摘要:告别传统模式,科技公司搞机器学习需要哪些必备技能?
主流的科技公司已在积极地把自己定位成AI或者机器学习公司:谷歌把“AI先行”作为公司战略,Uber自带机器学习的血统,而各种AI研究实验室更是层出不穷。
这些公司都在想尽办法说服世界,“机器智能的革命时代正在到来”。它们尤其强调深度学习,因为这些都在推动自驾汽车、虚拟助手等概念的发展。
尽管现在这些概念很流行,然而当下的实践却没那么乐观。
现在,软件工程师和数据科学家仍在使用许多几年前的算法和工具。
这也意味着,传统的机器学习模式仍在支撑着大多数AI的应用,而不是深度神经网络。工程师仍然用传统工具来处理机器学习,但是这并不起作用:采用数据建模的流水线最终由零散、不兼容的片段构成。这种情况在逐渐变化,因为大型科技公司正在研发具有端到端功能的特定机器学习平台。
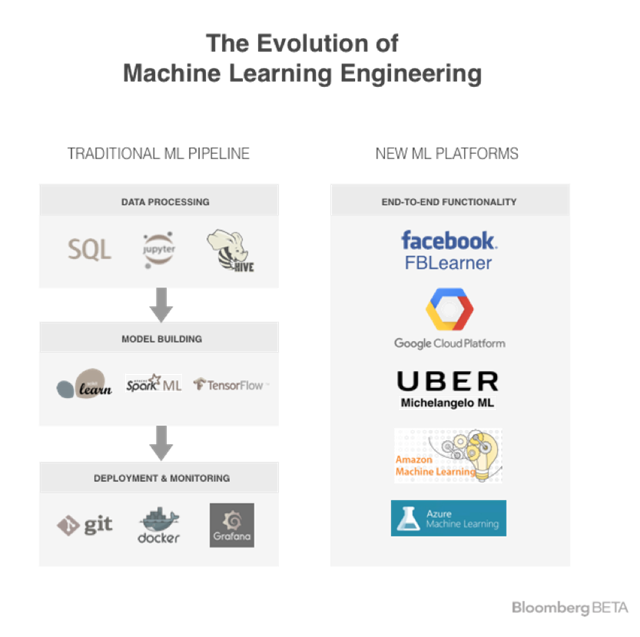
机器学习“三明治”中夹了什么?
机器学习构建有三个阶段——数据处理阶段、模型建构阶段、部署及监控阶段。在中间阶段是最美味的,就像三明治中夹的肉,这也是机器学习算法是怎么学习预测输入数据的。
这个模型同样是“深度学习”的模型。深度学习是机器学习算法的一个子类别,它使用多层神经网络来学习输入和输出之间的复杂关系。神经网络中的层次越多,其复杂性就越高。
传统的数据式机器学习算法(即那些不用深度神经网络的算法)仅能有限地捕捉信息和训练数据。大多应用仅采用更基本的机器学习算法就可以有效的运作,相比之下深度学习的复杂性往往显得是多余。所以我们仍然看到软件工程师在大规模地使用这些传统模式,即使是在深度学习领域。
但是这个“三明治”流程也能将机器学习训练前后的结果连接在一起。
***阶段把涉及到清理和格式化之前的大量数据放入模型。***一个阶段是对模型进行仔细的部署和监控。我们发现大部分AI的工作时间并未放在构建机器学习模型上,而是在准备和监控这些模型。
- 机器学习“三明治”里的肉:避免异国风味
尽管现在大型科技公司AI研究实验室的焦点都是深度学习,大多数机器学习的应用却并不依赖深度神经网络,而仍采用传统机器学习的模式。最常见的包括线性/逻辑回归模型,组合树算法和增强决策树模型。这些模型背后,蕴含着其他科技公司的应用、朋友的建议、市场定位、用户兴趣预测,需求/供应模型和搜索结果排名等。
而工程师训练这些模型的工具也十分老旧。最常用的机器学习库是十年前发行的scikit-learn(尽管谷歌TensorFlow的使用者越来越多)。
人们用更简单的模型而非采用深度学习是有原因的。因为深度神经网络很难训练,他们需要大量的时间和计算能力(通常需要不同的硬件,特别是GPU)。想让深度学习起作用是很难的——它仍然需要大量的人工调整、直觉、实验以及试错。
在传统的机器学习模型中,工程师用于训练和调整的时间相对较短,往往只有几个小时。***,就算深度学习精准度的小幅提高,用于拓展和开发所花费的时间也远超过精准度提高的价值。
- 怎么把三明治粘在一起?从数据到部署的工具
所以当人们想培养机器学习模式的时候,传统的方式很有效。但是这不适用于机器学习的基础设施,传统方式不能将机器学习三部分粘合起来,很容易埋下犯错的隐患。
数据收集和处理解释了机器学习的***阶段。大公司一定有大量数据,数据分析师和工程师必须处理数据并利用数据,从而能验证和巩固多源的副本,将算法标准化,设计并证明各种功能。
大多数公司内,工程师使用SQL或Hive queires和Python脚本来聚集和格式化多源数据。这往往要耗费大量的人力。由于很多大公司的数据科学家或者工程师常常使用各种本地化的脚本或者Jupyter Notebook来工作,使过程分散化,导致重复性工作出现。
此外,哪怕大型高科技公司也会犯错误,必须生产过程中仔细地部署和监测模型。正如一名工程师所说:“在大型公司,80%的机器学习都由基础建设组成。”
然而,传统的单元测试,也算传统软件测试的主干,并不适合机器学习模式,因为事先并不知道机器学习模型的正确输出。毕竟,机器学习的目的是让模型学习从数据中进行预测,而不需要工程师专门编写任何规则。因此,工程师采用较少的结构化方式来代替单元测试,他们可以手动监控仪表盘,并为新模型提供报警程序。
而实时数据的转变可能会让训练有素的模型出现偏差,所以工程师会根据不同应用,每天或每月写入新数据来校准模型。但是,现有的工程基础设施缺乏特定机器学习的支持,可能会导致开发时的模型与生产时的模型之间断开连接,因为一般代码的更新频率更低。
很多工程师仍然依赖于原始的设计模型和产品生产的方式,例如工程师有时候需要重建原型,而有些数据是用其他语言或结构展现的,所以他们只能使用基础结构来开发产品。从数据整理阶段到训练阶段再到部署产品结构阶段,任何机器学习发展阶段中的不兼容都能产生错误。
- 如何呈现?前进的道路
为了解决这些问题,拥有定制化资源的几家大公司,一直在努力创造属于自己的机器学习工具。他们的目标是有一个无缝衔接、终端对终端的机器学习平台,能够与计算机完全兼容。
Facebook的FBLearner Flow和Uber的Michelangelo的内部机器学习平台都做到了这些。他们允许工程师在一个原始用户界面构造机器训练和验证数据集,从而能减少该阶段的开发时间。然后,工程师们只要点击一下鼠标,就可以训练学习模式。最终,他们可以轻松地监控和升级产品模式。
像Azure 的机器学习和Amazon的机器学习服务都公开发表过可选择的方案,提供类似端对端的功能,但只能和Amazon或微软的服务平台兼容。
尽管这些大公司都在使用机器学习来提升自己的产品,但多数仍然面临巨大挑战,并且效率低下。他们仍想用传统机器学习模式而不是更先进的深层学习模式,而且仍依赖于传统基础工具来匹配机器学习。
幸运的是,现在AI是这些公司的研究焦点,他们也在努力让机器学习变得更有效。有了这些内部工具,或者其它第三方机器学习平台的参与,能够让大家认识到AI的潜力。