近日,Medium 上出现了一篇题为《Background removal with deep learning》的文章,讲述的是 greenScreen AI 在利用深度学习去除图像人物背景方面的工作与研究。本着开发一个有意义的深度学习产品的初衷,他们把任务锁定在了自拍和人物肖像上,并最终在已稀释的 COCO 数据集上取得了 84.6 的 IoU,而当下最佳水平是 85。

简介
在研究机器学习的最近几年里,我一直想着打造真正的机器学习产品。数月之前,在学习完 Fast.AI 上的深度学习课程之后,我清晰地意识到机会来了:深度学习技术的进步可以使很多之前不可能的事情变成现实,新工具被开发出来,它们可以让部署变的比以前更便捷。在前面提到的课程中,我结识了 Alon Burg,他是一位很有经验的网页开发者,我们达成一致来共同完成这个目标。我们一起设定了以下目标:
- 提升我们的深度学习技巧
- 提升我们的人工智能产品部署技巧
- 开发一款有用的、具有市场需求的产品
- 有趣(不仅对我们而言,也对用户而言)
- 分享我们的经验
基于以上目标,我们探索了一些想法:
- 之前没有被做过的(或是没有被正确做过)
- 规划和实现的难度不大——我们计划两到三个月完成,每周一个工作日。
- 具有简单并且吸引人的用户接口——我们旨在做出人们能够使用的产品,而不仅仅停留在演示的目标上。
- 要有方便获取的训练数据——众所周知,有时候数据比算法更加昂贵
- 使用到前沿的深度学习技术(要是那种还未被 Google Allo、亚马逊以及其云平台上的合作者商业化的技术),但是也不能太前沿(这样的话我们可以在网络上找到一些例子)
- 要拥有实现「生产就绪」(production ready)结果的潜力
我们的前期想法是做一些医疗项目,因为这个领域与我们内心所设想、所感受的东西更相近,医疗领域还有着大量唾手可得的成果。然而,我们意识到我们可能会在收集数据上碰到一些问题,也有可能会触及到法律,这是我们最后放弃医疗项目的原因。我们的第二个选择就是图像背景去除。
背景去除是一个很容易手动或者半手动实现的任务(Photoshop,甚至 Power Point 都有这类工具),如果你使用某种「标记」或者边缘检测,这里有一个实例
(https://clippingmagic.com/)。然而,全自动化的背景去除是一个相当有挑战性的任务,据我们所知,目前还没有一个产品具有令人满意的效果,尽管有人在尝试。
我们要去除什么背景呢?这是一个重要的问题,因为就对象、角度而言,一个模型越是具体,分离的质量就会越高。我们的工作开始时,想法很庞大:就是要做一个通用的能够识别所有类型的图像中的前景和背景的背景去除器。但是当我们训练完第一个模型之后,我们明白了,集中力量在某类特定的图像集上会更好一些。所以,我们决定集中在自拍和人物肖像上。
肖像的背景去除")
人物(类人)肖像的背景去除
自拍有明显的和更为集中的前景(一个或者多个人物),这使得我们能够很好地将对象(人脸+上身)与背景分离,同时还有一个相对固定的角度,以及总是同一个对象(人物)。
有了这些假设之后,我们踏上了研究、实现以及花数小时训练得到一个简便易用的背景去除产品的旅程。
我们的主要工作是训练模型,但是我们不能低估正确部署的重要性。好的分割模型仍然不如分类模型那么紧密(例如 SqueezeNet),我们主动地检查了服务器模型和浏览器模型的部署选择。
如果你想阅读关于我们产品的部署过程的诸多细节,你可以去浏览我们关于服务器端和客户端的博文。
如果你想读到更多关于模型和训练的东西,那就继续吧。
语义分割
我们查看了和我们的任务类似的深度学习和计算机视觉任务,不难发现,我们的最佳选择就是语义分割任务。
其他策略,比如通过深度检测来做分割也存在,但是对我们的目标而言并不成熟。
语义分割是一个计算机视觉经典任务,它是计算机视觉领域的三大主题之一,其他两个分别是分类和目标检测。从将每一个像素归为一个类别来讲,分割实际上也是一个分类任务。然而与图像分类和目标检测不一样的是,分割模型事实上表现出了某种对图像的「理解」,在像素层面上不仅能区分「这张图像上有一只猫」,还能指出这是什么猫。
所以,分割是如何工作的呢?为了更好地理解它,我们必须梳理一下这个领域的一些早期工作。
最早的想法是采用一些早期的分类神经网络,例如 VGG、Alexnet。回溯到 2014 年,VGG 是图像分类任务中最领先的网络,它在今天也相当有用,因为它有着简单直接的结构。在查看 VGG 的前几层的时候,你可能会注意到从每一条目到类别都有高激活值。更深的层甚至还有更高的激活值,但是由于其重复池化动作,本质上它们是很粗糙的。有了这些理解之后,可以假定,在经过一些处理之后,分类训练也能用在寻找/分割对象的任务中。
早期的语义分割结果是和分类算法一起出现的。在本文中,你可以看到我们使用 VGG 得出的一些简单的分割结果:
后边层的结果:

对 buss 图像的分割,浅紫色区域(29)代表校巴类别
双线性上采样之后:
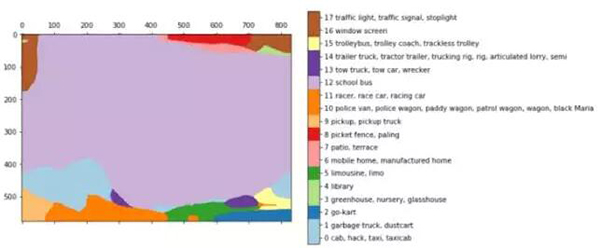
这些结果仅来自于简单地将全连接层转换(或者修改)为它最初的形态,修改它的空间特征,得到一个全连接的卷积神经网络。在上面的例子中,我们把一张 768*1024 的图像输入到 VGG,然后就得到了 24*32*1000 的一个层,24*32 是图像的池化版本,1000 是 image-net 的类别数目,从这里我们能够得到上述的分割结果。
为了使预测结果更加平滑,研究者还使用了简单的双线性上采样层。
在全连接神经网络的论文中
(Fully Convolutional Networks for Semantic Segmentation,https://arxiv.org/abs/1411.4038),研究者提升了上述的想法。为了具有更加丰富的解释,他们把一些层连接在一起,根据上采样的比例,它们被命名为 FCN-32、FCN-16 和 FCN-8。
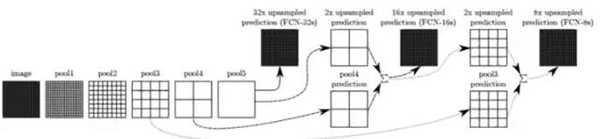
在层之间添加一些跳跃连接使得从原始图像到编码的预测更加精细。进一步训练模型会让结果更好。
这个技术表现出的效果并不像预料中的那么差劲,并且证明利用深度学习进行语义分割确实是有潜力的。

FCN 论文中全连接神经网络的结果
全连接神经网络开启了分割的概念,研究者为这个任务尝试了不同的架构。主要思想是类似的:使用已知的架构、上采样以及使用跳跃连接,这些仍然在新模型中占据主要部分。
回到我们的项目
经过调研之后,我们选择了三个合适的模型开始研究:FCN、Unet 以及 Tiramisu——这是一个非常深层的编码器-解码器架构。我们还在 mask-RCNN 上有一些想法,但是实现这个似乎不在我们这个项目的范围之内。
FCN 看上去并不相关,因为它的结果和我们想要的结果(即便是初始点的结果)不一样,但是我们提到的其他两个模型却表现出了不错的结果:CamVid 数据集上的 tiramisu 模型和 Unet 模型主要的优点是紧凑性和速度。在实现方面,Unet 是相当直接的(使用 keras),并且 Tiramisu 也是可实现的。我们使用 Jeremy Howard 上一次的深度学习课程中对 Tiramisu 较好的实现来开始我们的项目。
我们使用这两个模型开始在一些数据集上训练。不得不说的是,当我第一次训练完 Tiramisu 之后,发现它的结果对我们而言更有优势,因为它有能力捕捉图像中的尖锐边缘,然而,Unet 看上去并不是那么好,甚至有一点搞笑。

Unet 的结果稍有逊色
数据
在利用模型设定好我们的基础目标之后,我们就开始寻找合适的数据集。分割数据并不像分类和检测那样常见。此外,人工标注也不现实。最常用于分割的数据集是 COCO(http://mscoco.org/),这个数据集大约包括 8 万张图像(有 90 类),VOC pascal 数据集有 1.1 万张图像(有 20 类),以及更新的数据集 ADE20K。
我们选择使用 COCO 数据集,因为其中「人」类的图像更多,这恰好是我们的兴趣所在。
考虑到我们的任务,我们思考是否仅仅使用和我们的任务超级相关的图像,或者使用更加通用的数据集。一方面,一个更通用的数据集拥有更多的图像和类别,这使得我们能够应付更多的场景和挑战。另一方面,一次彻夜不歇的训练可以处理大约 15w 张的图像。如果我们在整个 COCO 数据集上引入模型的话,结果会是,模型处理每张图像的平均次数是 2 次,所以稍作修改是有益处的。此外,这会使得模型更聚焦于我们的目标。
另一件值得提及的事情是 Tiramisu 模型最初是在 CamVid 数据集上训练的,它有一些缺陷,但最重要的是其图像很单调:所有图像都是道路上的车辆。你不难理解,从这样的数据集中学习对我们的任务并没有好处(即使图像中包含了人物),所以在短暂的实验之后,我们便改变了数据集。

CamVid 数据集中的图像
COCO 数据集附带相当直接的 API,这些 API 可以让我们知道每一张图像中是哪种类型的对象。
在一些实验之后,我们决定稀释一下数据集:首先我们过滤出其中有人的图像,最终得到了 4 万张。然后,丢弃了有很多人在里面的图像,留下了只有一个或者两个人的图像,因为这是产品所需要的。最后,我们留下了 20%-70% 被标注为人的图像,去掉那些在背景中有一小部分是人的图像,还有那些具有奇怪的建筑的图像也一并去掉了(不过不是所有的都去掉)。我们最终得到的数据集只有 1.1 万张图像,我们觉得在目前这个阶段已经够用了。
左:正常图像;中:有太多东西的图像;右:目标太小了
Tiramisu 模型
之前说过,我们使用了 Jeremy Howard 的课程中讲述的 Tiramisu 模型。尽管它的名字「100 层 Tiramsiu」显得它很庞大,但是实际上它却是一个相当经济的模型,仅仅有 900 万个参数。相比之下,VGG-16 有 130M 个参数。
Tiramisu 模型是基于 DensNet 的,DensNet 是一个最新的图像分类模型,所有的层都是相互连接的。此外,与 Unet 类似,Tiramisu 模型在上采样层上添加了跳跃连接。
回想一下前文你就会发现,这个架构和 FCN 中呈现的思想是一致的:使用分类架构、上采样并且为精调添加跳跃连接。

通用的 Tiramisu 架构
DenseNet 模型可以看作是一个自然进化的 Reset 模型,但是,DenseNet 不是简单地把一层的信息「记忆到」下一层,而是在整个模型中记忆所有层。这些连接被称作高速连接。它造成了过滤器数目的膨胀,这被定义为「增长率」。Tiramisu 的增长率是 16,所以我们会给每一层添加 16 个过滤器,直至到达具有 1072 个过滤器的那一层。你也许期望着具有 1600 个过滤器的那一层,因为这是 100 层的 Tiranisu,然而,上采样会舍弃一些过滤器。
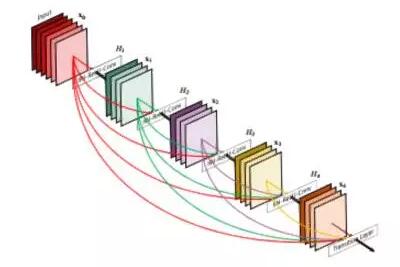
DenseNet 模型框架——在整个模型中,前边层的过滤器是堆叠的
训练
我们遵循原始论文中的计划来训练模型:标准交叉熵损失,学习率为 0.001 的 RMSProp 优化器,较小的衰减。我们将数据的 70% 用来训练,20% 用来验证,10% 用来测试。下面的所有图像都来自我们的测试集。
为了让我们的训练过程与原始论文一致,我们把 epoch 大小设置为 500 张图像。这也使得我们能够在结果中的每一次进展中周期地保存模型,因为我们是在很大的数据上训练模型的(那篇文章中用到的 CamVid 数据集仅有不到 1000 张图像)。
此外,我们训练的模型只有两个类:背景和人物,然而那篇论文中的模型有 12 个类。我们首先尝试着在部分 COCO 类上训练,但是我们随后就发现这对我们的训练没多大作用。
1. 数据问题
一些数据集的缺陷阻碍了我们模型的评分:
- 动物—我们的模型有时候会分割动物,这也自然导致了较低的 IOU,会将动物添加到我们的主要分类中。
- 身体部分—由于我们有计划地过滤了我们的数据集,所以没办法区分图像中的人是一个真实的人还是某个身体部位,例如手、脚。这些图像虽然不在我们的考虑范围之内,但是还是会处处出现。
动物、身体部分以及手持物体
手持物体——数据集中的很多图像都是和运动相关的。到处都是棒球拍、羽毛球拍以及滑雪板。从某种程度来说,我们的模型已经困惑于应该如何分割它们。与动物的例子一样,我们认为将它们添加到主分类或者独立的分类中会对模型的性能有所帮助。
有一个物体的运动图像
粗糙的真实情况——COCO 数据集中的很多图像都不是按照像素标注的,而是用多边形标注的。有时候这很好,但是其余时候真实情况过于粗糙,这可能会阻碍模型学习一些微妙的细节。

真实情况很粗糙的图像
2. 结果
我们的结果是令人满意的,尽管不太完美:我们在测试集上达到了 84.6 的 IoU,而当下最佳水平是 85。但是这个数字是微妙的:它会随着不同的数据集和类别浮动,有的类别本身就很容易分割,例如房屋、道路,在这些例子中很多模型都能很容易地达到 90 的 IoU。其他的更具挑战性的类别是树和人物,在这些类别中很多模型只能达到大约 60 的 IoU。为了克服这个困难,我们帮助我们的网络集中在某个单独的类别上,并且在有限种类型的图像中。
我们仍然没有觉得我们的工作是「产品就绪」的,就像我们当初想让它成为的样子一样,但是现在恰恰是停下来讨论我们的结果的时间,因为在大约 50% 的图像上都能给出较好的结果。
下面是一些很好的实例,给人的感觉就是一个不错的应用。
")
图像、真实数据、我们的结果(来自我们的测试集)
调试和日志
训练神经网络时非常重要的一部分就是调试。立马开始是很吸引人的,得到数据和网络,开始训练,看一下会得到什么结果。然而我们会发现,追踪每一个动作是非常重要的,这样就能够为我们自己创建能够检查每一步的结果的工具。
这里是一些常见的挑战以及我们的应对方法:
- 前期问题—模型可能不能训练。有可能是因为一些本质原因,或者是一些预处理的错误,例如忘记了标准化某些数据块。无论如何,对结果的简单可视化是很有帮助的。关于这个主题,这里有一篇博客(https://blog.slavv.com/37-reasons-why-your-neural-network-is-not-working-4020854bd607)。
- 调试网络本身—在确定没有关键问题之后,训练通过预定义损失和指标开始。在分割中,主要举措是 IoU——在联合中交叉。把 IoU 作为模型(而不是交叉熵损失)的主要手段确实花了一些时间。另一个有帮助的实践是在每个 epoch 展示一些模型的预测。这里有一篇调试机器学习模型的好文章(https://hackernoon.com/how-to-debug-neural-networks-manual-dc2a200f10f2)。注意,IoU 并不是 keras 中标准的指标/损失,但是你可以轻易在网上找到,比如这里(https://github.com/udacity/self-driving-car/blob/master/vehicle-detection/u-net/README.md)。我们还使用这个要点绘制损失和每个 epoch 的预测。
- 机器学习版本控制—在训练一个模型的时候,会面临很多参数,其中的一些是很微妙的。不得不说的是,除了热切地写下我们的配置(如下,使用 keras 的 callback 写下最佳模型),我们仍然没有发现完美的方法。
- 调试工具—在做完上述所有步骤之后,我们就可以逐步检查我们的工作了,然而并不是无缝的,所以,最重要的就是把上述所有步骤结合在一起,创建一个 jupyter notebook 会让我们无缝地加载每一个模型和每一张图片,并且快速检查结果。这样的话我们就能容易地发现模型之间的不同、陷阱以及其他问题。
这里是我们通过调整参数和额外训练之后得到的模型性能提升的例子:

保存目前验证过程中的最佳模型:(keras 提供了一个非常好的 callback 函数,让这一步骤变得容易多了)
callbacks = [keras.callbacks.ModelCheckpoint(hist_model, verbose=1,save_best_only =True, monitor= ’val_IOU_calc_loss’), plot_losses]
- 1.
除了对可能出现的代码错误的正常调试之外,我们还注意到模型的错误是「可预测的」,就像把看似在正常身体之外的身体部分切掉一样,大型分段上的「缺口」,非必要的扩展身体部分,糟糕的光照,低质量图像,以及很多细节。其中的一些注意事项在从数据集中添加具体的图片的时候就已经被处理了,但是其他的仍然是有待解决的难题。为了提升下一个版本的结果,我们会在「硬」图像上为我们的模型使用具体的扩展。
我们在前面的数据集问题早就提到过这个问题。现在让我们来了解一下我们模型中的困难吧:
1. 衣服—非常深色或者浅色的衣服容易被解释为背景
2. 「缺口」—即使是好的结果,里面也会有缺口

衣服和缺口
3. 光照——较差的光照条件和模糊在图像中是很常见的,然而 COCO 数据集中并不是这样的,所以,除了模型要处理的这些事情中的正常困难以外,我们的模型甚至还没有为更硬的图像做准备。这可以通过得到更多的数据来解决,此外,最好不要在晚上使用我们的应用。

较差的光照条件的实例
进一步处理的选项
1. 进一步的训练
我们的产品结果来自 300 个 epoch 的训练。在这一阶段之后,这个模型开始过拟合了。我们的这些结果已经非常接近发布的版本了,所以也不可能再去做数据扩增了。
在将图像调整到 224*224 之后,我们开始训练模型。使用更多更大的数据集进行进一步的训练也有希望提升结果(原始尺寸是 COCO 数据集上的 600*1000 的图像)。
2. CRF 和其他的增强
在某些阶段,我们发现我们的结果在边缘有一些噪声。能够精调这种问题的一个模型就是 CRF。在下面这篇博客中,作者展示了使用 CRF 的一个实例
(http://warmspringwinds.github.io/tensorflow/tf-slim/2016/12/18/image-segmentation-with-tensorflow-using-cnns-and-conditional-random-fields/)。
然而,这对我们的工作并不是很有用,也许是因为它通常在结果比较粗糙的时候才会奏效。
3. 抠图
即便是我们现在的结果中,分割也不是完美的。头发、衣服、树枝和其他物体都不可能被完美地分割,甚至是因为实况中也没有包含这些细节的标注。对这些片段的分割任务被称作抠图,这又是一个新的挑战。这里是一个今年年初在 NVIDIA 的会议上发表的最先进的抠图技术的例子
(https://news.developer.nvidia.com/ai-software-automatically-removes-the-background-from-images/)。

抠图实例——输入也包含 trimap
抠图任务和其余图像相关的任务是不一样的,因为它的输入不仅仅包含图片,还有 trimap——也就是图像边缘的轮廓,这使得这个任务成为了一个「半监督」问题。
我们用抠图做了一小部分实验,使用我们的分割作为 trimap,然而并没有得到显著的结果。
另一个问题就是缺少一个用于训练的合适的数据库。
总结
正如刚开始的时候说到的一样,我们的目标是开发一个有意义的深度学习产品。正如你在 Alon 的博客
(https://medium.com/@burgalon)中看到的一样,部署总是快速且容易的。然而,训练一个模型确实困难,尤其是在进行整夜的训练时,需要仔细地计划、调试和记录结果。
做好调研、尝试新事物以及平常的训练和改进之间的平衡也是不容易的。因为我们使用深度学习,所以我们总是觉得最佳的模型或者是最准确的模型离我们很近,并且还觉得谷歌搜索或者论文会指引我们。但是,实际上,我们的实际提升仅仅来自于更多地压榨原始模型。如上所述,我们仍旧觉得可以从原始模型中压榨出更多的提升空间。
原文:
https://medium.com/towards-data-science/background-removal-with-deep-learning-c4f2104b3157
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】