近来前端社区有越来越多的人开始关注前端数据层的设计。DaoCloud 也遇到了这方面的问题。我们调研了很多种解决方案,最终采用 RxJs 来设计一套数据层。这一想法并非我们的首创,社区里已有很多前辈、大牛分享过关于用 RxJs 设计数据层的构想和实践。站在巨人的肩膀上,才能走得更远。因此我们也打算把我们的经验公布给大家,也算是对社区的回馈吧。
作者简介
DaoCloud 前端工程师 瞬光
一名中文系毕业的非典型程序员
一、我们遇到了什么困难
DaoCloud Enterprise(下文简称 DCE) 是 DaoCloud 的主要产品,它是一个应用云平台,也是一个非常复杂的单页面应用。它的复杂性主要体现在数据和交互逻辑两方面上。在数据方面,DCE 需要展示大量数据,数据之间依赖关系繁杂。在交互逻辑方面,DCE 中有着大量的交互操作,而且几乎每一个操作几乎都是牵一发而动全身。但是交互逻辑的复杂最终还是会表现为数据的复杂。因为每一次交互,本质上都是在处理数据。一开始的时候,为了保证数据的正确性,DCE 里写了很多处理数据、检测数据变化的代码,结果导致应用非常地卡顿,而且代码非常难以维护。
在整理了应用数据层的逻辑后,我们总结出了以下几个难点。本文会用较大的篇幅来描述我们所遇到的场景,这是因为如此复杂的前端场景比较少见,只有充分理解我们所遇到的场景,才能充分理解我们使用这一套设计的原因,以及这一套设计的优势所在。
二、应用的难点
1. 数据来源多
DCE 的获取数据的来源很多,主要有以下几种:
(1) 后端、 Docker 和 Kubernetes 的 API
API 是数据的主要来源,应用、服务、容器、存储、租户等等信息都是通过 API 获取的。
(2) WebSocket
后端通过 WebSocket 来通知应用等数据的状态的变化。
(3) LocalStorage
保存用户信息、租户等信息。
(4) 用户操作
用户操作最终也会反应为数据的变化,因此也是一个数据的来源。
数据来源多导致了两个问题:
(1) 复用处理数据的逻辑比较困难
由于数据来源多,因此获取数据的逻辑常常分布在代码各处。比如说容器列表,展示它的时候我们需要一段代码来格式化容器列表。但是容器列表之后还会更新,由于更新的逻辑和获取的逻辑不一样,所以就很难再复用之前所使用的格式化代码。
(2) 获取数据的接口形式不统一
如今我们调用 API 时,都会返回一个 Promise。但并不是所有的数据来源都能转换成 Promise,比如 WebSocket 怎么转换成 Promise 呢?结果就是在获取数据的时候,要先调用 API,然后再监听 WebSocket 的事件。或许还要同时再去监听用户的点击事件等等。等于说有多个数据源影响同一个数据,对每一个数据源都要分别写一套对应的逻辑,十分啰嗦。
聪明的读者可能会想到:只要把处理数据的逻辑和获取数据的逻辑解耦不就可以了吗?很好,现在我们有两个问题了。
2. 数据复杂
DCE 数据的复杂主要体现在下面三个方面:
- 从后端获取的数据不能直接展示,要经过一系列复杂逻辑的格式化。
- 其中部分格式化逻辑还包括发送请求。
- 数据之间存在着复杂的依赖关系。所谓依赖关系是指,必须要有 B 数据才能格式化 A 数据。
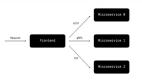
下图是 DCE 数据依赖关系的大体示意图。

以格式化应用列表为例,总共有这么几个步骤。读者不需要完全搞清楚,领会大意即可:
- 获取应用列表的数据
- 获取服务列表的数据。这是因为应用是由服务组成的,应用的状态取决于服务的状态,因此要格式化应用的状态,就必须获取服务列表的数据。
- 获取任务列表的数据。服务列表里其实也不包含服务的状态,服务的状态取决于服务的任务的状态,因此要格式化服务的状态,就必须获取任务列表的数据。
- 格式化任务列表。
- 根据服务的 id 从任务列表中找到服务所对应的任务,然后根据任务的状态,得出服务的状态。
- 格式化 服务列表。
- 根据应用的 id 从服务列表中找到应用所对应的服务,然后根据服务的状态,得出应用的状态。顺便还要把每个应用的服务的数据塞到每个应用里,因为之后还要用到。
- 格式化应用列表。
- 完成!
这其中掺杂了同步和异步的逻辑,非常繁琐,非常难以维护(肺腑之言)。况且,这还只是处理应用列表的逻辑,服务、容器、存储、网络等等列表需要获取呢,并且逻辑也不比应用列表简单。所以说,要想解耦获取和处理数据的逻辑并不容易。因为处理数据这件事本身,就包括了获取数据的逻辑。
如此复杂的依赖关系,经常会发送重复的请求。比如说我之前格式化应用列表的时候请求过服务列表了,下次要获取服务列表的时候又得再请求一次服务列表。
聪明的读者会想:我把数据缓存起来保管到一个地方,每次要格式化数据的时候,不要重新去请求依赖的数据,而是从缓存里读取数据,然后一股脑传给格式化函数,这样不就可以了吗?很好!现在我们有三个问题了!
3. 数据更新困难
缓存是个很好的想法。但是在 DCE 里很难做,DCE 是一个对数据的实时性和一致性要求非常高的应用。
DCE 中几乎所有数据都是会被全局使用到的。比如说应用列表的数据,不仅要在应用列表中显示,侧边栏里也会显示应用的数量,还有很多下拉菜单里面也会出现它。所以如果一处数据更新了,另一处没更新,那就非常尴尬了。
还有就是之前提到的应用和服务的依赖关系。由于应用是依赖服务的,理论上来说服务变了,应用也是要变的,这个时候也要更新应用的缓存数据。但事实上,因为数据的依赖树实在是太深了(比如上图中的应用和主机),有些依赖关系不那么明显,结果就会忘记更新缓存,数据就会不一致。
什么时候要使用缓存、缓存保存在哪里、何时更新缓存,这些是都是非常棘手的问题。
聪明读者又会想:我用 redux 之类的库,弄个全局的状态树,各个组件使用全局的状态,这样不就能保证数据的一致了吗?这个想法很好的,但是会遇到上面两个难点的阻碍。redux 在面对复杂的异步逻辑时就无能为力了。
三、结论
结果我们会发现这三个难点每个单独看起来都有办法可以解决,但是合在一起似乎就成了无解死循环。因此,在经过广泛调研之后,我们选择了 RxJs。
1. 为什么 RxJs 可以解决我们的困难
在说明我们如何用 RxJs 解决上面三个难题之前,首先要说明 RxJs 的特性。毕竟 RxJs 目前还是个比较新的技术,大部分人可能还没有接触过,所以有必要给大家普及一下 RxJs。
(1) 统一了数据来源
RxJs ***的特点就是可以把所有的事件封装成一个 Observable,翻译过来就是可观察对象。只要订阅这个可观察对象,就可以获取到事件源所产生的所有事件。想象一下,所有的 DOM 事件、ajax 请求、WebSocket、数组等等数据,统统可以封装成同一种数据类型。这就意味着,对于有多个来源的数据,我们可以每个数据来源都包装成 Observable,统一给视图层去订阅,这样就抹平了数据源的差异,解决了***个难题。
(2) 强大的异步同步处理能力
RxJs 还提供了功能非常强大且复杂的操作符( Operator) 用来处理、组合 Observable,因此 RxJs 拥有十分强大的异步处理能力,几乎可以满足任何异步逻辑的需求,同步逻辑更不在话下。它也抹平了同步和异步之间的鸿沟,解决了第二个难题。
(3) 数据推送的机制把拉取的操作变成了推送的操作
RxJs 传递数据的方式和传统的方式有很大不同,那就是改“拉取”为“推送”。原本一个组件如果需要请求数据,那它必须主动去发送请求才能获得数据,这称为“拉取”。如果像 WebSocket 那样被动地接受数据,这称为“推送”。如果这个数据只要请求一次,那么采用“拉取”的形式获取数据就没什么问题。但是如果这个数据之后需要更新,那么“拉取”就无能为力了,开发者不得不在代码里再写一段代码来处理更新。
但是 RxJs 则不同。RxJs 的精髓在于推送数据。组件不需要写请求数据和更新数据的两套逻辑,只要订阅一次,就能得到现在和将来的数据。这一点改变了我们写代码的思路。我们在拿数据的时候,不是拿到了数据就万事大吉了,还需要考虑未来的数据何时获取、如何获取。如果不考虑这一点,就很难开发出具备实时性的应用。
如此一来,就能更好地解耦视图层和数据层的逻辑。视图层从此不用再操心任何有关获取数据和更新数据的逻辑,只要从数据层订阅一次就可以获取到所有数据,从而可以只专注于视图层本身的逻辑。
(4) BehaviorSubject 可以缓存数据。
BehaviorSubject 是一种特殊的 Observable。如果 BehaviorSubject 已经产生过一次数据,那么当它再一次被订阅的时候,就可以直接产生上次所缓存的数据。比起使用一个全局变量或属性来缓存数据,BehaviorSubject 的好处在于它本身也是 Observable,所以异步逻辑对于它来说根本不是问题。这样一来第三个难题也解决了。
这样一来三个问题是不是都没有了呢?不,这下其实我们有了四个问题。
2. 我们是怎么用 RxJs 解决困难的
相信读者看到这里肯定是一脸懵逼。这就是第四个问题。RxJs 学习曲线非常陡峭,能参考的资料也很少。我们在开发的时候,甚至都不确定怎么做才是***实践,可以说是摸着石头过河。建议大家阅读下文之前先看一下 RxJs 的文档,不然接下来肯定十脸懵逼。
| RxJs 真是太 TM 难啦!Observable、Subject、Scheduler 都是什么鬼啦!Operator 怎么有这么多啊!每个 Operator 后面只是加个 Map 怎么变化这么大啊!都是 map,为什么这个 map和_.map 还不一样啦!文档还只有英文哒(现在有中文了)!我昨天还在写 jQuery,怎么一下子就要写这么难的东西啊啊啊!!!(划掉)
——来自实习生的吐槽 |
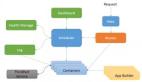
首先,给大家看一个整体的数据层的设计。熟悉单向数据流的读者应该不会觉得太陌生。

- 从 API 获取一些必须的数据
- 由事件分发器来分发事件
- 事件分发器触发控制各个数据管道
- 视图层拼接数据管道,获得用来展示的数据
- 视图层通过事件分发器来更新数据管道
- 形成闭环
可以看到,我们的数据层设计基本上是一个单向数据流,确切地说是“单向数据树”。
树的最上面是树根。树根会从各个 API 获得数据。树根的下面是树干。从树干分岔出一个个树枝。每个树枝的终点都是一个可以供视图层订阅的 BehaviorSubject,每个视图层组件可以按自己的需求来订阅各个数据。数据和数据之间也可以互相订阅。这样一来,当一个数据变化的时候,依赖它的数据也会跟着变化,最终将会反应到视图层上。
四、设计详细说明
1. root(树根)
root 是树根。树根有许多触须,用来吸收养分。我们的 root 也差不多。一个应用总有一些数据是关键的数据,比如说认证信息、许可证信息、用户信息。要使用我们的应用,我们首先得知道你登录没登录,付没付过钱对不对?所以,这一部分数据是***层数据,如果不先获取这些数据,其他的数据便无法获取。而这些数据一旦改变,整个应用其他的数据也会发生根本的变化。比方说,如果登录的用户改变了,整个应用展示的数据肯定也会大变样。
在具体的实现中,root 通过 zip 操作符汇总所有的 api 的数据。为了方便理解,本文中的代码都有所简化,实际场景肯定远比这个复杂。
- // 从各个 API 获取数据
- const license$ = Rx.Observable.fromPromise(getLicense());
- const auth$ = Rx.Observable.fromPromise(getAuth());
- const systemInfo$ = Rx.Observable.fromPromise(getSystemInfo());
- // 通过 zip 拼接三个数据,当三个 API 全部返回时,root$ 将会发出这三个数据
- const root$ = Rx.Observable.zip(license$, auth$, systemInfo$);
当所有必须的的数据都获取到了,就可以进入到树干的部分了。
2. trunk(树干)
trunk 是我们的树干,所有的数据都首先流到 trunk ,trunk 会根据数据的种类,来决定这个数据需要流到哪一个树枝中。简而言之,trunk 是一个事件分发器。所有事件首先都汇总到 trunk 中。然后由 trunk 根据事件的类型,来决定哪些数据需要更新。有点类似于 redux 中根据 action 来触发相应 reducer 的概念。
之所以要有这么一个事件分发器,是因为 DCE 的数据都是牵一发而动全身的,一个事件发生时,往往需要触发多个数据的更新。此时有一个统一的地方来管理事件和数据之间的对应关系就会非常方便。一个统一的事件的入口,可以大大降低未来追踪数据更新过程的难度。
在具体的实现中,trunk 是一个 Subject。因为 trunk 不但要订阅 WebSocket,同时还要允许视图层手动地发布一些事件。当有事件发生时,无论是 WebSocket 事件还是视图层发布的事件,经过 trunk 的处理后,我们都可以一视同仁。
- //一个产生 WebSocket 事件的 Observable
- const socket$ = Observable.webSocket('ws://localhost:8081');
- // trunk 是一个 Subject
- const trunk$ = new Rx.Subject()
- // 在 root 产生数据之前,trunk 不会发布任何值。trunk 之后的所有逻辑也都不会运行。
- .skipUntil(root$)
- // 把 WebSocket 推送过来的事件,合并到 trunk 中
- .merge(socket$)
- .map(event => {
- // 在实际开发过程中,trunk 可能会接受来自各种事件源的事件
- // 这些事件的数据格式可能会大不相同,所以一般在这里还需要一些格式化事件的数据格式的逻辑。
- });
3. branch(树枝)
trunk 的数据最终会流到各个 branch。branch 究竟是什么,下面就会提到。
在具体的实现中,我们在 trunk 的基础上,用操作符对 trunk 所分发的事件进行过滤,从而创建出各个数据的 Observable,就像从树干中分出的树枝一样。
- // trunk 格式化好的事件的数据格式是一个数组,其中是需要更新的数据的名称
- // 这里通过 filter 操作符来过滤事件,给每个数据创建一个 Observable。相当于于从 trunk 分岔出多条树枝。
- // 比如说 trunk 发布了一个 ['app', 'services'] 的事件,那么 apps$ 和 services$ 就能得到通知
- const apps$ = trunk$.filter(events => events.includes('app'));
- const services$ = trunk$.filter(events => events.includes('service'));
- const containers$ = trunk$.filter(events => events.includes('container'));
- const nodes$ = trunk$.filter(events => events.includes('node'));
仅仅如此,我们的 branch 还没有什么实质性的内容,它仅仅能接受到数据更新的通知而已,后面还需要加上具体的获取和处理数据的逻辑,下面就是一个容器列表的 branch 的例子。
- // containers$ 就是从 trunk 分出来的一个 branch。
- // 当 containers$ 收到来自 trunk 的通知的时候,containers$ 后面的逻辑就会开始执行
- containers$
- // 当收到通知后,首先调用 API 获取容器列表
- .switchMap(() => Rx.Observable.fromPromise(containerApi.list()))
- // 获取到容器列表后,对每个容器分别进行格式化。
- // 每个容器都是作为参数传递给格式化函数的。格式化函数中不包含任何异步的逻辑。
- .map(containers => containers.map(container, container => formatContainer(container)));
现在我们就有了一个能够产生容器列表的数据的 containers$。我们只要订阅 containers$就可以获得***的容器列表数据,并且当 trunk 发出更新通知的时候,数据还能够自动更新。这是巨大的进步。
现在还有一个问题,那就是如何处理数据之间的依赖关系呢?比如说,格式化应用列表的时候假如需要格式化好的容器列表和服务列表应该怎么做呢?这个步骤在以前一直都十分麻烦,写出来的代码犹如意大利面。因为这个步骤需要处理不少的异步和同步逻辑,这其中的顺序还不能出错,否则可能就会因为关键数据还没有拿到导致格式化时报错。
实际上,我们可以把 branch 想象成一个“管道”,或者“流”。这两个概念都不是新东西,大家应该比较熟悉。
| We should have some ways of connecting programs like garden hose—screw in another segment when it becomes necessary to massage data in another way.
——Douglas McIlroy |
如果数据是以管道的形式存在的,那么当一个数据需要另一个数据的时候,只要把管道接起来不就可以了吗?幸运的是,借助 RxJs 的 Operator,我们可以非常轻松地拼接数据管道。下面就是一个应用列表拼接容器列表的例子。
- // apps$ 也是从 trunk 分出来的一个 branch
- apps$
- // 同样也从 API 获取数据
- .switchMap(() => Rx.Observable.fromPromise(appApi.list()))
- // 这里使用 combineLatest 操作符来把容器列表和服务列表的数据拼接到应用列表中
- // 当容器或服务的数据更新时,combineLatest 之后的代码也会执行,应用的数据也能得到更新。
- .combineLatest(containers$, services$)
- // 把这三个数据一起作为参数传递给格式化函数。
- // 注意,格式化函数中还是没有任何异步逻辑,因为需要异步获取的数据已经在上面的 combineLatest 操作符中得到了。
- .map(([apps, containers, services]) => apps.map(app => formatApp(app, containers, services)));
4. 格式化函数
格式化函数就是上文中的 formatApp 和 formatContainer。它没有什么特别的,和 RxJs 没什么关系。
唯一值得一提的是,以前我们的格式化函数中充斥着异步逻辑,很难维护。所以在用 RxJs 设计数据层的时候我们刻意地保证了格式化函数中没有任何异步逻辑。即使有的格式化步骤需要异步获取数据,也是在 branch 中通过数据管道的拼接获取,再以参数的形式统一传递给格式化函数。这么做的目的就是为了将异步和同步解耦,毕竟异步的逻辑由 RxJs 处理更加合适,也更便于理解。
5. fruit
现在我们只差缓存没有做了。虽然我们现在只要订阅 apps$ 和 containers$ 就能获取到相应的数据,但是前提是 trunk 必需要发布事件才行。这是因为 trunk 是一个 Subject,假如 trunk 不发布事件,那么所有订阅者都获取不到数据。所以,我们必须要把 branch 吐出来的数据缓存起来。 RxJs 中的 BehaviorSubject 就非常适合承担这个任务。
BehaviorSubject 可以缓存每次产生的数据。当有新的订阅者订阅它时,它就会立刻提供最近一次所产生的数据,这就是我们要的缓存功能。所以对于每个 branch,还需要用 BehaviorSubject 包装一下。数据层最终对外暴露的接口实际上是 BehaviorSubject,视图层所订阅的也是 BehaviorSubject。在我们的设计中,BehaviorSubject 叫作 fruit,这些经过层层格式化的数据,就好像果实一样。
具体的实现并不复杂,下面是一个容器列表的例子。
- // 每个数据流对外暴露的一个借口是 BehaviorSubject,我们在变量末尾用$$,表示这是一个BehaviorSubject
- const containers$$ = new Rx.BehaviorSubject();
- // 用 BehaviorSubject 去订阅 containers$ 这个 branch
- // 这样 BehaviorSubject 就能缓存***的容器列表数据,同时当有新数据的时它也能产生新的数据
- containers$.subscribe(containers$$);
6. 视图层
整个数据层到上面为止就完成了,但是在我们用视图层对接数据层的时候,也走了一些弯路。一般情况下,我们只需要用 vue-rx 所提供的 subscriptions 来订阅 fruit 就可以了。
- <template>
- <app-list :data="apps"></app-list>
- </template>
- <script>
- import app$$ from '../branch/app.branch';
- export default {
- name: 'app',
- subscriptions: {
- apps: app$$,
- },
- };
- </script>
但有些时候,有些页面的数据很复杂,需要进一步处理数据。遇到这种情况,那就要考虑两点。一是这个数据是否在别的页面或组件中也要用,如果是的话,那么就应该考虑把它做进数据层中。如果不是的话,那其实可以考虑在页面中单独再创建一个 Observable,然后用 vue-rx 去订阅这个 Observable。
还有一个问题就是,假如视图层需要更新数据怎么办?之前已经提到过,整个数据层的事件分发是由 trunk 来管理的。因此,视图层如果想要更新数据,也必须取道 trunk。这样一来,数据层和视图层就形成了一个闭环。视图层根本不用担心数据怎么处理,只要向数据层发布一个事件就能全部搞定。
- methods: {
- updateApp(app) {
- appApi.update(app)
- .then(() => {
- trunk$.next(['app'])
- })
- },
- },
下面是整个数据层设计的全貌,供大家参考。

总结
之后的开发过程证明,这一套数据层很大程度上解决了我们的问题。它***的好处在于提高了代码的可维护性,从而使得开发效率大大提高,bug 也大大减少。
【本文是51CTO专栏机构“道客船长”的原创文章,转载请通过微信公众号(daocloudpublic)联系原作者】