如果希望了解机器学习,或者已经决定投身机器学习,你会第一时间找到各种教材进行充电,同时在心中默认:书里讲的是牛人大神的毕生智慧,是正确无误的行动指南,认真学习就能获得快速提升。但实际情况是,你很可能已经在走弯路。
科技发展很快,数据在指数级增长,环境也在指数级改变,因此很多时候教科书会跟不上时代的发展。有时,即便是写教科书的人,也不见得都明白结论背后的“所以然”,因此有些结论就会落后于时代。针对这个问题,第四范式创始人、首席执行官戴文渊近日就在第四范式内部分享上,向大家介绍了机器学习教材中的七个经典问题。本文根据演讲实录整理,略有删减。
有时我们会发现,在实际工作中,应该怎么做和教科书讲的结论相矛盾,这时候要怎么办呢?难道教科书中的结论出错了?事实上,有时确实如此。所以今天我就想和大家分享一下机器学习教材中的一些经典问题,希望对大家今后的工作和学习有所帮助。
神经网络不宜超过三层
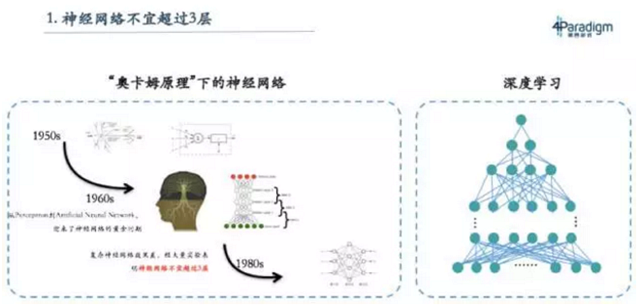
那为什么之前的教科书上会写神经网络不能超过三层,这就要从神经网络的历史说起。五十年代有位科学家叫Marvin Minksy,他是一位生物学家,数学又很好,所以他在研究神经元的时候就在想能不能用数学模型去刻画生物的神经元,因此就设计了感知机。感知机就像一个神经细胞,它能像神经细胞一样连起来,形成神经网络,就像大脑的神经网络。其实在60年代开始的时候,是有很深的神经网络,但当时经过大量实验发现,不超过三层的神经网络效果不错,于是大概到80年代时就得出结论:神经网络不宜超过三层。
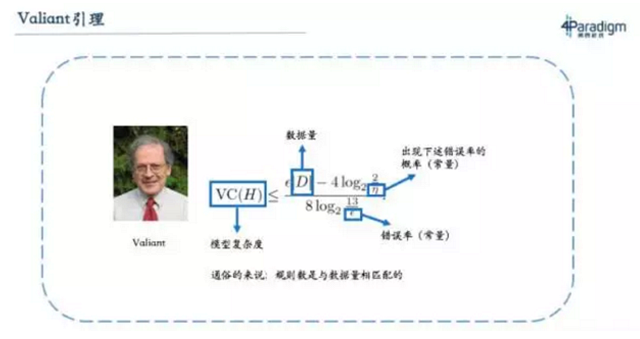
那为什么现在这条结论又被推翻了呢?实际上这条结论是有前提条件的,即在数据量不大的情况下,神经网络不宜超过三层。而从2005年开始,大家发现随着数据增加,深度神经网络的表现良好,所以慢慢走向深度学习。其实这里真正正确的原理是Valiant引理,它可以理解为“模型复杂度(例如专家系统的规则数量)要和数据量成正比”。数据量越大,模型就越复杂。上个世纪因为数据量小,所以神经网络的层数不能太深,现在数据量大,所以神经网络的层数就要做深。这也解释了为什么当时教科书会有这样的结论,而现在随着深度学习的流行,大家已经不再会认为这句话是对的。
决策树不能超过五层
如果有同学看教科书上介绍决策树,会有一个说法就是决策树要减枝,决策树如果不减枝效果不好。还有教科书会告诉决策树不能超过五层,超过五层的决策树效果不好。这个结论和神经网络结论一样,神经网络不能超过三层也是因为当时数据量不大,决策树不能超过五层也是因为上个世纪数据量不够大,二叉树决策树如果深度是N的话,复杂度大概是2的N次方,所以不超过五层复杂度也就是三十多。如果数据量达到一百万的时候,决策树能达到十几二十层的规模,如果数据量到了一百亿的时候决策树可能要到三十几层。
现在,我们强调更深的决策树,这可能和教科书讲的相矛盾。矛盾的原因是现在整个场景下数据量变大,所以要做更深的决策树。当然,我们也不一定在所有的场景里都有很大数据量,如果遇到了数据量小的场景,我们也要知道决策树是要做浅的。最根本来说,就是看有多少数据,能写出多复杂的模型。
特征选择不能超过一千个
有些教科书会单独开个章节来讲特征选择,告诉我们在拿到数据后,要先删除一些不重要的特征,甚至有的教科书注明,特征数不能超过一千,否则模型效果不好。但其实这个结论也是有前提条件的,如果数据量少,是不能够充分支撑很多特征,但如果数据量大,结论就会不一样。这也就是为什么我们做LogisticRegression会有几十亿个特征,而不是限制在几百个特征。
过去传统数据分析软件,如SAS,之所以只有几百个特征,是因为它诞生于上世纪七十年代,它面临的问题是在具体场景下没有太多可用数据,可能只有几百上千个样本。因此,在设计系统时,就只需要针对几百个特征设计,不需要几十亿个特征,因为上千个样本无法支撑几十亿特征。但现在,随着数据量增加,特征量也需要增加。所以我认为,在大数据环境下,整个机器学习教科书里关于特征选择的章节已经落后于时代,需要根据新的形式重新撰写;当然在小数据场景下,它仍然具有价值。
集成学习获得最好学习效果
第四个叫做集成学习,这个技术在各种数据挖掘比赛中特别有用,比如近些年KDD CUP的冠军几乎都是采用集成学习。什么是集成学习?它不是做一个模型,而是做很多(例如一千个)不一样的模型,让每个模型投票,投票的结果就是最终的结果。如果不考虑资源限制情况,这种模式是效果最好的。这也是为什么KDDCUP选手们都选择集成学习的方式,为了追求最后效果,不在乎投入多少,在这种条件下,集成学习就是最好的方式。
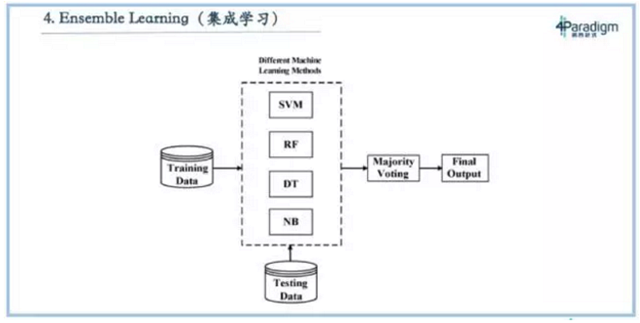
但在现实中,企业做机器学习追求的不是用无限的资源做尽可能好的效果,而是如何充分利用有限资源,获得最好效果。假设企业只有两台机器,如何用这两台机器获得最好的效果呢?如果采用集成学习,用两台机器跑五个模型,就要把两台机器分成五份,每个模型只能用0.4台机器去跑,因此跑的数据量就有限。那如果换种方式,不用集成学习,就用一个模型去跑,就能跑5倍的数据。通常5倍的数据量能比集成学习有更好的效果。在工业界比较少会应用集成学习,主要是因为工业界绝大多数的场景都是资源受限,资源受限时最好的方式是想办法放进去更多的数据。集成学习因为跑更多的模型导致只能放更少的数据,通常这种效果都会变差。
正样本和负样本均采样到1:1
第五个叫做均衡采样,绝大多数的教科书都会讲到。它是指如果我们训练一个模型,正样本和负样本很不平均,比如在正样本和负样本1:100的情况下,就需要对正、负样本做均衡采样,把它变成1:1的比例,这样才是最好的。但其实这个结论不一定对,因为统计学习里最根本的一条原理就是训练场景和测试场景的分布要一样,所以这个结论只在一个场景下成立,那就是使用模型的场景中正、负样本是1:1,那这个结论就是对的。
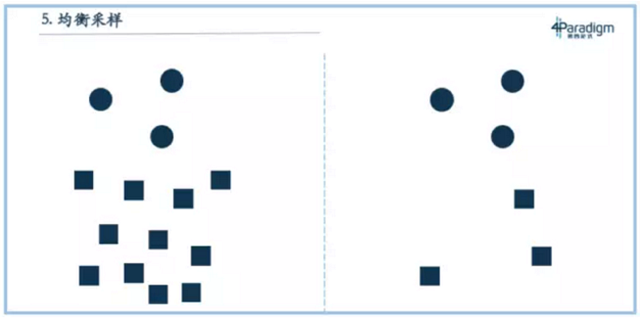
正确的做法是,应用场景是1:100,那训练集合最好也是1:100。均衡采样不一定都是对的,多数情况下不采样反而才是正确的。因为大多时候,我们直接把训练集合和测试集合做随机拆分,或者按照时间拆分,二者的分布就是一致的,那个时候不采样是最好的。当然有时候,我们也会发现做负样本采样会有更好的效果,比如范式在为某股份制银行卡中心做交易反欺诈时,就做了负样本采样,那是因为当我们把所有样本都放进去后,发现计算资源不够,所以只能做采样。正样本与负样本大概是1:1000或者1:10000,如果对正样本做采样,损失信息量会比较大,所以我们选择对负样本采样,比如做1:1000的采样,再把负样本以1000的加权加回去。在资源受限时这么做,会尽可能降低信息量的损失。但如果仅仅是为了把它做均衡而做负样本采样,通常是不对的。和前面几个问题不同,负样本采样并不是因环境改变而结论变化,事实上就不应该做负样本采样。
交叉验证是最好的测试方法
下一个问题叫做交叉验证,是指假设要将一份数据拆分成训练集和测试集,这个时候怎么评估出它的误差?交叉验证是把集合拆成五份,取四份做训练集、一份做测试集,并且每次选择不同的那一份做测试级,最后测出五个结果再做平均,这被认为是最好的测试方法。
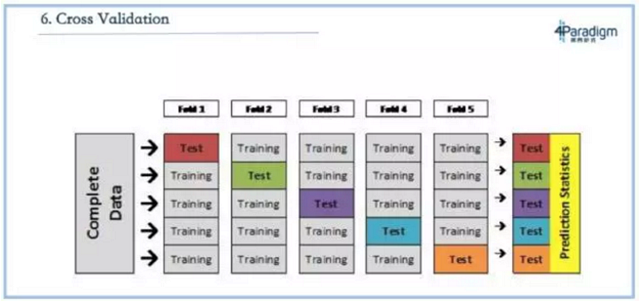
交叉验证确实是一个还不错的验证的方法,但在现实应用场景下,它往往不是最合适的一种方式。因为通常来说,我们用机器学习做的事情是预测,绝大多数情况下我们是用现在或者过去的数据做一个模型来预测未来。而拿过去的训练预测未来的最好测试方法不是交叉验证,因为交叉验证是按照交易或者按人拆分的。最合适的是方法其实是按照时间拆分,比如评估的时候选取一个时间点,用在这个时间点之前的数据做训练,预测在这个时间点之后的,这是最接近真实应用场景的评估结果。
交叉验证可能只适用于和时间属性不相关的场景,比如人脸识别,但我们面临更多的应用场景,无论是风险、营销或者反欺诈,都是在用过去的数据训练后预测未来,最合适这样场景的评估方法不是交叉验证,而是按照时间去拆分。
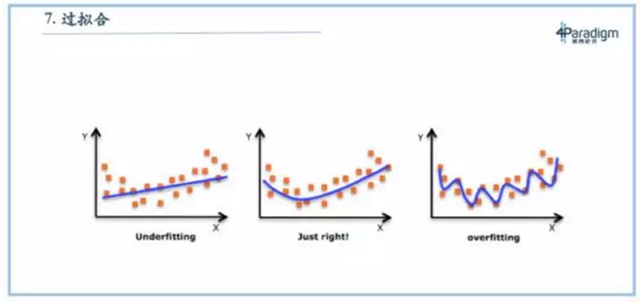
过拟合一定不好
最后一个叫过拟合,这也是一个讨论特别多的话题。以前,通常我们会说如果模型做的太复杂了就会过拟合,如PPT右边所示,而最好的方式应该是图中中间的状态——拟合的刚刚好,图中左边的模型underfitting,没有训练完全。但现在来看,大多数的实际场景都是在拿过去预测未来,过拟合不一定是不好的,还是要看具体场景。如果这个场景是过去见过的情况比较多,新的情况比较少的时候,过拟合反倒是好的。
打个比方,如果期末考试题就是平时的作业,那我们把平时的作业都背一遍就是最好的方式,而这就是过拟合。如果期末考试不考平时作业,全是新题,那么这个时候就不能只背平时的作业,还要充分理解这门课的知识,掌握如何推理解题的技巧。所以过拟合好坏与否,完全取决于场景。如果应用场景依靠死记硬背就能搞定,那过拟合反倒是好的。实际上在我们的设计里面,很多时候我们会倾向于往过拟合靠一点,可能做新题会差一点,但是对于死记硬背的送分题会做的非常好。在拿过去预测未来的应用场景下,有的时候过拟合不一定不好,要根据实际情况来看。
今天与大家分享了教科书中的几个经典问题。其实在实际工业应用中,我们不会完全按照教科书中的方式去实践。我们也会设计很深的模型、很深的决策树、很多的特征、会过拟合一点,我们更强调按时间拆分,不强调均衡采样。面对教科书中的结论,我们需要学会的是根据实际场景做出相应灵活判断。