日前由安华金和攻防实验室发现并提交的国产数据库漏洞,获国家信息安全漏洞平台CNVD确认,编号CNVD-2017-17486。
CNVD-2017-17486
- 漏洞类型:缓冲区溢出漏洞
- 威胁程度:中危
- 漏洞描述:允许攻击者利用漏洞,通过程序创建表空间文件时,指定路径名过长导致数据库崩溃。
- 漏洞危害:一旦被利用,将可能导致数据库宕机,或被攻击者取得数据库操作系统的用户权限,从而对系统所在的网络发起攻击。
CNVD-2017-17486是一个标准的堆栈溢出漏洞,属于缓冲区溢出漏洞的重要分支,此类漏洞比较常见,影响范围和危害也会比较广泛,如果出现在数据库等基础应用中,导致数据库服务中断,将引发整个业务的瘫痪。
由于此类漏洞的出现范围较广,我们除了及时发现漏洞,更应该通过分析漏洞形成原理、作用机制及可能引发的风险,找到可行的防范手段。
缓冲区溢出有多大危害
缓冲区溢出漏洞是一种古老、危害范围大、常见于c代码中的软件漏洞,在各种操作系统、应用软件中广泛存在,数据库系统中同样常见。利用缓冲区溢出攻击,可以导致程序运行失败、系统宕机、重新启动等后果。更为严重的是,攻击者可以利用它执行非授权指令,甚至取得系统特权,进而实行攻击行为。
缓冲区溢出漏洞最早在20世纪80年代初被发现,第一次重大事件是1988年爆发的Morris蠕虫。该蠕虫病毒利用fingerd的缓冲区溢出漏洞进行攻击,最终导致6000多台机器被感染,造成直接经济损失100万美金。随后,衍生而出的Ramen 蠕虫、sircam蠕虫、sql slammer蠕虫等品种逐渐出现,每一类蠕虫都对整个互联网造成了严重的安全影响,造成高额的经济损失。
堆栈溢出是如何形成的?
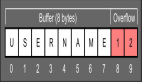
简单来说,堆栈溢出就是把大缓冲区中的数据向小缓冲区中复制,由于没有关注小缓冲区的边界,“撑爆”了较小的缓冲区,从而冲掉了小缓冲区和邻内区域的其他数据而引起的内存问题。在具体描述堆栈溢出之前我们先来了解一下Linux程序在内存中的结构:

其中共享区也称为data区,用来存储可执行代码;.text和.bss均用来存储程序的全局变量和初始化变量;堆则不随函数消亡而消亡,而是直到程序消亡或手动释放才会消亡;堆栈是随着函数分配并消亡的,堆栈溢出就是出现在堆栈区中的缓冲区安全问题。
堆栈是一个后进先出(LIFO)数据结构,往低地址增长,它保存本地变量、函数调用等信息。随着函数调用层数的增加,栈帧会向低地址方向延伸;随着进程中函数调用层数的减少,即各函数的返回,栈帧会一块一块地被遗弃而向内存的高地址方向回缩。各函数的栈帧大小随着函数的性质不同而不等。
堆栈这种数据结构,常见操作有压栈(PUSH)、弹栈(POP);用于标识栈的属性有:栈顶(TOP)、栈底(BASE)。其中:
- PUSH:为栈增加一个元素的操作叫做PUSH,相当于插入一块;
- POP:从栈中取出一个元素的操作叫做POP;
- TOP:TOP标识栈顶的位置,且是动态变化的,每做一次PUSH操作,它会自+1;每做一次POP操作,它会自-1;
- BASE:BASE标识栈底位置,用于防止栈空后继续弹栈,一般来说BASE位置不发生改变。
下面以mian函数叠加A和B函数为例说明整个压栈和弹栈过程:

Main函数调用A函数,把A函数中的变量添加到堆栈区内,开辟大小和变量指定大小相关。同样B函数在被调用后也会把变量添加到堆栈区内,开辟指定大小空间给B区域变量使用。
- 如果其中任意一个变量存入的值超过设计的界定,就会导致值覆盖其他变量的区域最终污染到函数返回地址区域。一旦函数的返回地址被污染,在进行弹栈的过程中会最终把跳转的地址指向黑客所指定的区域,或根本不存在的区域。
- 如果覆盖函数返回地址的是一组随机值,则程序会跳转到未知位置,这种情况往往最终会导致整个程序崩溃。
- 如果黑客构造足够精细的shellcode,把跳转地址指向黑客自己注入的代码,则很可能会利用该漏洞获得当前用户的控制权限。
几个可行的防护建议
堆栈溢出漏洞是c 代码的一种常见安全漏洞。防护的方法可以从多个角度来加强。
1) 使用自动化工具进行扫描检测,排查是否存在缓冲区溢出漏洞;但需要注意的是需要使用面向不同系统的扫描工具,没有一个检查工具可以支持所有基础应用的扫描。
2) 加强相关程序员的代码能力,做好相应的长度限制工作,从代码级别进行防范。
3)避免使用原C库中那些可能存在缓冲区溢出隐患的函数,使用增强后的函数,这样此漏洞出现的几率会相对低一些。
【本文是51CTO专栏作者“安华金和”的原创稿件,转载请联系原作者】