读了将近一个下午的TensorFlow Recurrent Neural Network教程,翻看其在PTB上的实现,感觉晦涩难懂,因此参考了部分代码,自己写了一个简化版的Language Model,思路借鉴了Keras的LSTM text generation。
代码地址:Github
转载请注明出处:Gaussic
语言模型
Language Model,即语言模型,其主要思想是,在知道前一部分的词的情况下,推断出下一个最有可能出现的词。例如,知道了 The fat cat sat on the,我们认为下一个词为mat的可能性比hat要大,因为猫更有可能坐在毯子上,而不是帽子上。
这可能被你认为是常识,但是在自然语言处理中,这个任务是可以用概率统计模型来描述的。就拿The fat cat sat on the mat来说。我们可能统计出第一个词The出现的概率p(The)p(The),The后面是fat的条件概率为p(fat|The)p(fat|The),The fat同时出现的联合概率:
p(The,fat)=p(The)⋅p(fat|The)p(The,fat)=p(The)·p(fat|The)
- 1.
p(The,fat,cat)=p(The)⋅p(fat|The)⋅p(cat|The,fat)p(The,fat,cat)=p(The)·p(fat|The)·p(cat|The,fat)
- 1.
p(cat|The,fat)=p(The,fat,cat)p(The,fat)p(cat|The,fat)=p(The,fat,cat)p(The,fat)
- 1.
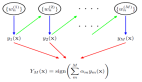
p(S)=p(w1,w2,⋅⋅⋅,wn)=p(w1)⋅p(w2|w1)⋅p(w3|w1,w2)⋅⋅⋅p(wn|w1,w2,w3,⋅⋅⋅,wn−1)p(S)=p(w1,w2,···,wn)=p(w1)·p(w2|w1)·p(w3|w1,w2)···p(wn|w1,w2,w3,···,wn−1)
- 1.
p(S)=p(w1,w2,⋅⋅⋅,wn)=p(w1)⋅p(w2|w1)⋅p(w3|w2)⋅p(w4|w3)⋅⋅⋅p(wn|wn−1)p(S)=p(w1,w2,···,wn)=p(w1)·p(w2|w1)·p(w3|w2)·p(w4|w3)···p(wn|wn−1)
- 1.
p(S)=p(w1,w2,⋅⋅⋅,wn)=p(w1)⋅p(w2|w1)⋅p(w3|w1,w2)⋅p(w4|w2,w3)⋅⋅⋅p(wn|wn−2,wn−1)p(S)=p(w1,w2,···,wn)=p(w1)·p(w2|w1)·p(w3|w1,w2)·p(w4|w2,w3)···p(wn|wn−2,wn−1)
- 1.
这样的条件概率虽然好求,但是会丢失大量的前面的词的信息,有时会对结果产生不良影响。因此如何选择一个有效的n,使得既能简化计算,又能保留大部分的上下文信息。
以上均是传统语言模型的描述。如果不太深究细节,我们的任务就是,知道前面n个词,来计算下一个词出现的概率。并且使用语言模型来生成新的文本。
在本文中,我们更加关注的是,如何使用RNN来推测下一个词。
$ wget http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
$ tar xvf simple-examples.tgz
- 1.
- 2.
we 're talking about years ago before anyone heard of asbestos having any questionable properties
there is no asbestos in our products now
neither <unk> nor the researchers who studied the workers were aware of any research on smokers of the kent cigarettes
we have no useful information on whether users are at risk said james a. <unk> of boston 's <unk> cancer institute
the total of N deaths from malignant <unk> lung cancer and <unk> was far higher than expected the researchers said
- 1.
- 2.
- 3.
- 4.
- 5.
def _read_words(filename):
with open(filename, 'r', encoding='utf-8') as f:
return f.read().replace('\n', '<eos>').split()
- 1.
- 2.
- 3.
f = _read_words('simple-examples/data/ptb.train.txt')
print(f[:20])
- 1.
- 2.
['aer', 'banknote', 'berlitz', 'calloway', 'centrust', 'cluett', 'fromstein', 'gitano', 'guterman', 'hydro-quebec', 'ipo', 'kia', 'memotec', 'mlx', 'nahb', 'punts', 'rake', 'regatta', 'rubens', 'sim']
- 1.
def _build_vocab(filename):
data = _read_words(filename)
counter = Counter(data)
count_pairs = sorted(counter.items(), key=lambda x: -x[1])
words, _ = list(zip(*count_pairs))
word_to_id = dict(zip(words, range(len(words))))
return words, word_to_id
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
words, words_to_id = _build_vocab('simple-examples/data/ptb.train.txt')
print(words[:10])
print(list(map(lambda x: words_to_id[x], words[:10])))
- 1.
- 2.
- 3.
('the', '<unk>', '<eos>', 'N', 'of', 'to', 'a', 'in', 'and', "'s")
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- 1.
- 2.
def _file_to_word_ids(filename, word_to_id):
data = _read_words(filename)
return [word_to_id[x] for x in data if x in word_to_id]
- 1.
- 2.
- 3.
words_in_file = _file_to_word_ids('simple-examples/data/ptb.train.txt', words_to_id)
print(words_in_file[:20])
- 1.
- 2.
[9980, 9988, 9981, 9989, 9970, 9998, 9971, 9979, 9992, 9997, 9982, 9972, 9993, 9991, 9978, 9983, 9974, 9986, 9999, 9990]
- 1.
def to_words(sentence, words):
return list(map(lambda x: words[x], sentence))
- 1.
- 2.
def ptb_raw_data(data_path=None):
train_path = os.path.join(data_path, 'ptb.train.txt')
valid_path = os.path.join(data_path, 'ptb.valid.txt')
test_path = os.path.join(data_path, 'ptb.test.txt')
words, word_to_id = _build_vocab(train_path)
train_data = _file_to_word_ids(train_path, word_to_id)
valid_data = _file_to_word_ids(valid_path, word_to_id)
test_data = _file_to_word_ids(test_path, word_to_id)
return train_data, valid_data, test_data, words, word_to_id
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
def ptb_producer(raw_data, batch_size=64, num_steps=20, stride=1):
data_len = len(raw_data)
sentences = []
next_words = []
for i in range(0, data_len - num_steps, stride):
sentences.append(raw_data[i:(i + num_steps)])
next_words.append(raw_data[i + num_steps])
sentences = np.array(sentences)
next_words = np.array(next_words)
batch_len = len(sentences) // batch_size
x = np.reshape(sentences[:(batch_len * batch_size)], \
[batch_len, batch_size, -1])
y = np.reshape(next_words[:(batch_len * batch_size)], \
[batch_len, batch_size])
return x, y
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- raw_data: 即ptb_raw_data()函数产生的数据
- batch_size: 神经网络使用随机梯度下降,数据按多个批次输出,此为每个批次的数据量
- num_steps: 每个句子的长度,相当于之前描述的n的大小,这在循环神经网络中又称为时序的长度。
- stride: 取数据的步长,决定数据量的大小。
代码解析:
这个函数将一个原始数据list转换为多个批次的数据,即[batch_len, batch_size, num_steps]。
首先,程序每一次取了num_steps个词作为一个句子,即x,以这num_steps个词后面的一个词作为它的下一个预测,即为y。这样,我们首先把原始数据整理成了batch_len * batch_size个x和y的表示,类似于已知x求y的分类问题。
为了满足随机梯度下降的需要,我们还需要把数据整理成一个个小的批次,每次喂一个批次的数据给TensorFlow来更新权重,这样,数据就整理为[batch_len, batch_size, num_steps]的格式。
打印部分数据:
train_data, valid_data, test_data, words, word_to_id = ptb_raw_data('simple-examples/data')
x_train, y_train = ptb_producer(train_data)
print(x_train.shape)
print(y_train.shape)
- 1.
- 2.
- 3.
- 4.
(14524, 64, 20)
(14524, 64)
- 1.
- 2.
print(' '.join(to_words(x_train[100, 3], words)))
- 1.
despite steady sales growth <eos> magna recently cut its quarterly dividend in half and the company 's class a shares
- 1.
print(words[np.argmax(y_train[100, 3])])
- 1.
the
- 1.
class LMConfig(object):
"""language model 配置项"""
batch_size = 64 # 每一批数据的大小
num_steps = 20 # 每一个句子的长度
stride = 3 # 取数据时的步长
embedding_dim = 64 # 词向量维度
hidden_dim = 128 # RNN隐藏层维度
num_layers = 2 # RNN层数
learning_rate = 0.05 # 学习率
dropout = 0.2 # 每一层后的丢弃概率
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
class PTBInput(object):
"""按批次读取数据"""
def __init__(self, config, data):
self.batch_size = config.batch_size
self.num_steps = config.num_steps
self.vocab_size = config.vocab_size # 词汇表大小
self.input_data, self.targets = ptb_producer(data,
self.batch_size, self.num_steps)
self.batch_len = self.input_data.shape[0] # 总批次
self.cur_batch = 0 # 当前批次
def next_batch(self):
"""读取下一批次"""
x = self.input_data[self.cur_batch]
y = self.targets[self.cur_batch]
# 转换为one-hot编码
y_ = np.zeros((y.shape[0], self.vocab_size), dtype=np.bool)
for i in range(y.shape[0]):
y_[i][y[i]] = 1
# 如果到最后一个批次,则回到最开头
self.cur_batch = (self.cur_batch +1) % self.batch_len
return x, y_
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
class PTBModel(object):
def __init__(self, config, is_training=True):
self.num_steps = config.num_steps
self.vocab_size = config.vocab_size
self.embedding_dim = config.embedding_dim
self.hidden_dim = config.hidden_dim
self.num_layers = config.num_layers
self.rnn_model = config.rnn_model
self.learning_rate = config.learning_rate
self.dropout = config.dropout
self.placeholders() # 输入占位符
self.rnn() # rnn 模型构建
self.cost() # 代价函数
self.optimize() # 优化器
self.error() # 错误率
def placeholders(self):
"""输入数据的占位符"""
self._inputs = tf.placeholder(tf.int32, [None, self.num_steps])
self._targets = tf.placeholder(tf.int32, [None, self.vocab_size])
def input_embedding(self):
"""将输入转换为词向量表示"""
with tf.device("/cpu:0"):
embedding = tf.get_variable(
"embedding", [self.vocab_size,
self.embedding_dim], dtype=tf.float32)
_inputs = tf.nn.embedding_lookup(embedding, self._inputs)
return _inputs
def rnn(self):
"""rnn模型构建"""
def lstm_cell(): # 基本的lstm cell
return tf.contrib.rnn.BasicLSTMCell(self.hidden_dim,
state_is_tuple=True)
def gru_cell(): # gru cell,速度更快
return tf.contrib.rnn.GRUCell(self.hidden_dim)
def dropout_cell(): # 在每个cell后添加dropout
if (self.rnn_model == 'lstm'):
cell = lstm_cell()
else:
cell = gru_cell()
return tf.contrib.rnn.DropoutWrapper(cell,
output_keep_prob=self.dropout)
cells = [dropout_cell() for _ in range(self.num_layers)]
cell = tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True) # 多层rnn
_inputs = self.input_embedding()
_outputs, _ = tf.nn.dynamic_rnn(cell=cell,
inputs=_inputs, dtype=tf.float32)
# _outputs的shape为 [batch_size, num_steps, hidden_dim]
last = _outputs[:, -1, :] # 只需要最后一个输出
# dense 和 softmax 用于分类,以找出各词的概率
logits = tf.layers.dense(inputs=last, units=self.vocab_size)
prediction = tf.nn.softmax(logits)
self._logits = logits
self._pred = prediction
def cost(self):
"""计算交叉熵代价函数"""
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(
logits=self._logits, labels=self._targets)
cost = tf.reduce_mean(cross_entropy)
self.cost = cost
def optimize(self):
"""使用adam优化器"""
optimizer = tf.train.AdamOptimizer(learning_rate=self.learning_rate)
self.optim = optimizer.minimize(self.cost)
def error(self):
"""计算错误率"""
mistakes = tf.not_equal(
tf.argmax(self._targets, 1), tf.argmax(self._pred, 1))
self.errors = tf.reduce_mean(tf.cast(mistakes, tf.float32))
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
def run_epoch(num_epochs=10):
config = LMConfig() # 载入配置项
# 载入源数据,这里只需要训练集
train_data, _, _, words, word_to_id = \
ptb_raw_data('simple-examples/data')
config.vocab_size = len(words)
# 数据分批
input_train = PTBInput(config, train_data)
batch_len = input_train.batch_len
# 构建模型
model = PTBModel(config)
# 创建session,初始化变量
sess = tf.Session()
sess.run(tf.global_variables_initializer())
print('Start training...')
for epoch in range(num_epochs): # 迭代轮次
for i in range(batch_len): # 经过多少个batch
x_batch, y_batch = input_train.next_batch()
# 取一个批次的数据,运行优化
feed_dict = {model._inputs: x_batch, model._targets: y_batch}
sess.run(model.optim, feed_dict=feed_dict)
# 每500个batch,输出一次中间结果
if i % 500 == 0:
cost = sess.run(model.cost, feed_dict=feed_dict)
msg = "Epoch: {0:>3}, batch: {1:>6}, Loss: {2:>6.3}"
print(msg.format(epoch + 1, i + 1, cost))
# 输出部分预测结果
pred = sess.run(model._pred, feed_dict=feed_dict)
word_ids = sess.run(tf.argmax(pred, 1))
print('Predicted:', ' '.join(words[w] for w in word_ids))
true_ids = np.argmax(y_batch, 1)
print('True:', ' '.join(words[w] for w in true_ids))
print('Finish training...')
sess.close()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
需要经过多次的训练才能得到一个较为合理的结果。