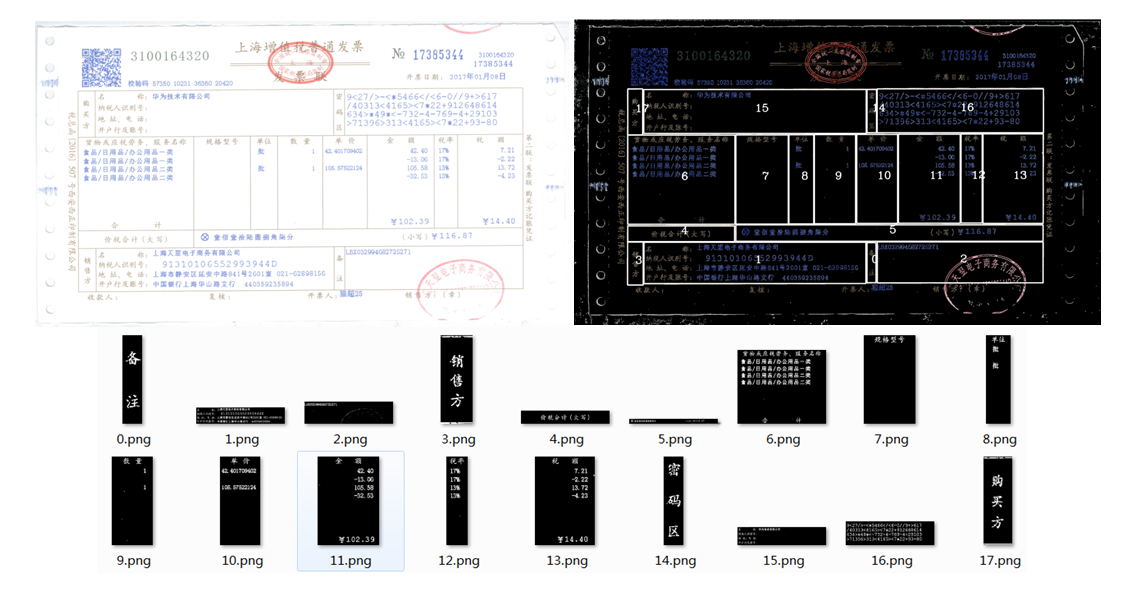
图3发票的定位效果
服务优势
- 识别精度高:采用业界先进的深度学习模型以及迁移学习模型优化技术,万亿级海量训练样本,识别率和召回率达到业界领先水平。
- 鲁棒性好:产品采用黑边处理、自动纠偏、去噪、图像自动旋转、多种二值化等方法处理图像,能适应任意版面/旋转/扭曲/复杂背景/光照/模糊场景下的文字检测识别。
- 支持多类单据识别:支持多种类型的表格、发票等单据识别,结构化输出,帮助客户快速便捷的完成纸质单据的电子化;也可为客户定制各种个性化的OCR服务,满足不同客户的需求。
- 服务稳定高效:采用最新的大数据集群技术,后台服务器稳定可靠,系统毫秒级响应。
- 云服务,标准API支持:服务使用简单便捷,兼容性强。
我们下一步将有什么?
目前华为还在布局各类证件、通用文字识别等相关的OCR产品,将会陆续提供更丰富的OCR服务和基于OCR的解决方案,支持更多应用场景,满足更多客户的需求。例如,通过拍照扫描等方式,提供身份信息的快速自动录入体验,以提高边检/酒店/旅游/公共安全以及电商等行业领域的工作效率;自然场景OCR可以捕获现实中多种场景下的文字,可有效支持虚拟现实、人机交互、图像检索、无人驾驶、车牌识别、工业自动化等领域中广泛的应用。