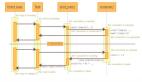
PyTorch 中的基本单位是张量(Tensor)。本文的主旨是如何在 PyTorch 中实现 Tensor 的概述,以便用户可从 Python shell 与之交互。本文主要回答以下四个主要问题:
- PyTorch 如何通过扩展 Python 解释器来定义可以从 Python 代码中调用的 Tensor 类型?
- PyTorch 如何封装实际定义 Tensor 属性和方法的 C 的类库?
- PyTorch 的 C 类包装器如何生成 Tensor 方法的代码?
- PyTorch 的编译系统如何编译这些组件并生成可运行的应用程序?
扩展 Python 解释器
PyTorch 定义了一个新的包 torch。本文中,我们将考虑._C 模块。这是一个用 C 编写的被称为「扩展模块」的 Python 模块,它允许我们定义新的内置对象类型(例如 Tensor)和调用 C / C ++函数。
._C 模块定义在 torch/csrc/Module.cpp 文件中。init_C()/ PyInit__C()函数创建模块并根据需要添加方法定义。这个模块被传递给一些不同的__init()函数,这些函数会添加更多的对象到模块中,以及注册新的类型等。
__init() 可调用的部分函数如下:
- ASSERT_TRUE(THPDoubleTensor_init(module));
- ASSERT_TRUE(THPFloatTensor_init(module));
- ASSERT_TRUE(THPHalfTensor_init(module));
- ASSERT_TRUE(THPLongTensor_init(module));
- ASSERT_TRUE(THPIntTensor_init(module));
- ASSERT_TRUE(THPShortTensor_init(module));
- ASSERT_TRUE(THPCharTensor_init(module));
- ASSERT_TRUE(THPByteTensor_init(module));
这些__init()函数将每种类型的 Tensor 对象添加到._C 模块,以便它们可以在._C 模块中调用。下面我们来了解这些方法的工作原理。
THPTensor 类型
PyTorch 很像底层的 TH 和 THC 类库,它定义了一个专门针对多种不同的类型数据的「通用」Tensor。在考虑这种专业化的工作原理之前,我们首先考虑如何在 Python 中定义新的类型,以及如何创建通用的 THPTensor 类型。
Python 运行时将所有 Python 对象都视为 PyObject * 类型的变量,PyObject * 是所有 Python 对象的「基本类型」。每个 Python 类型包含对象的引用计数,以及指向对象的「类型对象」的指针。类型对象确定类型的属性。例如,该对象可能包含一系列与类型相关联的方法,以及调用哪些 C 函数来实现这些方法。该对象还可能包含表示其状态所需的任意字段。
定义新类型的准则如下:
- 创建一个结构体,它定义了新对象将包括的属性
- 定义类型的类型对象
结构体本身可能十分简单。在 Python 中,实际上所有浮点数类型都是堆上的对象。Python float 结构体定义为:
- typedef struct {
- PyObject_HEAD
- double ob_fval;
- } PyFloatObject;
PyObject_HEAD 是引入实现对象的引用计数的代码的宏,以及指向相应类型对象的指针。所以在这种情况下,要实现浮点数,所需的唯一其他「状态」是浮点值本身。
现在,我们来看看 THPTensor 类型的结构题:
- struct THPTensor {
- PyObject_HEAD
- THTensor *cdata;
- };
很简单吧?我们只是通过存储一个指针来包装底层 TH 张量。关键部分是为新类型定义「类型对象」。我们的 Python 浮点数的类型对象的示例定义的形式如下:
- static PyTypeObject py_FloatType = {
- PyVarObject_HEAD_INIT(NULL, 0)
- "py.FloatObject", /* tp_name */
- sizeof(PyFloatObject), /* tp_basicsize */
- 0, /* tp_itemsize */
- 0, /* tp_dealloc */
- 0, /* tp_print */
- 0, /* tp_getattr */
- 0, /* tp_setattr */
- 0, /* tp_as_async */
- 0, /* tp_repr */
- 0, /* tp_as_number */
- 0, /* tp_as_sequence */
- 0, /* tp_as_mapping */
- 0, /* tp_hash */
- 0, /* tp_call */
- 0, /* tp_str */
- 0, /* tp_getattro */
- 0, /* tp_setattro */
- 0, /* tp_as_buffer */
- Py_TPFLAGS_DEFAULT, /* tp_flags */
- "A floating point number", /* tp_doc */
- };
想象一个类型对象的最简单的方法就是定义一组该对象属性的字段。例如,tp_basicsize 字段设置为 sizeof(PyFloatObject)。这是为了让 Python 知道 PyFloatObject 调用 PyObject_New()时需要分配多少内存。你可以设置的字段的完整列表在 CPython 后端的 object.h 中定义:
https://github.com/python/cpython/blob/master/Include/object.h.
THPTensor 的类型对象是 THPTensorType,它定义在 csrc/generic/Tensor.cpp 文件中。该对象定义了 THPTensor 的类型名称、大小及映射方法等。
我们来看看我们在 PyTypeObject 中设置的 tp_new 函数:
- PyTypeObject THPTensorType = {
- PyVarObject_HEAD_INIT(NULL, 0)
- ...
- THPTensor_(pynew), /* tp_new */
- };
tp_new 函数可以创建对象。它负责创建(而不是初始化)该类型的对象,相当于 Python 中的__new()__方法。C 实现是一个静态方法,该方法传递实例化的类型和任意参数,并返回一个新创建的对象。
- static PyObject * THPTensor_(pynew)(PyTypeObject *type, PyObject *args, PyObject *kwargs)
- {
- HANDLE_TH_ERRORS
- Py_ssize_t num_args = args ? PyTuple_Size(args) : 0;
- THPTensorPtr self = (THPTensor *)type->tp_alloc(type, 0);
- // more code below
我们的新函数的***件事就是为 THPTensor 分配内存。然后,它会根据传递给该函数的参数进行一系列的初始化。例如,当从另一个 THPTensor y 创建 THPTensor x 时,我们将新创建的 THPTensor 的 cdata 字段值设置为以 y 的底层 TH Tensor 作为参数并调用 THTensor_(newWithTensor)返回的结果。这一过程中有内存大小、存储、NumPy 数组和序列的类似的构造函数。
注意,我们只使用了 tp_new 函数,而不是同时使用 tp_new 和 tp_init(对应于 Python 中的 __init()__函数)。
Tensor.cpp 中定义的另一个重要的部分是索引的工作原理。PyTorch Tensors 支持 Python 的映射协议。这样我们可以做如下事情:
- x = torch.Tensor(10).fill_(1)
- y = x[3] // y == 1
- x[4] = 2
- // etc.
注意,此索引可以拓展到多维 Tensor。
我们可以通过定义
https://docs.python.org/3.7/c-api/typeobj.html#c.PyMappingMethods 里描述的三种映射方法来使用[]符号。
最重要的方法是 THPTensor_(getValue)和 THPTensor_(setValue),它们解释了如何对 Tensor 进行索引,并返回一个新的 Tensor / Scalar(标量),或更新现有 Tensor 的值。阅读这些实现代码,以更好地了解 PyTorch 是如何支持基本张量索引的。
通用构建(***部分)
我们可以花费大量时间探索 THPTensor 的各个方面,以及它如何与一个新定义 Python 对象相关联。但是我们仍然需要明白 THPTensor_(init)()函数是如何转换成我们在模块初始化中使用的 THPIntTensor_init()函数。我们该如何使用定义「通用」Tensor 的 Tensor.cpp 文件,并使用它来生成所有类型序列的 Python 对象?换句话说,Tensor.cpp 里遍布着如下代码:
- return THPTensor_(New)(THTensor_(new)(LIBRARY_STATE_NOARGS));
这说明了我们需要使类型特定的两种情况:
- 我们的输出代码将调用 THP
Tensor_New(...)代替调用 THPTensor_(New) - 我们的输出代码将调用 TH
Tensor_new(...)代替调用 THTensor_(new)
换句话说,对于所有支持的 Tensor 类型,我们需要「生成」已经完成上述替换的源代码。这是 PyTorch 的「构建」过程的一部分。PyTorch 依赖于配置工具(https://setuptools.readthedocs.io/en/latest/)来构建软件包,我们在顶层目录中定义一个 setup.py 文件来自定义构建过程。
使用配置工具构建扩展模块的一个组件是列出编译中涉及的源文件。但是,我们的 csrc/generic/Tensor.cpp 文件未列出!那么这个文件中的代码最终是如何成为最终产品的一部分呢?
回想前文所述,我们从以上的 generic 目录中调用 THPTensor *函数(如 init)。如果我们来看一下这个目录,会发现一个定义了的 Tensor.cpp 文件。此文件的***一行很重要:
- //generic_include TH torch/csrc/generic/Tensor.cpp
请注意,虽然这个 Tensor.cpp 文件被 setup.py 文件引用,但它被包装在一个叫 Python helper 的名为 split_types 的函数里。这个函数需要输入一个文件,并在该文件内容中寻找「//generic_include」字符串。如果能匹配该字符串,它将会为每个张量类型生成一个具有以下变动的输出文件,:
1. 输出文件重命名为 Tensor
2. 输出文件小幅修改如下:
- // Before:
- //generic_include TH torch/csrc/generic/Tensor.cpp
- // After:
- #define TH_GENERIC_FILE "torch/src/generic/Tensor.cpp"
- #include "TH/THGenerate<Type>Type.h"
引入第二行的头文件有些许弊端,例如,引入了一些额外的上下文中定义的 Tensor.cpp 源代码。让我们看看其中一个头文件:
- #ifndef TH_GENERIC_FILE
- #error "You must define TH_GENERIC_FILE before including THGenerateFloatType.h"
- #endif
- #define real float
- #define accreal double
- #define TH_CONVERT_REAL_TO_ACCREAL(_val) (accreal)(_val)
- #define TH_CONVERT_ACCREAL_TO_REAL(_val) (real)(_val)
- #define Real Float
- #define THInf FLT_MAX
- #define TH_REAL_IS_FLOAT
- #line 1 TH_GENERIC_FILE
- #include TH_GENERIC_FILE
- #undef accreal
- #undef real
- #undef Real
- #undef THInf
- #undef TH_REAL_IS_FLOAT
- #undef TH_CONVERT_REAL_TO_ACCREAL
- #undef TH_CONVERT_ACCREAL_TO_REAL
- #ifndef THGenerateManyTypes
- #undef TH_GENERIC_FILE
- #endif
这样做的目的是从通用 Tensor.cpp 文件引入代码,并使用后面的宏定义。例如,我们将 real 定义为一个浮点数,所以泛型 Tensor 实现中的任何代码将指向一个 real 对象,实际上 real 被替换为浮点数。在对应的文件 THGenerateIntType.h 中,同样的宏定义将用 int 替换 real。
这些输出文件从 split_types 返回,并添加到源文件列表中,因此我们可以看到不同的类型的.cpp 代码是如何创建的。
这里需要注意以下几点:***,split_types 函数不是必需的。我们可以将 Tensor.cpp 中的代码包装在一个文件中,然后为每个类型重复使用。我们将代码分割成单独文件的原因是这样可以加快编译速度。第二,当我们谈论类型替换(例如用浮点数代替 real)时,我们的意思是,C 预处理器将在编译期执行这些替换。并且在预处理之前这些嵌入源代码的宏定义都没有什么弊端。
通用构建(第二部分)
我们现在有所有的 Tensor 类型的源文件,我们需要考虑如何创建相应的头文件声明,以及如何将 THTensor_(方法)和 THPTensor_(方法)转化成 TH
- THP_API PyObject * THPTensor_(New)(THTensor *ptr);
我们使用相同的策略在头文件的源文件中生成代码。在 csrc/Tensor.h 中,我们执行以下操作:
- #include "generic/Tensor.h"
- #include <TH/THGenerateAllTypes.h>
- #include "generic/Tensor.h"
- #include <TH/THGenerateHalfType.h>
从通用的头文件中抽取代码和用相同的宏定义包装每个类型具有同样的效果。唯一的区别就是前者编译后的代码包含在同一个头文件中,而不是分为多个源文件。
***,我们需要考虑如何「转换」或「替代」函数类型。如果我们查看相同的头文件,我们会看到一堆 #define 语句,其中包括:
- #define THPTensor_(NAME) TH_CONCAT_4(THP,Real,Tensor_,NAME)
这个宏表示,源代码中的任何匹配形如 THPTensor_(NAME)的字符串都应该替换为 THPRealTensor_NAME,其中 Real 参数是从符号 Real 所在的 #define 定义的时候派生的。因为我们的头文件代码和源代码都包含所有上述类型的宏定义,所以在预处理器运行之后,生成的代码就是我们想要的。
TH 库中的代码为 THTensor_(NAME)定义了相同的宏,支持这些功能的转移。如此一来,我们最终就会得到带有专用代码的头文件和源文件。
#### 模块对象和类型方法,我们现在已经看到如何在 THP 中封装 TH 的 Tensor 定义,并生成了 THPFloatTensor_init(...)等 THP 方法。现在我们可以从我们创建的模块中了解上面的代码实际上做了什么。THPTensor_(init)中的关键行是:
- # THPTensorBaseStr, THPTensorType are also macros that are specific
- # to each type
- PyModule_AddObject(module, THPTensorBaseStr, (PyObject *)&THPTensorType);
该函数将 Tensor 对象注册到扩展模块,因此我们可以在我们的 Python 代码中使用 THPFloatTensor,THPIntTensor 等。
只是单纯的创建 Tensors 不是很有用 - 我们需要能够调用 TH 定义的所有方法。以下是一个在 Tensor 上调用就地(in-place)zero_ 方法的简单例子。
- x = torch.FloatTensor(10)
- x.zero_()
我们先看看如何向新定义的类型中添加方法。「类型对象」中的有一个字段 tp_methods。此字段包含方法定义数组(PyMethodDefs),用于将方法(及其底层 C / C ++实现)与类型相关联。假设我们想在我们的 PyFloatObject 上定义一个替换该值的新方法。我们可以按照下面的步骤来实现这一想法:
- static PyObject * replace(PyFloatObject *self, PyObject *args) {
- double val;
- if (!PyArg_ParseTuple(args, "d", &val))
- return NULL;
- self->ob_fval = val;
- Py_RETURN_NONE
- }
Python 版本的等价方法
- def replace(self, val):
- self.ob_fval = fal
阅读更多的关于在 CPython 中如何定义方法颇具启发性。通常,方法将对象的实例作为***个参数,以及可选的位置参数和关键字参数。这个静态函数是在我们的浮点数上注册为一个方法:
- static PyMethodDef float_methods[] = {
- {"replace", (PyCFunction)replace, METH_VARARGS,
- "replace the value in the float"
- },
- {NULL} /* Sentinel */
- }
这会注册一个名为 replace 的方法,该方法由同名的 C 函数实现。METH_VARARGS 标志表示该方法使用包含函数所有参数的参数元组。该元组设置为类型对象的 tp_methods 字段,然后我们可以对该类型的对象使用 replace 方法。
我们希望能够在 THP 张量等价类上调用所有的 TH 张量的方法。然而,为所有 TH 方法编写封装性价比极低。我们需要一个更好的方式来满足这一需求。
PyTorch cwrap
PyTorch 实现自己的 cwrap 工具来包装用于 Python 后端的 TH Tensor 方法。我们使用自定义 YAML 格式(http://yaml.org (http://yaml.org/))来定义包含一系列 C 方法声明的.cwrapfile 文件。cwrap 工具获取此文件,并以与 THPTensor Python 对象和 Python C 扩展方法调用相兼容的格式输出包含打包方法的.cpp 源文件。此工具不仅用于生成包含 TH 的代码,还包含 CuDNN。它是一款设计为可扩展的工具。
用于就地 addmv_功能的示例 YAML「声明」如下:
- [[
- name: addmv_
- cname: addmv
- return: self
- arguments:
- - THTensor* self
- - arg: real beta
- default: AS_REAL(1)
- - THTensor* self
- - arg: real alpha
- default: AS_REAL(1)
- - THTensor* mat
- - THTensor* vec
- ]]
cwrap 工具的架构非常简单。它先读入一个文件,然后使用一系列插件进行处理。
源代码在一系列的编译通过时生成。首先,YAML「声明」被解析和处理。然后,通过参数检查和提取后源代码逐个生成,定义方法头,调用底层库(如 TH)。***,cwrap 工具允许一次处理整个文件。addmv_的结果输出可以在这里找到:
https://gist.github.com/killeent/c00de46c2a896335a52552604cc4d74b.
为了与 CPython 后端进行交互,该工具生成一个 PyMethodDefs 数组,可以存储或附加到 THPTensor 的 tp_methods 字段。
在包装 Tensor 方法的具体情况下,构建过程首先从 TensorMethods.cwrap 生成输出源文件。该源文件就是通用 Tensor 源文件中的 #include 后面的文件。所有这些都发生在预处理器执行之前。结果,所有生成的方法包装器都执行与上述 THPTensor 代码相同的运作过程。因此,单个通用声明和定义也适用于其它类型。
合而为一
到目前为止,我们已经展示了如何扩展 Python 解释器来创建一个新的扩展模块,如何定义我们新的 THPTensor 类型,以及如何为所有与 TH 连接的类型的 Tensor 生成源代码。简单来说,我们将染指汇编。
Setuptool 允许我们定义一个用于编译的扩展模块。整个 torch._C 扩展模块文件是通过收集所有源文件、头文件、库等,并创建一个 setuptool 扩展来编译的。然后,由 setuptool 处理构建扩展模块本身。我将在随后的一篇博文中探讨更多的构建过程。
总而言之,让我们回顾一下我们的四个问题:
1. PyTorch 如何通过扩展 Python 解释器来定义可以从 Python 代码中调用的 Tensor 类型?
它使用 CPython 的框架来扩展 Python 解释器并定义新的类型,同时尤其关注为所有类型生成代码。
2. PyTorch 如何封装实际定义 Tensor 属性和方法的 C 的类库?
它通过定义一个由 TH Tensor 支持的新型 THPTensor。再通过 CPython 后端的各种语法规则,函数调用信息就会转发到这个张量。
3. PyTorch 的 C 类包装器如何生成 Tensor 方法的代码?
它需要我们提供自定义的 YAML 格式的代码,并通过使用多个插件通过一系列处理步骤来为每个方法生成源代码。
4. PyTorch 的编译系统如何编译这些组件并生成可运行的应用程序?
它需要一堆源/头文件、库和编译指令来构建使用 Setuptool 的扩展模块。
本博文只是 PyTorch 构建系统的部分概述。还有更多的细节,但我希望这是对 Tensor 类的多数组件的通用介绍。
资源:
https://docs.python.org/3.7/extending/index.html 对于理解如何编写 Python 的 C / C++扩展模块***价值。
原文:https://gist.github.com/killeent/4675635b40b61a45cac2f95a285ce3c0
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】