Nature 子刊 Nature Human Behavior 上***发表了一篇关于人类行为的研究,通过对自然图像中的字母进行无监督学习,探讨了人类是如何获得文字识别能力的。研究人员提出了一个基于深度神经网络的大规模字母识别计算模型,通过将概率生成模型与视觉输入拟合,以完全无监督的方式开发了复杂的内部表征的层次结构。
书写符号的使用是人类文化发展的重大成就。然而,抽象的字母表征是如何在视觉中进行学习的,这仍然是未解决的问题。发表在 Nature.com 上的一篇题为 Letter perception emerges from unsupervised deep learning and recycling of natural image features 的研究报告中,研究人员提出了一个基于深度神经网络的大规模的字母识别计算模型,通过将概率生成模型与视觉输入拟合,以完全无监督的方式开发了更为复杂的内部表征的层次结构。
有这样一个假设,学习书写符号部分地重新使用了用于对象识别的预先存在的神经元回路,模型的早期处理阶段利用了从自然图像中学习的一般领域(domain-general)的视觉特征,而特定领域(domain-specific)的特征则出现在曝光于印刷字母前的上游神经元中。
研究论证,即使对于噪声降级(noise-degraded)的图像,这些高级别表征可以很容易地映射到字母识别,从而产生和人类观察者类似的对于字母认知的广泛实证结果的准确模拟。研究者的模型显示出,通过重用自然的视觉原语(primitives),学习书写符号只需要有限的、特定领域的调整,这支持了字母形状被文化选择以匹配自然环境的统计结构的假设。
图 1a 刻画了研究者提出的模型的整体架构。网络底层接收了作为图像像素 灰度级别激活编码的感知信号。出现在视网膜和丘脑中的低级别视觉处理被一个启发自生物学的 whitening 算法所模拟,捕捉到了图像中的局部空间关系,成为了对比归一化(contrast normalization)的一个步骤。
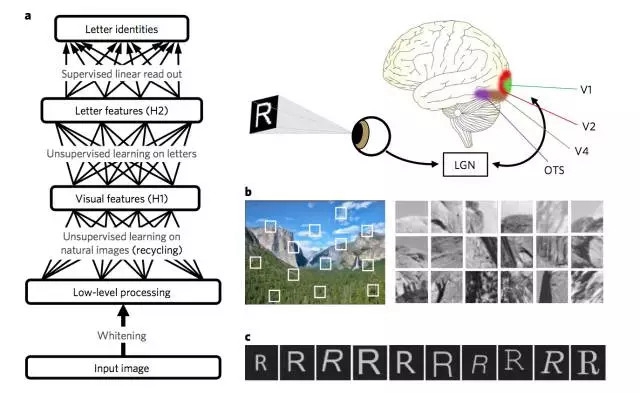
图1 是深度学习架构和自然图像及印刷字母数据样本。
a,深度学习架构。每个框代表了网络中的一层神经元。和 whitening 步骤相应的有方向的箭头引出了前馈的处理过程,而无方向的连接显示了无监督生成学习所利用的双向处理过程。和线性读数层相应的有方向的箭头引出了监督学习。在字母处理过程中涉及到的相应大脑网络显示在右侧(LGN, 背外侧膝状体核; V1, 首要视觉皮层; V2, 二级视觉皮层; V4, 纹状体外视觉皮层;OTS, 颞枕沟);
b,包含多个小 patch (40 × 40 pixels)的自然图像,显示在右侧;c,研究者的数据集中印刷字母的样本,使用多种字体、风格、大小和位置关系创造而成。
研究人员将编码在***个内部层(隐式)神经元的潜在特征集称为H1, H1 模仿了出现在早期大脑皮层视觉(corticalvision ,在 V1 和 V2 中)的处理类型。
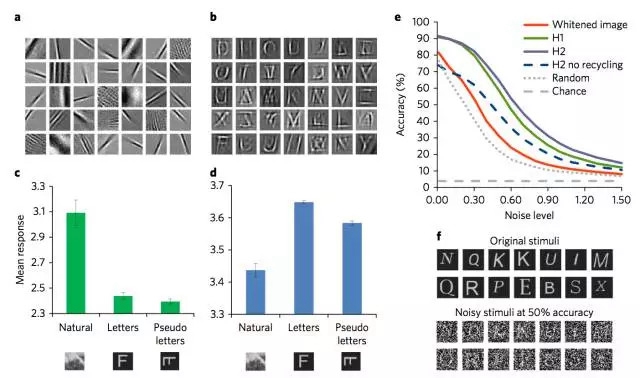
图2 是新出现的神经元感受野(receptive fields)、表征选择和模型中字母识别准确度。
a,在 H1 层中神经元样本的感受野,灰度体现其连接强度(黑色:强,inhibitory connection;白色:强,excitatory connection);
b,H2 层中隐式神经元样本的感受野;
c 和 d,H1 层(c)和H2层(d)中对于不同刺激的平均反馈(activation norm);
e, 作为噪声级别函数(即, 高斯噪声的标准偏差)的不同表征层读数的准确度;f,无噪声刺激样本,及含噪声的对应版本,性能表现约为前者的 50%。
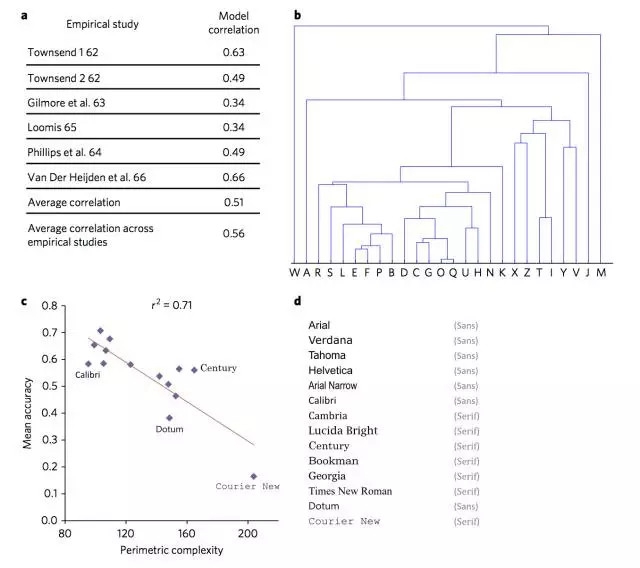
图3 是人类心理物理学研究的模拟。
a,模型混淆矩阵和各种经验混淆矩阵之间的Pearson 相关性(均P <0.001)。注意,所有经验矩阵之间的平均互相关为0.56;b,通过 H2 表征层次聚类得出的树状图,表明在网络的内部表征中保留了字母之间的视觉相似性。连接柱的高度表示欧氏距离(较小的条表示更大的相似度);
c,每个字体的平均perimetric 复杂度与noise-degraded 刺激的相应平均字母识别精度之间的负相关;
d,根据平均字母混淆排列的所有字体列表,从最小混乱(上)到***混乱(底部)。
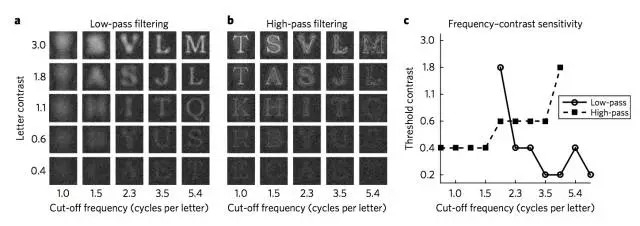
图4 是感知渠道中介字母识别的空间频率分析。
a,b,叠加在高斯噪声(均方根对比度= 0.2)和背景(亮度= 0.2)上的低通(a)和高通(b)滤波字母的样本;
c,根据滤波器类型的H2读数敏感度对比函数,每个字母的频率范围从 0.8 到 6.6(两个轴均为对数)。注意,与对应于低通和高通噪声的曲线相比,对应于低通滤波和高通滤波的曲线相反,因为研究者直接对输入信号而不是调制噪声进行滤波。