引言
走过一些地方,发现各地都在建集中的大数据平台,提供数据、服务、工具,面向各分支部门、各外围合作伙伴,以“租户”的形式接入应用,谓之能力开放,是当下极为流行的做法。讲到开放,就要考虑考虑权限的控制、资源隔离,前者是安全控制,而后者技术性更强。当前常因为投资预算等客观原因,所谓的“大”集群规模其实也是相对的,往往就是百十来台,是否能够在这样一个单一的物理集群下承担复杂多样的应用呢?业界是没有一个标准的计算公式,更多还需要具体情况具体分析。所以我又经常碰到一些“重度使用”的集群环境,这是我们自己的一个说法,就是说集群的规模不是那么大,但上面跑的应用确是足够多。促成这个困局的现实因素是,不单是因为有限的预算,有时是因为过于技术理想主义、过度的资源压榨。讲真,如果集群规模上去了,又没几个应用,好多问题就不是问题。
案例讨论
以下给出一例:

上述集群规模在100台左右,存量数据5PB,增量在10TB/日。机器属于当前主流配置(256G内存,32核CPU)已接入的租户是30个左右,租户基本是按照不同的项目或应用为单元,可能是不同的厂家。这些应用可以分为三类,一类是离线批处理类,主要使用MR,hive,Tez,Spark,Impala长作业之类的应用以及一些即席查询,流计算实时批处理类作业主要是Spark Streaming类的作业,及基于Hbase之上的存储和查询类的业务,品种是非常齐全的。集群绝大部分时候运行良好,偶发性的性能问题有一些,主要是影响在线业务。
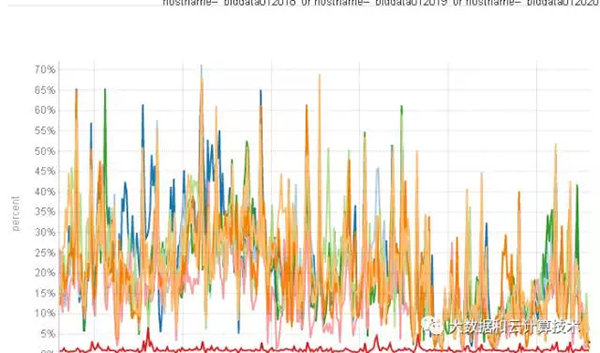
主机在某些时段,CPU消耗已出现繁忙
思考
提到资源的隔离,我们***时间想到的是Yarn,没错,当前集群也使用它来管理很大一部分(Mr on yarn,Spark on Yarn,Tez on Yarn)采用用户级资源池公平调度,由于资源吃紧,***资源数留多出一部分作为自由抢占。
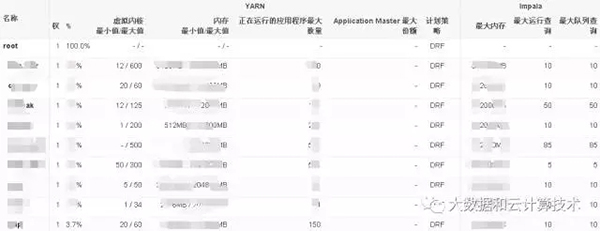
但细看有一部分的资源是存在管理盲区:
- Hbase资源隔离:只有一个全局的heapsize内存控制,没有做分用户的资源隔离,尽管当前版本已经具备单用户请求数的隔离,但验证发现对于一些scan操作结果诡异,与预期相去甚远,甚至影响正常使用,姑且认为它还不够健全而弃之。多说几句,Hbase这个组件我向来认为并不是那么好驾驭,属于上手很快、后期又容易出问题的一类东西,要求应用开发层面的考虑太多后台服务优化的点,处处充满了不人性化的设计。你比如说:hbase本来是强项基于键值的小批量查询的,偏偏也能通过hive外部表的方法来遍历查询或统计,完全当做一个关系型数据库来干了,这个动作的影响之大开发人员并没有想到,他们也无辜,问题在于hbase本身并未限制不能做这样的操作,所谓的开发规范也仅仅是一个建议。另外关于分区、键值设计等,搞不好就会影响脆弱的RS,还是要去和开发逐一阐述清楚。所以,我现在比较推举phoenix这种做了一层封装的hbase服务。关于hbase的问题,说是组件不足也好,说是使用不当也罢,反正,问题就摆在这儿。
- Impala资源的隔离:有针对单个服务实例的内存控制,也能控制到了用户级队列控制,也仅仅有内存的限制,而CPU则是任由抢占,且目前资源并未交给Yarn集中托管。CPU抢占的结果是机器本身24核它可能抢去了20核,其它的服务怎么玩?需要补充说明的是,实际是存在Impala on Yarn技术:Llama,早期由于这个东西的版本一直处于测试阶段,我们认为冒然去使用会增加问题定位的难度,因而生产应用搁浅上。
- IO的隔离:在用户队列层面,由于Yarn目前只做了CPU和核的控制,并未对IO做出控制,也就是放任抢占;当然,在服务进程层面,是可以通过cgroups做一些组件层面的限制。
重度应用环境下,技术异构体现更明显,有的是CPU密集型,有的是IO密集型,应用间的影响可能性加大,问题的定位变得更困难。例如:下图显示上面集群出现的一个问题,部分主机间歇性卡顿,top显示不是用户CPU消耗过高,而是的Sys消耗高。主机一卡顿,可能各种服务问题都会随之而来。
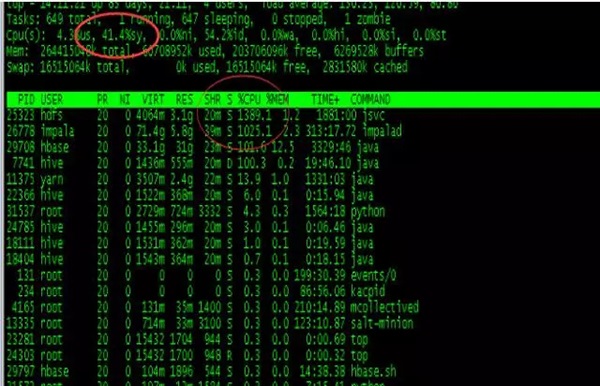
Sys过高通常有swap使用、线程交换方面的问题,而I/O方面也是潜在的因素。

以上文字说明的是:大量I/O操作也可能触发sys高负载,想想也是,所谓的sys不就是操作系统调用,当然与read,write有关的。通过比对相同时间点上的IO负载,发现确有此类问题。
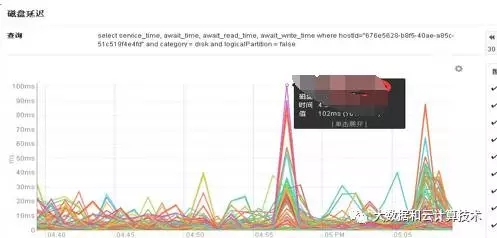
而下面张图则显示的是在针对hbase做遍历时,hbase集群层面的请求数陡增,由此引发的性能问题。

不可否认,当前技术发展的趋势总体上朝着融合的方向走,通过多租户隔离实现资源***化的共享,大家在一个集中的平台上转。现实问题在于当前开源技术还不那么成熟,更不要说生产版本还有一定滞后,直接导致资源的隔离不彻底,应用之间相互依旧有干扰。运营过程痛苦。
方案讨论
鉴于上述情况,本人斗胆建议:针对小规模的集群(<200台),现阶段还是老老实实做一定的集群拆分,特别是生产级要求高的在线业务,通过简单的分拆规避干扰。我下图给出的是一个基于技术维度上的切分,也仅供参考。细分这些应用发现,还是有那么一些应用是死不了人的,大不了可以重启解决掉(开源的东西大家都能理解),有些则是真的有所要求的。这么说可能不太严谨,但在当前过渡阶段确是有效的办法。
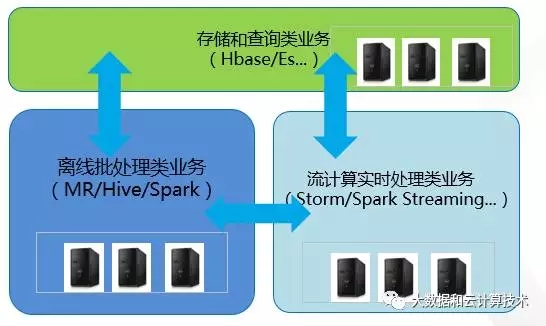
至于在技术演进方面,我们也不是无动于衷,以下是可以去做的:
1. Impala:如上文提到的,引入Llama组件,将Impala服务的资源交给Yarn集中管理。现阶段看Yarn作为一个统一的资源管理入口,就比较可控了。而关于Impala的执行容错性已经被一些案例中提及,我们也有有同类经历,这会引起我们在选型中的严重关注
2. Hbase:针对资源的隔离方案也是有的,我们探究了三种:
- 方案1:逻辑隔离:HDFS共享一套,基于之上搭建多个Hbase集群(分在不同主机上),不需要额外迁移数据
- 方案2:物理隔离:完全独立,包括HDFS也是分离的,隔离效果***,但涉及数据在不同HDFS之间交互,很多人很忌讳做这个
- 方案3:Hbase on yarn:在Hbase2.0中得以支持。类似逻辑隔离,基于Yarn面向各个用户提供单独的Hbase集群实例,regionServer运行在YARN上
本文主要是结合实际经历遇到的问题进行了一下思路总结,限于自己的眼界下给出的观点,定有不妥之处,期待与你探讨。
【本文为51CTO专栏作者“大数据和云计算”的原创稿件,转载请通过微信公众号获取联系和授权】