#MySql-两阶段加锁协议 ##前言此篇博客主要是讲述MySql(仅限innodb)的两阶段加锁(2PL)协议,而非两阶段提交(2PC)协议,区别如下:
- 2PL,两阶段加锁协议:主要用于单机事务中的一致性与隔离性。
- 2PC,两阶段提交协议:主要用于分布式事务。
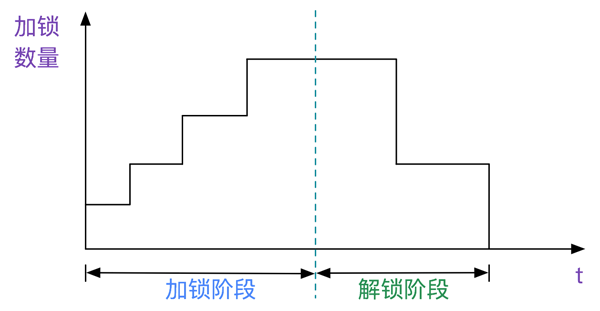
MySql本身针对性能,还有一个MVCC(多版本控制)控制,本文不考虑此种技术,仅仅考虑MySql本身的加锁协议。 ##什么时候会加锁在对记录更新操作或者(select for update、lock in share model)时,会对记录加锁(有共享锁、排它锁、意向锁、gap锁、nextkey锁等等),本文为了简单考虑,不考虑锁的种类。 ##什么是两阶段加锁在一个事务里面,分为加锁(lock)阶段和解锁(unlock)阶段,也即所有的lock操作都在unlock操作之前,如下图所示:
##为什么需要两阶段加锁
引入2PL是为了保证事务的隔离性,即多个事务在并发的情况下等同于串行的执行。 在数学上证明了如下的封锁定理:
如果事务是良构的且是两阶段的,那么任何一个合法的调度都是隔离的。
具体的数学推到过程可以参照<<事务处理:概念与技术>>这本书的7.5.8.2节.
此书乃是关于数据库事务的圣经,无需解释(中文翻译虽然晦涩,也能坚持读下去,强烈推荐)
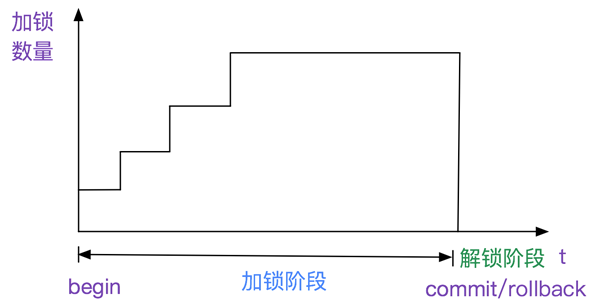
##工程实践中的两阶段加锁-S2PL 在实际情况下,SQL是千变万化、条数不定的,数据库很难在事务中判定什么是加锁阶段,什么是解锁阶段。于是引入了S2PL(Strict-2PL),即:
在事务中只有提交(commit)或者回滚(rollback)时才是解锁阶段,
其余时间为加锁阶段。
如下图所示:
这样的话,在实际的数据库中就很容易实现了。 ##两阶段加锁对性能的影响
上面很好的解释了两阶段加锁,现在我们分析下其对性能的影响。考虑下面两种不同的扣减库存的方案:
方案1:
begin;
// 扣减库存
update t_inventory set count=count-5 where id=${id} and count >= 5;
// 锁住用户账户表
select * from t_user_account where user_id=123 for update;
// 插入订单记录
insert into t_trans;
commit;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
方案2:
begin;
// 锁住用户账户表
select * from t_user_account where user_id=123 for update;
// 插入订单记录
insert into t_trans;
// 扣减库存
update t_inventory set count=count-5 where id=${id} and count >= 5;
commit;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
由于在同一个事务之内,这几条对数据库的操作应该是等价的。但在两阶段加锁下的性能确是有比较大的差距。两者方案的时序如下图所示:
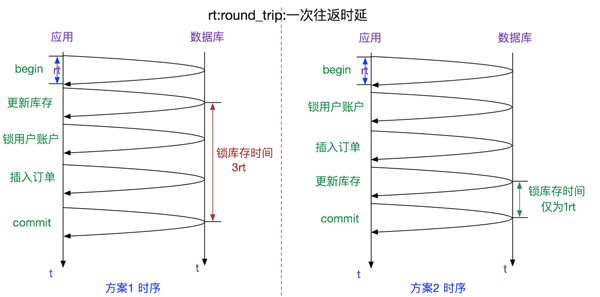
由于库存往往是最重要的热点,是整个系统的瓶颈。那么如果采用第二种方案的话,
tps应该理论上能够提升3rt/rt=3倍。这还仅仅是业务就只有三条SQL的情况下,
多一条sql就多一次rt,就多一倍的时间。
值得注意的是:
在更新到数据库的那个时间点才算锁成功
提交到数据库的时候才算解锁成功
这两个round_trip的前半段是不会计算在内的
如下图所示:
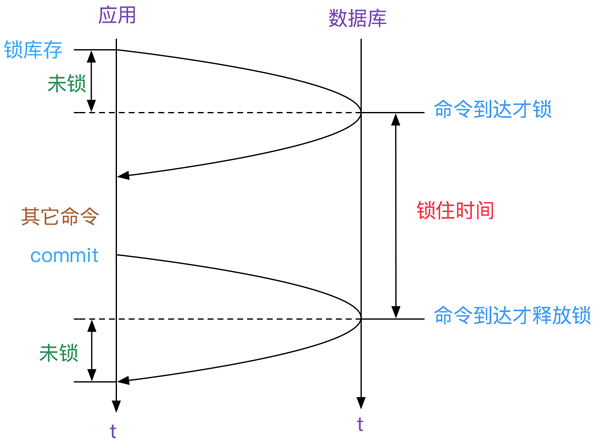
当前只考虑网络时延,不考虑数据库和应用本身的时间消耗。 ##依据S2PL的性能优化
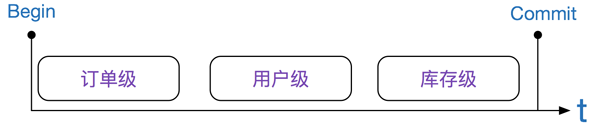
从上面的例子中,可以看出,需要把最热点的记录,
放到事务***,这样可以显著的提高吞吐量。更进一步:
越热点记录离事务的终点越近(无论是commit还是rollback)
笔者认为,先后顺序如下图:
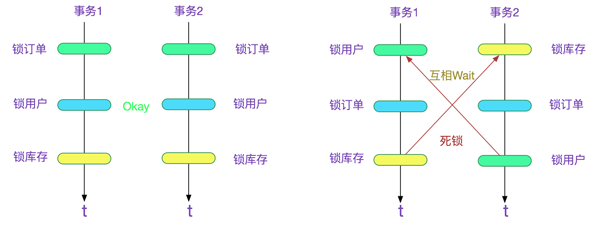
###避免死锁这也是任何SQL加锁不可避免的。上文提到了按照记录Key的热度在事务中倒序排列。那么写代码的时候任何可能并发的SQL都必须按照这种顺序来处理,不然会造成死锁。如下图所示:
###select for update和update where 谓词计算我们可以直接将一些简单的判断逻辑写到update的谓词里面,以减少加锁时间,考虑下面两种方案:
方案1:
begin:
int count = select count from t_inventory for update;
if count >= 5:
update t_inventory set count=count-5 where id =123
commit
else
rollback
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
方案2:
begin:
int rows = update t_inventory set count=count-5 where id =123 and count >=5
if rows > 0:
commit;
ele
rollback;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
时延如下图所示:
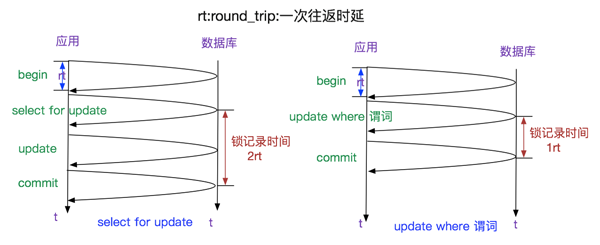
可以看到,通过在update中加谓词计算,少了1rt的时间。
由于update在执行过程中对符合谓词条件的记录加的是和select for update一致的排它锁
(具体的锁类型较为复杂,不在这里描述),所以两者效果一样。
#总结 MySql采用两阶段加锁协议实现隔离性和一致性,我们只有深入的去理解这种协议,才能更好的对我们的SQL进行优化,增加系统的吞吐量。