写在前面
前几天工作时遇到了一个匪夷所思的问题。经过几次尝试后问题得以解决,但问题产生的原因却仍令人费解。查找 SO 无果,我决定翻看 Python 的源码。断断续续地研究了几天,终于恍然大悟。撰此文以记。
本文环境:
- Ubuntu 16.04 (64 bit)
- Python 3.6.2
使用的 C 源码可以从 Python 官网 获取。
起因
工作时用到了 celery 作为异步任务队列,为方便调试,我写了一个脚本用以启动/关闭 celery 主进程。代码简化后如下:
- import sys
- import subprocess
- # ...
- celery_process = subprocess.Popen(
- ['celery', '-A', 'XXX', 'worker'],
- stdout=subprocess.PIPE,
- stderr=sys.stderr
- )
- try:
- # Start and wait for server process
- except KeyboardInterrupt:
- # Ctrl + C pressed
- celery_process.terminate()
- celery_process.wait()
代码启动了 celery worker,并尝试在捕获到 KeyboardInterrupt 异常时将其热关闭。
初看上去没什么问题。然而实际测试时却发生了十分诡异的事情:按下 Ctrl+C 后,程序 偶尔 会抛出这样的异常:RuntimeError: reentrant call inside <_io.BufferedWriter name='<stdout>’>。诡异之处有两点:
异常发生的时机有随机性
异常的 traceback 指向 celery 包,也就是说这是在 celery 主进程内部发生的异常
这个结果大大出乎了我的意料。随机性异常是众多最难缠的问题之一,因为这常常意味着并发问题,涉及底层知识,病灶隐蔽,调试难度大,同时没有有效的手段判断问题是否彻底解决(可能只是降低了频率)。
解决
异常信息中有两个词很关键:reentrant 和 stdout。reentrant call 说明有一个不可重入的函数被递归调用了;stdout 则指明了发生的地点和时机。初步可以判定:由于某种原因,有两股控制流在同时操控 stdout。
“可重入”是什么?根据 Wikipedia 的定义:如果一个子程序能在执行时被中断并在之后被正确地、安全地唤起,它就被称为可重入的。依赖于全局数据的过程是不可重入的,如 printf(依赖于全局文件描述符)、malloc(依赖与和堆相关的一系列数据结构)等函数。需要注意的是,可重入性(reentrant)与 线程安全性(thread-safe)并不等价,甚至不存在包含关系,Wikipedia 中给出了相关的反例。
多次尝试后,出现了一条线索:有时候 worker: Warm shutdown (MainProcess) 这个字符串会被二次打印,时机不确定。这句话是 celery 将要热关闭时的提示语,二次出现只可能是主进程收到了第二个信号。阅读 celery 的文档 可知,SIGINT 和 SIGTERM 信号可以引发热关闭。回头浏览我的代码,其中只有一处发送了 SIGTERM 信号(celery_process.terminate()),至于另一个神秘的信号,我怀疑是 SIGINT。
SO 一下,结果印证了我的猜想:
If you are generating the SIGINT with Ctrl-C on a Unix system, then the signal is being sent to the entire process group.
— via StackOverflow
SIGINT 信号不仅会发送到父进程,而是会发到整个进程组,默认情况下包括了所有子进程。也就是说——在拦截了 KeyboardInterrupt 之后执行的 celery_process.terminate() 是多此一举,因为 SIGINT 信号也会被发送至 celery 主进程,同样会引起热关闭。代码稍作修改即可正常运行:
- # ...
- try:
- # Start and wait for server process
- except KeyboardInterrupt:
- # Ctrl + C pressed
- pass
- else:
- # Signal SIGTERM if no exception raised
- celery_process.terminate()
- finally:
- # Wait for it to avoid it becoming orphan
- celery_process.wait()
猜测
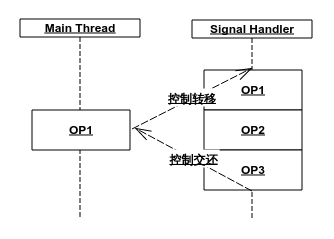
UNIX 信号处理是一个相当奇葩的过程——当进程收到一个信号时,内核会选择一条线程(以一定的规则),中断其当前控制流,将控制流强行转给信号处理函数,待其执行完毕后再将控制流交还给原线程。时序图如下:
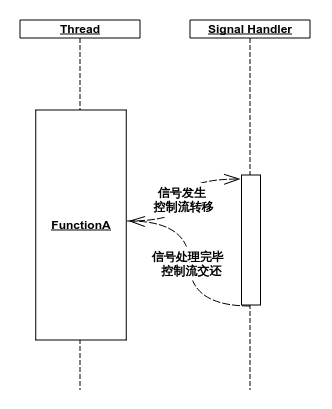
由于控制流转换发生在同一条线程上,许多线程间同步机制会失效甚至报错。因此信号处理函数的编写要比线程函数更加严格,对同一个文件输出是被禁止并且无解的,因为很可能会发生这样的事情:
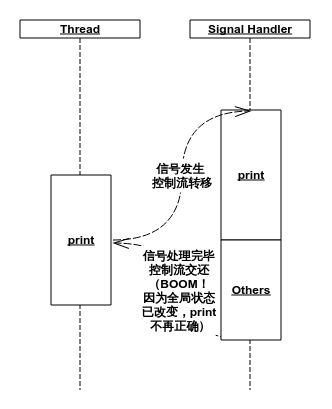
而且这个问题不能通过加锁来解决(因为是在同一个线程中,会死锁)。
因此,我猜测异常发生时的事件时序是这样的:在 print 未执行完时中断,又在信号处理函数中调用 print,触发了重入检测,引起 RuntimeError:
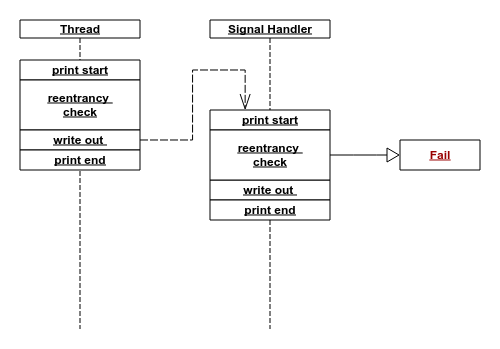
疑云又起
不幸的是,我的猜想很快被推翻了。
在翻看 Python signal 模块的官方文档,我看到了如下叙述:
A Python signal handler does not get executed inside the low-level (C) signal handler. Instead, the low-level signal handler sets a flag which tells the virtual machine to execute the corresponding Python signal handler at a later point(for example at the next bytecode instruction).
— via Python Documentation
也就是说,Python 中使用 signal.signal 注册的信号处理函数并不会在收到信号时立即执行,而只是简单做一个标记,将其延迟至之后的某个时机。这么做可以尽量快地结束异常控制流,减少其对被阻断进程的影响。
这番表述可以说是推翻了我的猜想,因为 Signal Handler 中的 print 并没有在异常控制流中执行。那异常又是怎么产生的呢?
文档说 Python Signal Handler 会被延后至某个时机进行,但并没有明示是什么时候。对于这个疑问,这个提问的被采纳回答 则斩钉截铁地将其具体化到了“某两个 Python 字节码之间”。
我们知道,Python 程序在执行前会被编译成 Python 内定的字节码
(bytecode),Python 虚拟机实际执行的正是这些字节码。倘若该回答是正确的,则立即有如下推论:在处理信号的过程中,字节码具有原子性(atomic)。也就是说,主线程总是在两个字节码之间决定是否转移控制流, 而 不会 出现以下情况:
这很显然与我的程序结果相悖:print 与 print 所调用的 io.BufferedWriter.write 和 io.BufferedWriter.flush 都是用纯 C 代码编写的,对其的调用只消耗一条字节码(CALL_FUNCTION 或 CALL_FUNCTION_KW),在信号中断的影响下,这几个函数仍保持原子性,在时序图上互不重叠,更不会发生重入。
因此,除了在两个字节码之间,应该还有其他时机唤起了 Python Signal Handler。
至此,问题已触及 Python 的地板了,需向更底层挖掘才能找到答案。
深入源码
信号注册逻辑位于 Modules/signalmodule.c 文件中。 313 行的 signal_handler 是信号处理函数的最外层包装,由系统调用 signal 或 sigaction 注册至内核,并在信号发生时被内核回调,是异常控制流的入口。signal_handler 主要调用了 239 行处的 trip_signal 函数,其中有这样一段代码:
- Handlers[sig_num].tripped = 1;
- if (!is_tripped) {
- is_tripped = 1;
- Py_AddPendingCall(checksignals_witharg, NULL);
- }
这段代码便是文档中所说的逻辑:做标记并延后 Python Signal Handler。其中 checksignals_witharg 即为被延后调用的函数,位于 192 行,核心代码只有一句:
- static int
- checksignals_witharg(void * unused)
- {
- return PyErr_CheckSignals();
- }
- r_CheckSignals 位于 1511 行:
- int
- PyErr_CheckSignals(void)
- {
- int i;
- PyObject *f;
- if (!is_tripped)
- return 0;
- #ifdef WITH_THREAD
- if (PyThread_get_thread_ident() != main_thread)
- return 0;
- #endif
- is_tripped = 0;
- if (!(f = (PyObject *)PyEval_GetFrame()))
- f = Py_None;
- for (i = 1; i < NSIG; i++) {
- if (Handlers[i].tripped) {
- PyObject *result = NULL;
- PyObject *arglist = Py_BuildValue("(iO)", i, f);
- Handlers[i].tripped = 0;
- if (arglist) {
- result = PyEval_CallObject(Handlers[i].func, arglist);
- Py_DECREF(arglist);
- }
- if (!result)
- return -1;
- Py_DECREF(result);
- }
- }
- return 0;
- }
可见,这个函数便是异步回调的最里层,包含了执行 Python Signal Handler 的逻辑。
至此我们可以发现,整个 Python 中有两个办法可以唤起 Python Signal Handler,一个是调用 checksignals_witharg,另一个是调用 PyErr_CheckSignals。前者只是后者的简单封包。
checksignals_witharg 在 Python 源码中只出现了一次(不包括定义,下同),没有被直接调用的迹象。但需要注意的是,checksignals_witharg 曾被当做 Py_AddPendingCall 的参数,Py_AddPendingCall 所做的工作时将其加入到一个全局队列中。与之对应的出队操作是 Py_MakePendingCalls,位于 Python/ceval.c 的 464 行。此函数会间接调用 checksignals_witharg,在 Python 源码中被调用了 3 次:
- Modules/_threadmodule.c 52 行的 acquire_timed
- Modules/main.c 310 行的 run_file
- Python/ceval.c 722 行的 _PyEval_EvalFrameDefault
值得注意的是,_PyEval_EvalFrameDefault 是一个长达 2600 多行的状态机,是解析字节码的核心逻辑所在。此处调用出现于状态机主循环开始处——这印证了上面回答中的部分说法,即 Python 会在两个字节码中间唤起 Python Signal Hanlder。
而 PyErr_CheckSignals 在 Python 源码中出现了 80 多处,遍布 Python 的各个模块中——这说明该回答的另一半说法是错误的:除了在两个字节码之间,Python 还可能在其他角落唤起 Python Signal Handler。其中有两处值得注意,它们都位于 Modules/_io/bufferedio.c 中:
- 1884 行的 _bufferedwriter_flush_unlocked
- 1939 行的 _io_BufferedWriter_write_impl
这两个函数是 io.BufferedWriter 类的底层实现,会被 print 间接调用。仔细观察可以发现,它们都有着相似的结构:
- ENTER_BUFFERED(self)
- // ...
- PyErr_CheckSignals();
- // ...
- LEAVE_BUFFERED(self)
ENTER_BUFFERED 是一个宏,会尝试申请无阻塞线程锁以保证函数不会被重入:
- #define ENTER_BUFFERED(self) \
- ( (PyThread_acquire_lock(self->lock, 0) ? \
- 1 : _enter_buffered_busy(self)) \
- && (self->owner = PyThread_get_thread_ident(), 1) )
至此,真相已经大白了。
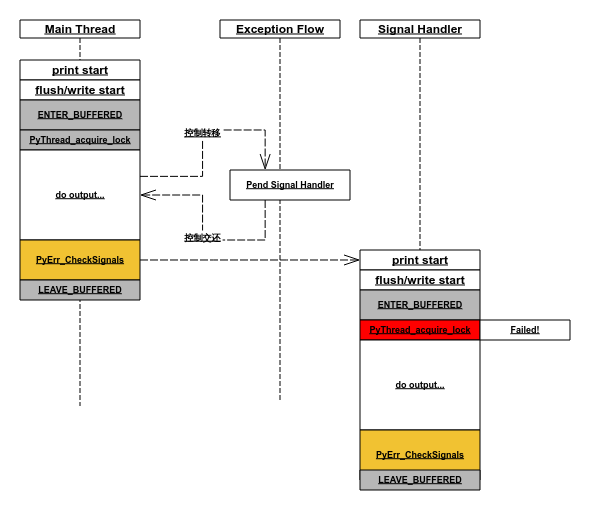
真相
当信号中断发生在 _bufferedwriter_flush_unlocked 或 _io_BufferedWriter_write_impl 中时,这两个函数中的 PyErr_CheckSignals 会直接唤起 Python Signal Handler,而此时由 ENTER_BUFFERED 上的锁尚未解开,若 Python Signal Handler 中又有 print 函数调用,则会导致再次 ENTER_BUFFERED 上锁失败,从而抛出异常。时序图如下:
思考
为什么不将 Python Signal Handler 调用的地点统一在一个地方,而是散布在程序的各处呢?阅读相关代码,我认为有两点原因:
信号中断会使某些系统调用行为异常,从而使系统调用的调用者不知如何处理,此时需要调用 Signal Handler 进行可能的状态恢复。一个例子是 write 系统调用,信号中断会导致数据部分写回,与此相关的一大批 I/O 函数(包括出问题的 _bufferedwriter_flush_unlocked 和 _io_BufferedWriter_write_impl)便只能相应地调用 PyErr_CheckSignals。
某些函数需要做计算密集型任务,为了防止 Python Signal Handler 的调用被过长地延后(其实主要是为了及时响应键盘中断,防止程序无法从前台结束),必须适时地检查并调用 Python Signal Handler。一个例子是 Objects/longobject.c 中的诸函数,longobject.c 定义了 Python 特有的无限长整型,其相关的运算可能耗时相当长,必须做这样的处理。
总结
Python Signal Handler 的调用会被延后,但时机不止在两个字节码之间,而是可能出现在任何地方。
由于第一条,Python Signal Handler 中尽量都使用 可重入的 的函数,以避免奇怪的问题。可重入性可以从文档获知,也可以结合定义由源码推断出来。
有疑问,翻源码。人会说谎,代码不会。