序言
XGBoost效率很高,在Kaggle等诸多比赛中使用广泛,并且取得了不少好成绩。为了让公司的算法工程师,可以更加方便的使用XGBoost,我们将XGBoost更好地与公司已有的存储资源和计算平台进行集成,将数据预处理、模型训练、模型预测、模型评估及可视化、模型收藏及分享等功能,在Tesla平台中形成闭环,同时,数据的流转实现了与TDW完全打通,让整个机器学习的流程一体化。
XGBoost介绍
XGBoost的全称为eXtreme Gradient Boosting,是GBDT的一种高效实现,XGBoost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。
什么是GBDT?
- GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就和SVM一起被认为是泛化能力(generalization)较强的算法。GBDT的核心在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。与随机森林不同,随机森林采用多数投票输出结果;而GBDT则是将所有结果累加起来,或者加权累加起来。
XGBoost对GBDT的改进
1 . 避免过拟合
目标函数之外加上了正则化项整体求***解,用以权衡目标函数的下降和模型的复杂程度,避免过拟合。基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
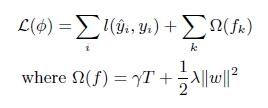
2 . 二阶的泰勒展开,精度更高
不同于传统的GBDT只利用了一阶的导数信息的方式,XGBoost对损失函数做了二阶的泰勒展开,精度更高。
第t次的损失函数:
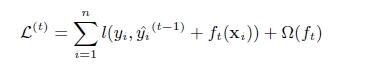
对上式做二阶泰勒展开( g为一阶导数,h为二阶导数):
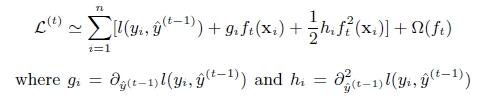
3 . 树节点分裂优化
选择候选分割点针对GBDT进行了多个优化。正常的树节点分裂时公式如下:
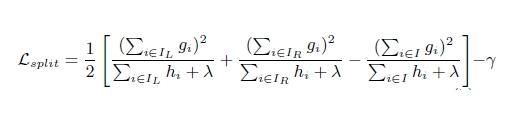
XGBoost树节点分裂时,虽然也是通过计算分裂后的某种值减去分裂前的某种值,从而得到增益。但是相比GBDT,它做了如下改进:
- 通过添加阈值gamma进行了剪枝来限制树的生成
- 通过添加系数lambda对叶子节点的值做了平滑,防止过拟合。
- 在寻找***分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,XGBoost实现了一种近似的算法,即:根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出***的分割点。
- 特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。
整体上,通过上述的3个优化,加上其易用性,不太需要编程,XGBoost目前是GBDT体系中***的工具。但是值得留意的是,当数据量很大,尤其是维度很高的情况下,XGBoost的性能会下降较快,这时推进大家可以试试腾讯自己的Angel,其GBDT比XGBoost性能更好噢
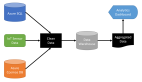
TDW体系中的XGBoost介绍
XGBoost在TDW体系中以两种形式存在
提供出了拖拽式的组件,来简化用户使用成本
提供出了maven依赖,来让用户享受Spark Pipeline的流畅
1. Tesla平台上的3个组件:
- XGBoost-spark-ppc组件(基于社区版0.7,以Spark作业形式运行在PowerPC机型的集群上)
- XGBoost-spark-x86组件(基于社区版0.7,以Spark作业形式运行在x86机型的集群上)
- XGBoost-yarn组件(基于社区版0.4,以Yarn作业形式运行在x86机型的集群上)
目前来看,XGBoost的ppc版本,性能比x86的好,建议大家优先选择。
2. 公司Maven库中的3个依赖:
XGBoost4j-ppc(封装社区版0.7的API,在PowerPC机型上进行的编译)
XGBoost4j-x86(封装社区版0.7的API,在x86机型上进行的编译)
XGBoost4j-toolkit(封装HDFS IO、TDW IO、Model IO等功能)
Tesla中的XGBoost-on-spark组件介绍
Tesla中XGBoost-on-spark组件根据集群的机型区分成:XGBoost-spark-ppc组件和XGBoost-spark-x86组件。将以前的XGBoost-yarn组件进行了升级,体现在了:
数据源之间的打通、作业调试更友好、IO方式更丰富、数据处理的上下游延伸更广、model支持在线服务等方面。
1.数据源之间的打通
消除了不同HDFS集群上的权限问题
与TDW打通,数据流转更顺畅,开发成本更低
- 用户可以不再编写程序生成LibSVM格式的数据文件,而是通过Hive或者Spark SQL生成TDW特征表,通过选择TDW特征表的某些列(selected_cols=1-2,4,8-10),由XGBoost-on-spark组件后台生成libsvm类型的输入
- 可以针对TDW分区表,借助Tesla作业定时调度机制,可以进行XGBoost作业的例行化调度运行
2.作业调试更友好
以Spark作业的形式,而非直接的Yarn作业的形式运行,用户对作业的运行情况更清楚
- 可以查看作业的进度
- 可以查看各节点上的日志信息
3.IO方式更丰富
输入的数据集来源,可以为之前的HDFS上LibSVM格式的文件形式。也可以为一张TDW表,用户通过选择TDW表中的某些列,由XGBoost-on-spark组件在后台生成LibSVM格式的输入。
训练阶段增加了特征重要度(weight、gain、cover)的输出、以及3种类型model的输出:文本格式(用户可以直接查看)、LocalFile的二进制格式(用户可以下载到本地,利用python加载后在线预测)、HadoopFile的二进制格式(用户可以在Tesla环境中,利用Spark加载后离线批量预测)
模型输出的3种格式举例
4 . 数据处理的上下游延伸更广
与Tesla平台深度整合
- 可以拖拽Tesla的组件:数据切分、模型评估,实现数据处理的上下游功能
- 可以利用Tesla的功能:参数替换、并发设置,进行批量调参
5 . model支持在线服务
可以利用Tesla的模型服务,进行模型导出、模型部署、在线预测
总结
XGBoost是机器学习的利器,虽然小巧,但是功能强大,以其被实战检验过的高效,吸引了很多使用者。我们针对用户痛点进行了诸多改进,实现了用户在Tesla平台中更加方便的使用,大大减少了用户的开发成本,同时,我们也开放出了XGBoost API,让逻辑复杂的业务可以在自身系统中嵌入xgBoost,更加直接的对接TDW系统。后续有进一步的需求,欢迎联系Tesla团队,我们将提供更好的机器学习和数据服务。
原文链接:http://t.cn/RpkWG7c
作者:张萌
【本文是51CTO专栏作者“腾讯云技术社区”的原创稿件,转载请通过51CTO联系原作者获取授权】