背景
某电信项目中采用HBase来存储用户终端明细数据,供前台页面即时查询。HBase无可置疑拥有其优势,但其本身只对rowkey支持毫秒级的快速检索,对于多字段的组合查询却无能为力。针对HBase的多条件查询也有多种方案,但是这些方案要么太复杂,要么效率太低,本文只对基于Solr的HBase多条件查询方案进行测试和验证。
原理
基于Solr的HBase多条件查询原理很简单,将HBase表中涉及条件过滤的字段和rowkey在Solr中建立索引,通过Solr的多条件查询快速获得符合过滤条件的rowkey值,拿到这些rowkey之后在HBASE中通过指定rowkey进行查询。

HBase与Solr系统架构设计
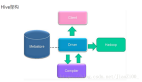
使用HBase搭建结构数据存储云,用来存储海量数据;使用SolrCloud集群用来搭建搜索引擎,将要查找的结构化数据的ID查找出来,只配置它存储ID。

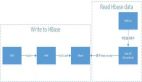
wd代表用户write data写数据,从用户提交写数据请求wd1开始,经历wd2,写入MySQL数据库,或写入结构数据存储云中,wd3,提交到Solr集群中,从而依据业务需求创建索引。
rd代表用户read data读数据,从用户提交读数据请求rd1开始,经历rd2,直接读取MySQL中数据,或向Solr集群请求搜索服务,rd3,向Solr集群请求得到的搜索结果为ID,再向结构数据存储云中通过ID取出数据,***返回给用户结果。
实现方法有两种
- 手工编码,直接用HBASE的API,可以参考下文:http://www.cnblogs.com/chenz/articles/3229997.html
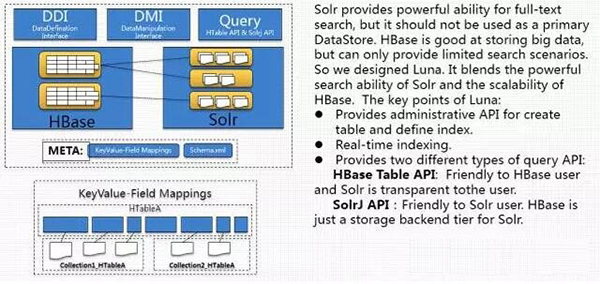
- 可以使用HBASE/Solr的LUNA接口,就不用自己管理两者。
【本文为51CTO专栏作者“大数据和云计算”的原创稿件,转载请通过微信公众号获取联系和授权】