麻文华,博士毕业于中国科学院自动化研究所模式识别与人工智能专业。主要从事图像识别、目标检测跟踪等理论和应用研究,在领域内重要学术会议、期刊上发表论文4篇,申请相关专利2项。工作期间曾从事OCR、自然场景OCR应用研究,提出基于文字背景区域检测和自适应分级聚类的文字检测方法,研究成果申请美国专利2项,日本专利2项,中国专利5项。目前主要从事证件识别、自然场景文本识别等研究工作。
研究背景
随着便携式拍摄设备的普及以及自媒体、网络直播平台的兴起,数字视频迎来了爆炸式的增长。视频的有效编目和检索成为迫在眉睫的需求。然而,视频来源多种多样,很多并不具备规范化的描述信息(比如字幕文件)。基于纯粹的图像识别技术理解视频内容需要跨越 图像到语义理解的鸿沟,目前的技术尚不完善。另一方面,视频中的字幕往往携带了非常精准关键的描述信息,从识别字幕的角度去理解视频内容成为了相对可行的途径。
识别字幕文本通常需要两个步骤:字幕定位、文本识别。
字幕定位,即找出字幕在视频帧中所处的位置,通常字幕呈水平或竖直排列,定位的结果可以采用最小外接框来表示,如图1所示。字幕文本识别,即通过提取字幕区域的图像特征,识别其中的文字,最终输出文本串。
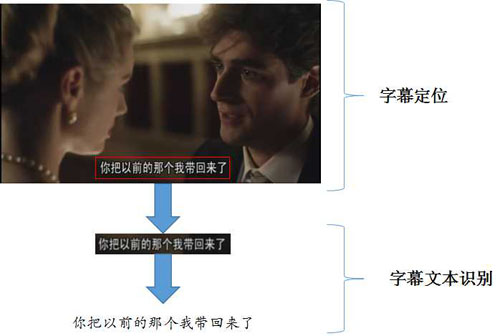
图1:视频字幕识别的一般流程
技术路线
字幕定位
字幕定位需要区分字幕区域和背景区域,有效的区分特征包括以下几点:
- 字幕的颜色、字体较为规整,且与背景有较为明显的颜色差异;
- 字幕区域的笔画丰富,角点和边缘特征比较明显;
- 字幕中字符间距固定,排版多沿水平或竖直方向;
- 同一视频中字幕出现的位置较为固定,且同一段字幕一般会停留若干秒的时间。
这其中,前三点是字幕外观特征,第四点是时间冗余性的特征。利用这些特征,一种可行的字幕定位方案如下:

图2:基于边缘密度的字幕定位
首先,对于视频帧灰度图像进行边缘检测,得到边缘图。
然后,在边缘图上分别进行水平和竖直方向的投影分析,通过投影直方图的分布,大致确定字幕的候选区域。如果存在多个候选区域,则根据字幕区域的尺寸和宽高比范围滤除不合理的检测结果。最后,通过多帧检测结果对比融合,进一步去除不稳定的检测区域。这样,基本可以得到可信的检测结果。
在某些复杂场景下,上述方法检测的区域可能会存在字幕边界检测不准的情况,尤其是垂直与字幕方向的两端边界。这时,可以进一步借助连通域分析的方法,求出字幕所在行区域的连通域,通过连通域的颜色、排列规整性来微调检测结果。
字幕文本识别
字幕文本识别通常采用的方法是首先根据行区域内的灰度直方图投影,切分单字区域,然后针对每个单字区域进行灰度图像归一化、提取梯度特征、多模版匹配和MCE(最小分类误差)分类。然而这种传统的基于特征工程的分类识别方法难以应对背景纹理复杂,以及视频本身的噪声和低分辨率等问题。
一种改进的思路是采用基于深度学习的端到端的串识别方案:CRNN (Convolutional Recurrent Neural Network)。其方法流程如图3所示:
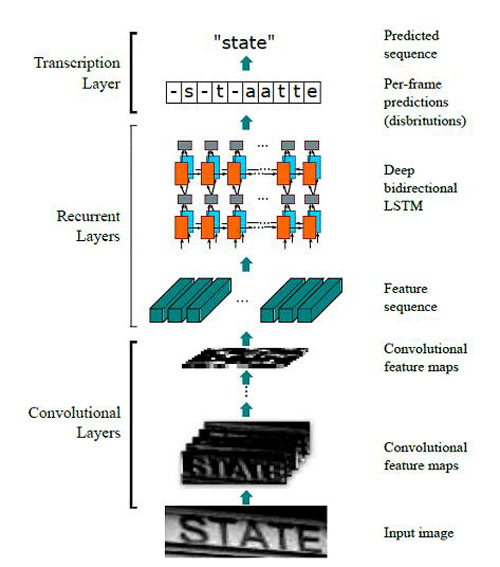
图3:CRNN实现end-to-end word recognition
首先,输入高度固定、宽度不限的单词图像(无需单字区域信息),在训练过程中,将图像统一归一化到32*100;
然后,通过CNN层提取图像特征,利用Map-to-Sequence形成特征向量,输出![]() 为的feature map。这里,
为的feature map。这里,![]() 和
和![]() 与输入图像的尺寸成比例相关。论文中,feature map的尺寸为:
与输入图像的尺寸成比例相关。论文中,feature map的尺寸为:
![]() 。这相当于对图像进行了过切分,将其划分为26个条状区域,每个区域用512维的特征来表示。其中,26被认为是英文单词的长度上限。值得一提的是,由于卷积性质,这里的条状区域是“软边界”且存在交叠的,其宽度对应最后一层卷积的感受野。
。这相当于对图像进行了过切分,将其划分为26个条状区域,每个区域用512维的特征来表示。其中,26被认为是英文单词的长度上限。值得一提的是,由于卷积性质,这里的条状区域是“软边界”且存在交叠的,其宽度对应最后一层卷积的感受野。
接着,通过RNN层提取条状区域的上下文特征,得到类别概率分布。这里采用的是双层双向的LSTM,LSTM的单元个数与![]() 一致。RNN的输出为
一致。RNN的输出为![]() 的概率矩阵,其中,
的概率矩阵,其中,![]() 对应于类别个数,考虑26个英文字母+10个数字+1个负类(对应于字母之间的模糊地带),类别个数取37即可。
对应于类别个数,考虑26个英文字母+10个数字+1个负类(对应于字母之间的模糊地带),类别个数取37即可。
最后,通过CTC层将概率矩阵转化为对应某个字符串的概率输出。CTC层本身没有参数,它利用一种前向后向算法求解最优的label序列,使得理论上庞大的穷举计算成为可能。
从上面的分析可以看出,CRNN的亮点主要在于:将切分和识别合并为一个模块,避免了误差累积;可以端到端训练。在我们前期的实践中,发现其性能比传统方法的确有明显提升,主要表现为对于艺术字体、手写字体等切分困难情况优异的识别性能。但是,针对实际应用场景的分析让我们最终放弃了这个方案,原因有二:
时效:基于我们在英文单词上面的实验对比,CRNN的耗时约为传统方法的2~3倍,不能满足视频处理的实时性要求;
性能:CRNN擅长处理难以切分的字符串,而字幕文本间距和字体均较为规整,很少出现字间粘连的情况,所以并不能体现CRNN的优势。
综上考虑,我们最终采用笔画响应加投影统计方法进行切分,而在单字识别环节采用CNN,提升复杂场景下的识别性能。下面简单介绍该流程:
切分环节包括三个步骤:
- 求取字幕区域图像的笔画响应图;
- 统计笔画响应图水平方向的灰度投影直方图;
- 根据字幕区域的高度预估单个字符的宽度,并以此为依据,在投影直方图上寻找一系列最优切点。

图4:字幕区域的切分
切分环节给出了单个字符区域,针对该区域,采用CNN模型提取特征来进行单字识别。这里需要考虑两点:
模型选择:经过实验,包含3~5层卷积-池化单元的简单CNN模型即可将传统识别方法的性能提高10个百分点左右。当然,层次更深的网络,如resnet,会进一步提升性能。实用场景下,模型选择需要根据需求在速度和性能之间进行权衡。
数据来源:基于深度学习的方法,性能关键在于海量可靠的训练样本集。在训练过程中,我们采用的样本集在百万量级,而这些样本仅靠人工搜集和标注显然是不现实的。所以,在深度学习的多次应用中,我们均采用了合成样本训练,实际样本验证的模式,并证明了其可行性。
以合成字幕文本为例:我们通过分析字幕文件的格式,将待生成的文本写入字幕文件,通过播放视频时自动载入字幕,将文字叠加到视频上面。这样,可以同时完成数据的生成和标注。我们还根据需要定制了不同字体,添加了阴影、模糊等附加效果。这样,理论上我们就可以得到无限多的合成样本了。

图5:字幕文字样本的合成
虽然识别模块的性能强悍,但是对于形似字难免仍然存在识别错误的情况。这时就要发挥语言模型的威力了。语言模型又称为n-gram模型,通过统计词库中字的同现概率,可以确定哪个字序列出现的可能性更大。N-gram中的n代表统计的词(字)序列的长度,n越大,模型越复杂。在字幕识别系统中,我们用了最简单的2-gram模型,将最终的识别正确率又提升了2个百分点。

图6:基于语言模型的结果校正
小结
我们采用上述系统在实际视频样本上进行测试,单字识别准确率达到99%,CPU上单字识别耗时2ms,基本达到实用需求。作为对于深度学习方法应用在实际业务中的一次粗浅尝试,我们有两点心得:
关于方法选择,要从问题出发,具体分析难点在哪里,选择最简单有效的方法,避免贪大求新,本末倒置;
关于数据合成,合成数据用于训练,实际数据用于微调和测试,可谓是训练深度学习网络性价比最高的方式。当然,不需要考虑时间人力消耗的土豪随意。在操作过程中,一定要注意保持合成样本和实际样本尽量相似,可以采用多次验证调整,选择最佳的合成方法。
原文链接:http://t.cn/R0w2Z6L
作者:麻文华
【本文是51CTO专栏作者“腾讯云技术社区”的原创稿件,转载请通过51CTO联系原作者获取授权】