












问题阐述
Mysql Galera集群是迄今OpenStack服务***的Mysql部署方案,它基于Mysql/InnoDB,我的OpenStack部署方式从原来的主从复制转换到Galera的多主模式。
Galera虽然有很多好处,如任何时刻任何节点都可读可写,无复制延迟,同步复制,行级复制,但是Galera存在一个问题,也可以说是在实现 真正的多主可写上的折衷权衡,也就是这个问题导致在代码的数据库层的操作需要弃用写锁,下面我说一下这个问题。
这个问题是Mysql Galera集群不支持跨节点对表加锁,也就是当OpenStack一个组件有两个会话分布在两个Mysql节点上同时写入一条数据,其中一个会话会遇到 死锁的情况,也就是得到deadlock的错误,并且该情况在高并发的时候发生概率很高,在社区Nova,Neutron该情况的报告有很多。
这个行为其实是Galera预期的结果,它是由乐观锁并发控制机制引起的,当发生多个事务进行写操作的时候,乐观锁机制假设所有的修改都能 没有冲突地完成。如果两个事务同时修改同一个数据,先commit的事务会成功,另一个会被拒绝,并重新开始运行整个事务。 在事务发生的起始节点,它可以获取到所有它需要的锁,但是它不知道其他节点的情况,所以它采用乐观锁机制把事务(在Galera中叫writes et)广播到所有其他节点上,看在其他节点上是否能提交成功。这个writeset会在每个节点上进行验证测试,来决定该writeset是否被接受, 如果检验失败,这个writeset就会被抛弃,然后最开始的事务也会被回滚;如果检验成功,事务就被提交,writeset也被应用到其他节点上。 这个过程如下图所示:
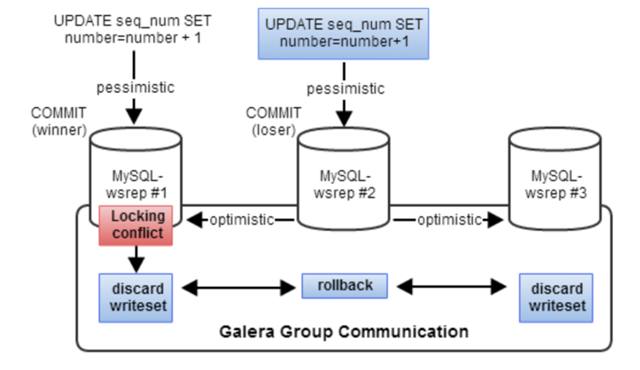
在Python的SQLAlchemy库中,有一个“with_lockmode(‘update’)”语句,这个代表SQL语句中的“SELECT … FOR UPDATE”,在我参与过的计费项目和社区的一些项目的代码中有大量的该结构,由于写锁不能在集群中同步,所以这个语句在Mysql集群中就没有得到它应有的效果,也就是在语义上有问题,但是***Galera会通过报deadlock错误,只让一个commit成功,来保证Mysql集群的ACID性。
一些解决方法
- 把请求发往一个节点,这个在HAProxy中就可以配置,只设定一个节点为master,其余节点为backup,HAProxy会在master失效的时候 自动切换到某一个backup上,这个也是很多解决方案目前使用的方法,HAProxy配置如下:
- server xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx:3306 check
- server xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx:3306 check backup
- server xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx:3306 check backup
- 对OpenStack的所有Mysql操作做读写分离,写操作只在master节点上,读操作在所有节点上做负载均衡。OpenStack没有原生支持,但 是有一个开源软件可以使用,maxscale。
***解决方法
上面的解决方法只是一些workaround,目前情况下最***的解决方法是使用lock-free的方法来对数据库进行操作,也就是无锁的方式,这就 需要对代码进行修改,现在Nova,Neutron,Gnocchi等项目已经对其进行了修改。
首先得有一个retry机制,也就是让操作执行在一个循环中,一旦捕获到deadlock的error就将操作重新进行,这个在OpenStack的oslo.db中已 经提供了相应的方法叫wrap_db_retry,是一个Python装饰器,使用方法如下:
- from oslo_db import api as oslo_db_api
- @oslo_db_api.wrap_db_retry(max_retries=5, retry_on_deadlock=True,
- retry_on_request=True)
- def db_operations():
- ...
然后在这个循环之中我们使用叫做”Compare And Swap(CAS)”的无锁方法来完成update操作,CAS是***在CPU中使用的,CAS说白了就是先比较,再修改,在进行UPDATE操作之前,我们先SELEC T出来一些数据,我们叫做期望数据,在UPDATE的时候要去比对这些期望数据,如果期望数据有变化,说明有另一个会话对该行进行了修改, 那么我们就不能继续进行修改操作了,只能报错,然后retry;如果没变化,我们就可以将修改操作执行下去。该行为体现在SQL语句中就是在 UPDATE的时候加上WHERE语句,如”UPDATE … WHERE …”。
给出一个计费项目中修改用户等级的DB操作源码:
- @oslo_db_api.wrap_db_retry(max_retries=5, retry_on_deadlock=True,
- retry_on_request=True)
- def change_account_level(self, context, user_id, level, project_id=None):
- session = get_session()
- with session.begin():
- # 在会话刚开始的时候,需要先SELECT出来该account的数据,也就是期望数据 account = session.query(sa_models.Account).\
- filter_by(user_id=user_id).\
- one()]
- # 在执行UPDATE操作的时候需要比对期望数据,user_id和level,如果它们变化了,那么rows_update就会被赋值为0 ,就会走入retry的逻辑
- params = {'level': level}
- rows_update = session.query(sa_models.Account).\
- filter_by(user_id=user_id).\
- filter_by(level=account.level).\
- update(params, synchronize_session='evaluate')
- # 修改失败,报出RetryRequest的错误,使上面的装饰器抓获该错误,然后重新运行逻辑 if not rows_update:
- LOG.debug('The row was updated in a concurrent transaction, '
- 'we will fetch another one')
- raise db_exc.RetryRequest(exception.AccountLevelUpdateFailed())
- return self._row_to_db_account_model(account)
数据的一致性问题
该问题在OpenStack邮件列表中有说过,虽然Galera是生成同步的,也就是写入数据同步到整个集群非常快,用时非常短,但既然是分布式系 统,本质上还是需要一些时间的,尤其是在负载很大的时候,同步不及时会很严重。
所以Galera只是虚拟同步,不是直接同步,也就是会存在一些gap时间段,无法读到写入的数据,Galera提供了一个配置项,叫做wsrep_sync_ wait,它的默认值是0,如果赋值为1,就能够保证读写的一致性,但是会带来延迟问题。













