













数据表类型(存储引擎)
数据库引擎用于存储、处理和保护数据的核心服务,利用数据库引擎可控制访问权限并快速处理事务,利用数据库引擎创建用于联机事务处理或联机分析处理数据的关系数据库,包括创建用于存储数据的表和用于查看、管理、保护数据安全的数据库对象(索引、视图、存储过程)。
常见引擎比对
| 特性 | Myisam | InnoDB | Memory | BDB | Archive |
|---|---|---|---|---|---|
| 存储限制 | ***制 | 64TB | 有 | 没有 | 没有 |
| 事务安全 | - | 支持 | - | 支持 | - |
| 锁机制 | 表锁 | 行锁 | 表锁 | 页锁 | 行锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 | - |
| 哈希索引 | - | 支持 | 支持 | - | - |
| 全文索引 | 支持 | - | - | - | - |
| 集群索引 | - | 支持 | - | - | - |
| 数据缓存 | - | 支持 | 支持 | - | - |
| 索引缓存 | 支持 | 支持 | 支持 | - | - |
| 数据压缩 | 支持 | - | - | - | 支持 |
| 空间使用 | 低 | 高 | N/A | 低 | 非常低 |
| 内存使用 | 低 | 高 | 中 | 低 | 低 |
| 批量插入速度 | 高 | 低 | 高 | 高 | 非常高 |
| 外键支持 | - | 支持 | - | - | - |
各引擎特点
- Myisam
mysql默认存储引擎,在磁盘上存储成三个文件.frm(存储表定义).MYD(MYData存储数据)。MYI(MYIndex存储索引);
没有事务支持,不支持行锁外键,因此当insert、update会锁定整个表,效率会低一些,MyIASM中存储了行数,如果表的读操作远大于写且不需要事务,MyISAM优选。
索引
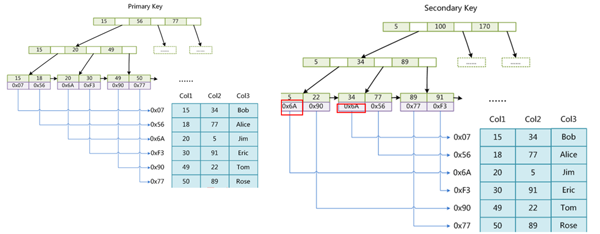
1.MyISAM引擎索引结构为B+Tree,其中B+Tree的数据域存储的为实际数据地址即索引和实际数据分开即非聚集索引。
2.如图主键索引和辅助索引结构一直只不过主键索引要求key唯一。
3.MyISAM中索引检索算法首先安装B+Tree搜索算法搜索索引,如果key存在,则取出data域的值,然后以data域的值为地址,读取相应数据记录。
- Innodb
提供了对数据库ACID事务支持并实现SQL标准的四种隔离级别,提供行级锁和外键约束。Mysql运行时Innodb会在内存中建立缓冲池用于缓冲数据和索引,该引擎不支持fulltext类型索引且没有保存表的行数,select count(*) from table 血药扫全表。
需要事务操作时Innodb***,锁力度小,写操作不会锁定权标,所以并发高时Innodb引擎效率更高,
相比Myisam写处理效率差一些会占用更多的磁盘空间保存数据和索引。
索引
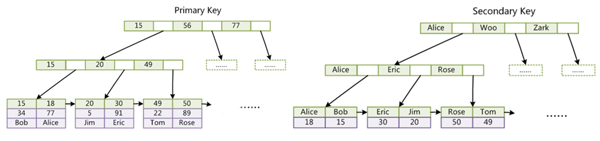
1.Innodb索引采用B+Tree且Innodb索引文件本身就是数据文件即B+Tree的数据域存储的就是实际的数据如图Primary Key即聚集索引。这个索引的key就是数据表主键,Innodb表本身就是主索引。
2.Innodb辅助索引数据域存储的是相应的主键的值而不是地址,通过辅助索引查找时先找到主键再通过主键查找数据。所以主键不建议过长否则辅助索引会变得很大。
3.Innodb必须有主键如果没有显示指定Mysql会自动选择一个唯一标识的数据记录为主键。
4.聚集索引按主键搜索效率十分高效,辅助索引必须检索两遍。
5.基于Innodb索引结构可以解释为什么不建议使用过长的主键,为什么不建议使用非单调(非递增)的记录做主键,B+Tree索引结构导致使用非单调做主键会相当低效。
常用命令
- show engines; 查看当前支持的引擎和默认引擎
- show table status from mytest; show create table tablename;查看数据表引擎
- 修改默认引擎 my.ini [mysqld]下增加 default-storage-engine=InnoDB
名词概念
- ACID: (Atomicity)原子性,要么全部执行要么不执行;(Consistency)一致性,事务的运行不改变数据库中数据的一致性;(Isolation)独立性,也称隔离性两个以上的食物不会出现交错执行的状态;(Durability)持久性,事务执行成功后数据持久保存。
- BTree 二叉搜索树
1.所有非叶子几点最多有两个子节点(left right)
2.所有节点存储一个关键字
3.非叶子节点左指针指向小于其关键字的子树,右指针指向大于其关键字的子树
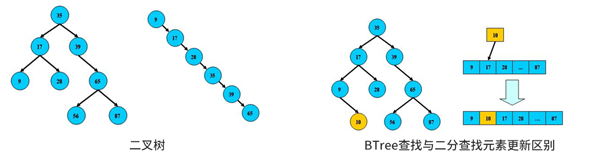
二叉树查找:从跟节点开始查询关键字与节点相等,***返回。否则查询关键字比节点小,进入左子节点否则进入右节点。如果左或右为空反馈找不到。如果树左右节点保持平衡如图1、3棵树查询性能逼近二分查找。树比二分查找的有点是数据更新时不需要移动大段内存数据如3、4图数据更新。
经过一系列的更新可能导致图2的BTree树,该树搜索成线性无查询优势,在实际使用中通常使用平衡二叉树如图1、3即“平衡二叉树”,平衡算法是一种在B树种插入和删除节点的策略。
- B-Tree 多路搜索树(非二叉树)
1.任意非叶子节点最多只有M个子节点且M>2
2.跟节点的子节点数为[2, M]
3.除跟节点外的非叶子节点的子节点树为[M/2, M]
4.每个节点存放至少M/2-1(取上整)和至多M-1个关键字(至少2个关键字)
5.非叶子节点的关键字个数=指向儿子的指针个数-1
6.非叶子节点的关键字:K[1],K[2],…,K[M-1]且K[i]<K[i+1]
7.非叶子几点的指针:P[1],P[2],…,P[M],其中P[1]指向关键字小于K[1]的子树,P[M]指向管关键字大于K[M-1]的子树,其他P[i]指向关键字属于(K[i-1], K[i])的子树
8.所有叶子节点位于同一层
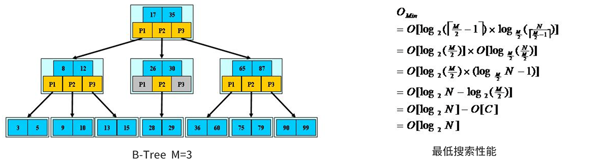
B-Tree查找:从跟节点开始,对节点内的关键字(有序)进行二分查找,***结束。否则进入查询关键字所属范围的儿子节点;重复直到空或叶子节点。
由于限制除根节点外的非叶子节点至少含有M/2个儿子,确保了节点的至少利用率所以B-Tree的性能等价于二分查找,也就没有B树平衡的问题。由于M/2的限制,插入或删除节点时需要考虑分裂和合并节点。
B-Tree特性:关键字集合分布在整科树种;任何一个关键字出现且只出现在一个节点中;搜索有可能在非叶子节点结束;搜索性能等价于在关键字全集内做一次二分查找;自动层次控制;
- B+Tree B-Tree变体多路搜索树
1.基本与B-Tree定义相同除以下外
2.非叶子节点的子树指针与关键字个数相同
3.非叶子节点的子树指针P[i]指向关键字值属于(K[i], K[i+1])的子树
4.为所有叶子节点增加一个链指针
5.所有关键字都在叶子节点出现
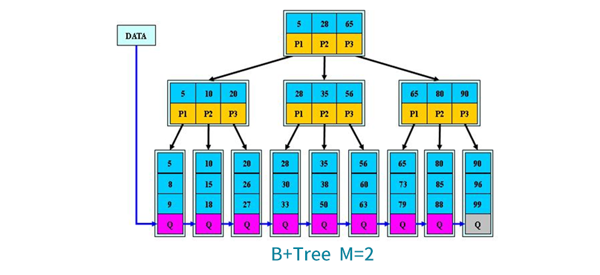
B+Tree查找:与B-Tree相同区别B+树只有达到叶子节点才***,其性能等价于关键字全集做一次二分查找。
B+Tree特性:所有关键字都出现在叶子节点链表中,链表中关键字有序;不可能在非叶子节点***;非叶子节点相当于是叶子节点的索引,叶子节点相当于是存储关键字数据的数据层;更适合文件索引系统;
- B*Tree B+Tree变体
1.在B+Tree的非跟和非叶子节点增加指向兄弟的指针
B+Tree分裂:当一个节点满时,分配一个新的节点,将原节点中1/2的数据复制到新节点,***在父节点中增加新节点指针;B+树分类只影响原节点和父节点不影响兄弟节点。
B*Tree分裂:一个节点满时,如果下一个兄弟节点未满,将一部分数据移到兄弟几点中,再在源节点插入关键字,***修改父节点中兄弟节点的关键字;如果兄弟节点也满了,则在源节点与兄弟节点之间增加新节点,并各赋值1/3的数据到新节点,***在父节点增加新节点的指针。B*Tree分配节点的概率比B+Tree要低,空间使用率高。
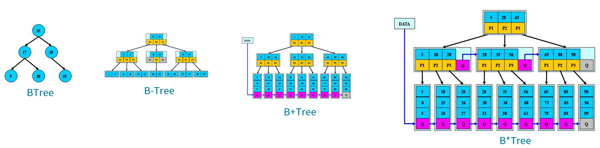
各个树比对
-
各个树比对
| 类型 | 特点 |
|---|---|
| BTree | 每个节点只存储一个关键字,等于***,小于左节点,大于右节点 |
| B-Tree | 多路搜索树,每个节点存储M/2到M个关键字,非叶子节点存储指向关键字范围的子节点,所有关键字在整棵树中出现,且只出现一次,非叶子节点可以*** |
| B+Tree | B-Tree基础上尉叶子节点增加链表指针,所有关键字都在叶子节点出现,非叶子节点作为叶子节点的索引,B+Tree叶子节点才*** |
| B*Tree | B+Tree基础上为非也自己点也增加链表指针,将节点的***利用率从1/2提高到2/3 |














