Facebook 研究员近日开源了他们在今年七月发表的一篇论文(Voice Synthesis for in-the-Wild Speakers via a Phonological Loop)中的语音合成方法。

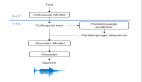
在论文中,他们提出了一种新的文字转语音的神经网络方法,可以将从开放场景下采样到的声音中提取的文字转化为语音。不同于其他的文字转语音系统,这种方法能够处理从公开演讲中提取出来的非约束性的样本,而且网络架构比现存的解决同样问题的架构要简单。它基于新的移位缓冲内存储器区(shifting buffer working memory),这个缓冲区也可以用于评估注意力,计算输出音频,以及自身的更新。

通过使用与上下文无关( context-free)的查找表对输入语句进行编码,该表的每个条目包含一个字符或音素。同样,能通过一个短向量来表示说话者,这个短向量也适用于新说话者。而且在生成音频之前,优先准备好缓冲区可以使生成的语音具有可变性。
上图为实验样例中生成的注意力图,X 轴是输出时间(声学样本),Y 轴是输入(文本/音素)。
代码地址:https://github.com/facebookresearch/loop
论文地址:https://arxiv.org/abs/1707.06588