在许多机器学习任务中,人工神经网络尤其是近些年发展起来的深度学习网络,已经取得了十分瞩目的结果。然而,以前研究者往往将神经网络的内部行为当作黑盒来看待,神经网络到底学习到了什么并不了解。近些年来,研究者们逐渐开始关注这一问题,并通过了解其内部行为来帮助优化模型。而这篇工作则是从可视化的角度出发来对待这个问题。
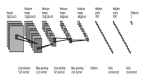
为了理解这篇工作的内容,我们首先需要对神经网络有一定的了解。神经元是神经网络中的最基本单元。一个神经元 (neuron) 接受若干个输入,计算它们的加权和,然后使用“激活”函数对这个和进行处理后,得到输出值。其中,这里的权重就是这个神经元待学习的参数。若干个神经元可以组成一个层 (layer),同一层的神经元之间没有值的传递关系。而多个层可以依次排列起来,前一层中所有(或者部分)神经元的输出作为下一层各个神经元的输入。除了***层的神经元不需要输入,而直接输出数据的某一分量;***一层的神经元的输出不再作为其他神经元的输入,而直接用于相应的任务。图1就是这样一种典型的神经网络,它具有三层,***层为输入,***一层为输出,中间一层称之为隐含层。我们可以将一个神经网络看作依次对输入数据进行处理的函数,每经过一层原始数据就得到一次变换,***一层变换后的结果则直接用于处理对应任务。

图1:一个典型的神经网络结构
在这么个神经网络中,可以用来可视化的数据包含两部分:一是每一层神经元的输出,它们对应输入数据在网络中的不同表示;二是每个神经元所学习到的权重,它们刻画着各个神经元的行为,即如何对输入进行响应的。这两部分数据分别对应作者在这篇工作中研究者们提出的神经网络内部行为的两个任务:任务一,研究数据表示间的关系;任务二、研究神经元间的关系。
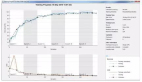
为了进行具体的研究,作者考虑了两种神经网络模型:多层感知机MLP和卷积神经网络CNN。其中,多层感知机的结果类似于图1,只是中间含有4个隐含层,各具有1000个神经元。而卷积神经网络在输入层之后有若干卷积层、池化层等等,***在输出层之前会有全连接层,也就是类似图1中的结构。作者采用这两种模型在数据集MNIST、SVHN和CIFAR-10分别进行测试与比较。这三个数据集都是用于测试图片中数字或者物体的识别任务的。对应到所采用的两种神经网络模型中,输入层的每个神经元对应数据集中样本的每个像素,而输出层的每个神经元则分别对应图片所属的数字或者物体某一个类别,输出值表示属于那一类别的概率。图2中,展示了这两种模型在三个数据集上的测试准确率。

图2:两种网络结构在三个数据集上的准确率
我们回到神经网络本身。前面提到的神经网络的内部行为实际上包含两部分数据,并且均为高维数据。作者选择采用降维投影的方式对它们进行可视化。其中,对于***个任务,由于原始数据本身已经有所属类别,那么研究数据表示间的聚类关系就有必要性。作者选择了能更好保留相邻关系和聚类关系的t-SNE投影来对这部分数据进行处理。而在第二个任务中,神经元的关系主要考察它们之间线性相关性的大小,那么能尽量保持距离的MDS投影被作者采用。
接下来,我们通过样例分析来看看可视化是如何在这两个任务上发挥其作用的。

图3:训练前后MLP***一层数据表示的投影图
在***个例子中(图3),左图是针对MNIST数据,未经训练的MLP***一层神经元输出的投影结果。可以看到,即使模型还未经训练,其内部表示中,已经有了比较好的类间区分性。这一现象尽管比较直接,但没有被任何已有工作所记录。这也意味着投影的方法可以用于研究模型的初始化策略。而右图则是训练后的数据表示投影结果,可以看到类间的视觉区分性大大增强了。同时,模型的预测准确率也增强了。这就说明了根据内部表示的类间区分性能一定程度上预测模型的准确率,同时也说明模型的训练过程也是提高数据内部表示的类间区分性的过程。

图4:训练后MLP***层和***一层数据表示的投影图
投影图还可以用于比较同一模型不同层的表示区别。如图4所示,左侧是***层的表示投影图,右侧是***一层的投影图。可以看到类间的可分性得到了明显的提升。这也就意味着后面的层通过抓住数据中更高层的特征,对数据有了更具区分性的表示。

图5:训练后CNN***一层数据表示的投影图
在第二个例子中,作者将SVHN数据集的MLP***一层神经元输出进行投影(图5)。从投影图中,可以容易地看到每个类别的点基本都形成了两个聚类。经过对投影图的探查,发现其中一个聚类对应的是“浅色背景上的深色数字”,而另一类对应的是“深色背景上的浅色数字”。这种通过可视化得到的语义知识可以进一步帮助理解和提高模型。例如,作者对测试数据进行边缘提取操作,以移除深浅颜色带来的影响,在完全相同的模型下,预测准确率立即有了提升。其实,已有的研究者也有提出类似的处理方式来提高模型性能,但是他们并没有对这种做法的合理性进行解释。这种聚类的语义还可以用来解释模型的错误分类。例如,有一个数字9的图片被错分为数字2。但是,一般人可能比较疑惑:为什么图片中的9如此清晰且没有形变,但却别错分了呢?通过观察投影图,可以看到这个图片对应的点正好在“浅色背景上的深色数字2”附近,那就意味着是模型将图片中数字9右边的边框错认为了一个形变的数字2。

图6:训练后MLP模型中数据表示随层次的演变可视化
通过将多个投影图联合起来观察,还可以研究模型中数据表示的动态变化过程。图6中,左侧4张小图展示的是MLP在每个隐含层之后,数据表示的投影情况。右侧大图则将同一数据点不同层的表示用曲线连接了起来,用颜色表示层间先后关系。作者同时采用边捆绑技术来减少视觉混乱。从图中可以很容易地看到随着层次的演进,数据中类内部的一致性和类间的区分性得到了强化。在图中还能看到一些异常的轨迹,他们的表示在模型中发生了比较剧烈的变化,可能对应一些错分类的数据。通过类似的方法,还能看到在训练过程中,每次迭代之后,数据的表示是如何变化的。从中也能观察到类似的类内部的一致性和类间的区分性的强化效果,具体请参见原文。

图7:训练前后CNN网络的数据表示投影图与神经元投影图
接着,作者研究神经元间的关系,即第二个任务。图7中,分别展示了训练前、后数据表示的投影图和神经元权重关系的投影图。作者首先在训练后的数据表示投影图中选择了对应数字8的数据点,在神经元投影图中,对这部分数据具有高激活的神经元被高亮。可以看到,这些神经元基本形成了一个聚类,也就是说它们之间比较相似。而这些神经元在训练前则是分散在了投影空间中。由此可见,随着训练的进行,这些神经元逐渐被特化成专门用于分辨数字8的“专家”,并且逐渐变得相似。

图8:根据激活类别和程度着色的神经元投影图和数据表示投影图
在图8左侧图中,作者直接根据每个神经元最易激活的类别对它们进行着色。其中,编号460的神经元最容易对数字3产生高激活值。在对应的数据表示投影图上,我们能看到被这个神经元激活的数据点主要对应“浅色背景上的深色数字3”这一聚类。但同时,有一部分属于数字5的数据点也有较高的激活值。这意味着,尽管这个神经元比较擅长识别数字3,但在一些数字5的数据上也会产生错误。通过类似的分析方法,研究者可以了解神经元的行为与角色,这也是神经网络研究中的一个非常重要的问题。
总结起来,作者使用降维的方法探索了深度神经网络中数据表达之间的关系和神经元之间的关系。作者使用的可视化技术比较简单与直接。但在面对这一类数据上还是取得了许多的发现,其中有些还是没有被已有工作提高过的未知发现,并且还能间接帮助提高模型性能。