除非你过去几年一直隐居,远离这个计算机的世界,否则你不可能没有听过Hadoop。
全名Apache Hadoop,是一个在通用低成本的硬件上处理存储和大规模并行计算的一个开源框架。从2011年他的面世,他已经成为大数据领域最出名的平台。
如何工作的?
Hadoop是从Google文件系统发源而来,并且他是一个用Java开发的跨平台的应用.核心组件有: Hadoop Common,拥有其他模块所依赖的库和基础工具,Hadoop分布式文件系统 (HDFS), 负责存储, Hadoop YARN, 管理计算资源, 和Hadoop MapReduce, 负责处理的过程。
Hadoop把文件拆成小块并且把他们分发给集群中的节点.然后,它使用打包的代码分发到节点上并行处理数据. 这意味着可以处理数据的速度会比使用传统的体系结构的更快.
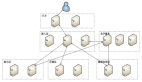
一个典型的Hadoop集群都会有主节点和从节点或者叫工作节点. 主节点有一个任务跟踪器,任务调度,名字节点和数据节点组成.从节点通常作为一个数据节点和任务调度器,不过特殊的场景下程序可能只有数据节点然后在其他的从节点进行处理计算。
在大的Hadoop集群中,通常会使用一个专用的名字节点来管理HDFS节点的文件系统索引信息。这防止了文件系统的数据丢失和损坏。
Hadoop文件系统
Hadoop分布式文件系统是Hadoop扩展的核心. HDFS当处理大数据的优点是,它可以跨多台机器存储gb或tb大小的文件. 因为数据的副本存在了多个机器上,而不是使用附加RAID来在单台机器上保证. 不过RAID还是会被用来提升性能. 提供进一步的保护,允许主NameNode服务器自动切换到备份失败的事件。
HDFS被设计成可以直接挂载在Linux系统的用户空间(FUSE)或者虚拟文件系统. 通过一个Java API来处理文件的访问权限.HDFS被设计为跨硬件平台和操作系统的可移植性。
Hadoop也能配合其他的文件系统工作 ,包括FTP, Amazon S3 和Microsoft Azure, 然而,它需要一个特定的文件系统的桥梁,以确保没有性能损失。
Hadoop 和他的云
相对传统数据中心, Hadoop也经常被部署在云上. 这样做的好处是,公司可以很容易地部署Hadoop更迅速和较低的安装费用. 大多数云供应商都提供某种形式的Hadoop部署方案。
Microsoft 提供Azure HDInsight, 允许用户使用他们所需要的节点的数量,并收取他们使用的计算能力和存储的费用. HDInsight是基于 Hortonworks 并且可以很容易地在内部系统和云备份,或开发和测试之间移动数据.
Amazon Elastic Compute Cloud (EC2) 和Amazon Simple Storage Service (S3) 也支持 Hadoop, 加上Amazon 提供了 Elastic MapReduce 产品,所以能自动化Hadoop集群的配置,作业的运行和终止以及处理EC2和S3存储之间的数据传输。
Google提供一个管理Spark和Hadoop 服务叫做Cloud Dataproc,用一系列的Shell脚本来创建和管理 Spark和Hadoop 集群.他支持第三方的Hadoop 发行版像Cloudera, Hortonworks和MapR.Google Cloud Storage 也可以和 Hadoop 配合使用.
Hadoop 近况
Hadoop已经有些初步的进展. 2015年的 Gartner study只有18%的人表示会在接下来的两年使用.不愿意采用这种技术的原因包括成本太高,相对于预期的利益, 和缺乏必要的技能。
仍然有一些高调的用户。 雅虎的搜索引擎由Hadoop驱动,公司已经通过开源社区向公众提供了其使用的版本的源代码。 Facebook也使用Hadoop,并且在2012年该公司宣布其集群具有100PB的数据,并且每天增长约为一个PB。
尽管初始占有慢,Hadoop也在增长。 Allied Market Research在2016年初的一项调查估计,到2021年Hadoop市场的收入将超过840亿美元。
由于Hadoop工作的方式,看到了一些回归到旧时代批处理信息的东西。 虽然从大量历史数据中提取洞察力很有用,但对于实时应用程序或连续传入的数据流有效性较低。
特性
Hadoop一直与大数据密切相关。随着物联网设备的扩展以及收集的数据量增加,因而Hadoop的处理能力需求也将增加。其快速处理大数据的能力意味着Hadoop系统对于做日常业务决定起着越来越重要的作用。
各种规模的组织都热衷于使用大数据。Hadoop开源的特性以及其在商业硬件上运行的能力意味着其处理能力不仅在大型公司可用,也可以帮助大众使用大数据。
对于所有这些运作成功的公司需要能够利用Hadoop可以提供的优势。 这意味着需要解决技能差距,并且可能仍然需要那些掌握Java,Linux,文件系统和数据库背景的员工,这些员工能够快速获得Hadoop技能。 这也意味着越来越多地使用云以一种不太复杂的方式提供Hadoop的优势。