推荐系统需要根据用户的历史行为和兴趣预测用户未来的行为和兴趣,但对于新用户而言,没有任何的用户行为,如何进行最有效的推荐呢?这就衍生了用户冷启动问题。在当下,企业拉新成本越来越高,用户的选择面也越来越多,当新用户到达之后,如果不能很快的捕捉用户兴趣,推荐其所感兴趣的物品,很容易造成用户流失。所以能否解决好冷启动问题,是推荐系统非常重要的课题
达观数据研发的个性化推荐引擎目前服务了上百家企业,行业覆盖了新闻,视频,直播,文学,电商等领域,每天API调用量超过10亿,覆盖近亿网民。本文主要介绍下达观数据个性化推荐引擎如何解决新用户的冷启动问题(达观数据 纪达麒)
达观个性化推荐引擎主要通过新用户属性挖掘,秒级模型更新,跨应用数据整合三种方法来解决新用户的冷启动问题
1.新用户属性挖掘
新用户,指的是***次访问的用户,之前没有任何的行为,但这些用户也是有个性化信息的。信息包括
1)用户的访问时间,白天,晚上,还是深夜,是工作日还是周末
2)用户所在的地域,一线城市或者二线城市
3)App用户的手机型号,是安卓,还是IOS,是小米还是华为或者是OPPO
4)PC用户的话,浏览器类型,如IE或者Chrome,分辨率1024*768还是800*600
5)用户的登录页,首页还是某个活动的页面
6)一些应用在用户注册的时候,还会填写用户信息以及兴趣偏好
7) 更多……
有了用户属性这些信息,就可以给新用户进行推荐。一开始达观使用的方式是对上面进行进行交叉组合,通过历史数据挖掘交叉组合后的用户偏好。比如深夜,从北京访问,使用小米手机,通过首页访问的新用户最可能偏好哪些物品。通过实践发现,这种方式可以一定程度上提升新用户推荐的效果,但也有不足之处。主要有2点
1) 上面用户信息的交叉组合后,维度会比较高,造成满足这些维度的数据在一些情况下质量不高,置信度不够
2) 对于一些时效性应用场景,比如资讯类,该算法计算出来的往往是过去的文章
所以达观个性化推荐引擎进行了升级,使用机器学习的方式获得新用户的偏好。目前使用的方法是LogicRegression
![]()
该模型中的X就是我们需要输入的特征,B是训练得到的特征权重。所以这里面最核心的是特征的选择,会把上面提到的单维特征,多种组合特征,以及item的标签,类别都加入模型,通过训练得到特征权重。再对新用户进行预测。
2.用户模型秒级更新
用户下载新的app或者到一个新的网站,他往往会根据自己的兴趣,看看里面的内容,不会看一眼推荐不喜欢马上就流失,达观的经验值是大部分用户愿意花2~30分钟来尝试新的一个应用或者网站。所以对于推荐系统而言,如果可以快速捕捉用户兴趣,推荐出新用户感兴趣的物品,也能很大程度上提升用户的推荐效果。(达观数据 纪达麒)
传统的推荐方法,离线模型定期挖掘(小时级甚至是天极)显然不能满足快速给新用户建模的需求。达观个性化推荐引擎使用了offline-nearline-online的三层体系
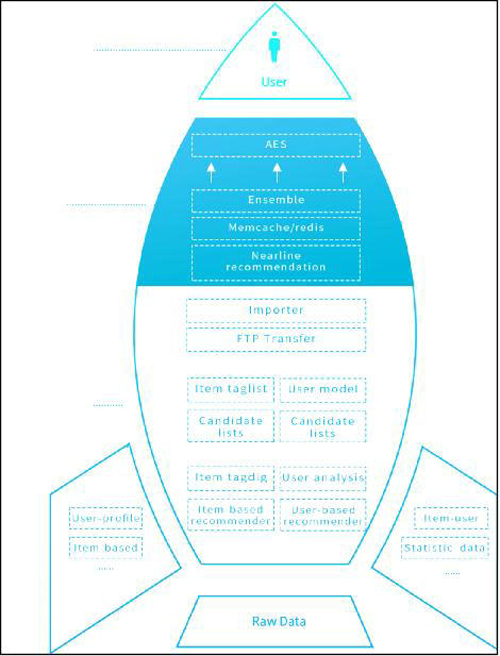
达观数据推荐系统三层体系借鉴了信息检索领域思想,采取online-nearline-offline的结构。主要思想是让最珍贵的资源留给高价值的user和item。
Online模块采用负载均衡,负责及时响应API请求,并返回推荐结果,保证高可靠高并发。
Offline基于hadoop集群对海量数据进行深入挖掘,承担高负荷的算法。
Nearline模块主要是填补Online和Offline之间的空白。作为Offline的补充,保证快速响应点击反馈数据。作为Online的补充运行一些轻量级的算法。当新用户产生了行为,(行为既包括正反馈,如用户阅读或者分享了某篇文章 ,也包括负反馈,给用户展现了某篇文章,用户没有点击)Nearline可以准实时获取,并且更新用户模型。达观目前可以做到一个秒级的更新,所以用户下次再访问推荐结果的时候,就可以推荐给“新”用户可能感兴趣的结果
3. 跨应用数据整合
前面提到达观数据目前给数百家企业提供推荐服务,覆盖上亿网民。所以如果可以加用户数据打通,也能很好的解决冷启动的问题。不过不同企业物品的分类,标签并不一样,甚至行业也有些不同,所以对用户的刻画也都有比较大的差别,如何使用好跨企业的数据,也是一个复杂的工程
3.1 生成用户画像,再进行个性化推荐
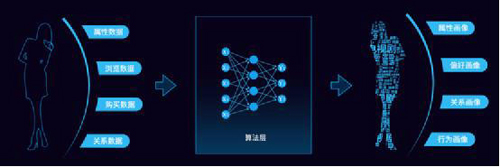
比较常见的跨应用数据打通的方式是生成用户画像,方法是每个应用根据各自的用户行为,给用户打上之前定义好的标签,标签包括了业务标签和自然属性标签。业务标签为根据业务信息打上的标签,比如娱乐,体育等,自然属性标签主要为人口属性,比如性别,年龄,收入等。新用户推荐时再根据规则进行匹配,比如男性喜欢体育的推荐仙侠类小说
这种方式的问题有几个问题
1) 由应用打上定义好的标签往往准确率不会很高,对于自然属性标签,性别,经常看美女直播的用户就是男性?年龄和收入的标签误差就更大了。对于业务标签,如果定义很细,比如不是娱乐,而是刘德华这样的属性,那很难进行应用,比如在推荐小说的场景下,我们获取用户是刘德华的粉丝,那应该给他推荐什么小说呢?。而如果定义到娱乐这样的粒度,那也是损失了很多信息。比如喜欢鹿晗的用户和喜欢刘德华的用户行为往往差别很大,如果都定义为娱乐类,就丢失了他们之间的区别
2)应用上使用上面标签时,往往也有很大问题。因为人为的规则往往非常片面,比如上面的例子:男性喜欢体育的推荐仙侠类小说。其实往往不是非常客观和准确
3.2 应用内行为直接作为推荐特征进行匹配
上面的做法的本质问题是人为的定义了一个中间属性层,使得不论是基础数据映射到中间层,还是具体应用通过中间层数据进行规则匹配,都存在很大的误差。所以达观的做法是去掉这个中间层,通过机器学习方法直接通过基础数据映射到个性化应用中。具体方式为
a) 每个应用保留多个维度的用户数据,包括

b)将用户在每个应用中的数据进行整合,形成用户向量
c)使用基于用户的协同过滤方法进行新用户推荐
基于用户的协同过滤的思想是当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。
***步,找到相似兴趣的其他用户
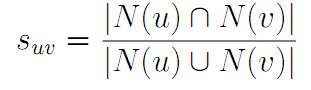
第二步,根据相似用户的喜好进行推荐
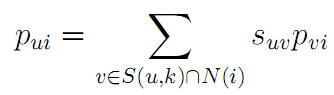
对于新用户,往往没有什么行为,所以通过***步中的行为进行相似度计算往往没有结果。所以我们用前面提到的跨应用的数据来解决这个问题
每个用户可以通过***步的结果形成用户向量,计算用户间的距离。由于不同应用下不论是类别还是标签,都不统一,比如有些应用下称为搞笑,有些称为笑话,标签上更加五花八门,比如有些标签是范冰冰,有些是范爷。需要转化成词向量才能方便而准确的计算距离
先介绍一下词向量的定义。一种最简单的词向量是one-hot representation,就是用一个很长的向量来表示一个词,向量的长度是词典D的大小N,向量的分量只有一个为1,其他全为0,1的位置对应该词在词典中的索引。这种词向量表示有一些缺点:容易受维数灾难的困扰。另一种词向量是Distributed Representation,它最早是Hinton于1986年提出来的,可以克服one-hot representation的上述缺点。其基本想法是:通过训练将某种语言中的每个词映射成一个固定长度的短向量。所有这些向量构成一个词向量空间,每个向量是该空间中的一个点,在这个空间上引入“距离”,就可以根据词之间的距离来判断它们之间的(词法、语义上的)相似性了。如何获取Distributed Representation的词向量呢?有很多不同的模型可以用来估计词向量,包括有名的LSA、LDA和神经网络算法。Word2Vec就是使用度比较广的一个神经网络算法实现的词向量计算工具。(达观数据 纪达麒)
所以在目前场景下,基于Distributed Representation的词向量可以更好地解决跨应用标签不一致的问题。为了训练一个比较好的词向量,达观抓取了3000多万微信文章作为训练,词向量本身不容易分辨好坏,所以通过抽查近距离词来看结果


通过词向量的方式,可以正确计算出找字面上看似无关,但含义相似的词之间的距离,进而可以更加准确地计算用户之间的距离
4. 总结
本文介绍了达观数据个性化推荐系统在解决新用户冷启动问题的实践经验,通过新用户属性挖掘,秒级模型更新,跨应用数据整合三种方法,可以有效地提高新用户的推荐效果,当然新技术也在不断出现,深度学习的兴起也给个性化推荐效果的提升带来了更大的契机和想象空间,达观数据也在这方面进行不断探索。
【本文为51CTO专栏作者“达观数据”的原创稿件,转载可通过51CTO专栏获取联系】