












1. 血案由来
近期我在为Lazada卖家中心做一个自助注册的项目,其中的shop name校验规则较为复杂,要求:
1. 英文字母大小写
2. 数字
3. 越南文
4. 一些特殊字符,如“&”,“-”,“_”等
看到这个要求的时候,自然而然地想到了正则表达式。于是就有了下面的表达式(写的比较龊):
- ^([A-Za-z0-9._()&'\- ]|
- [aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
在测试环境,这个表达式从功能上符合业务方的要求,就被发布到了马来西亚的线上环境。结果上线之后,发现线上机器时有发生CPU飙到100%的情况,导致整个站点响应异常缓慢。通过dump线程trace,才发现线程全部卡在了这个正则表达式的校验上:
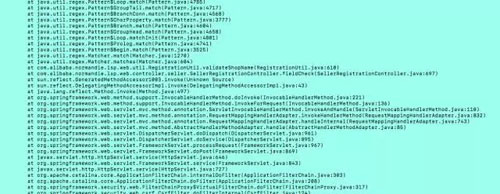
一开始难以置信,一个正则表达式的匹配过程怎么可能引发CPU飚高呢?抱着怀疑的态度去查了资料才发现小小的正则表达式里面竟然大有文章,平时写起来都是浅尝辄止,只要能够满足功能需求,就认为达到目的了,完全忽略了它可能带来的性能隐患。
引发这次血案的就是所谓的正则“回溯陷阱(Catastrophic Backtracking)”。下面详细介绍下这个问题,以避免重蹈覆辙。
2. 正则表达式引擎
说起回溯陷阱,要先从正则表达式的引擎说起。正则引擎主要可以分为基本不同的两大类:一种是DFA(确定型有穷自动机),另一种是NFA(不确定型有穷自动机)。简单来讲,NFA 对应的是正则表达式主导的匹配,而 DFA 对应的是文本主导的匹配。
DFA从匹配文本入手,从左到右,每个字符不会匹配两次,它的时间复杂度是多项式的,所以通常情况下,它的速度更快,但支持的特性很少,不支持捕获组、各种引用等等;而NFA则是从正则表达式入手,不断读入字符,尝试是否匹配当前正则,不匹配则吐出字符重新尝试,通常它的速度比较慢,最优时间复杂度为多项式的,最差情况为指数级的。但NFA支持更多的特性,因而绝大多数编程场景下(包括java,js),我们面对的是NFA。以下面的表达式和文本为例,
- text = ‘after tonight’
- regex = ‘to(nite|nighta|night)’
在NFA匹配时候,是根据正则表达式来匹配文本的,从t开始匹配a,失败,继续,直到文本里面的第一个t,接着比较o和e,失败,正则回退到 t,继续,直到文本里面的第二个t,然后 o和文本里面的o也匹配,继续,正则表达式后面有三个可选条件,依次匹配,第一个失败,接着二、三,直到匹配。
而在DFA匹配时候,采用的是用文本来匹配正则表达式的方式,从a开始匹配t,直到第一个t跟正则的t匹配,但e跟o匹配失败,继续,直到文本里面的第二个 t 匹配正则的t,接着o与o匹配,n的时候发现正则里面有三个可选匹配,开始并行匹配,直到文本中的g使得第一个可选条件不匹配,继续,直到最后匹配。
可以看到,DFA匹配过程中文本中的字符每一个只比较了一次,没有吐出的操作,应该是快于NFA的。另外,不管正则表达式怎么写,对于DFA而言,文本的匹配过程是一致的,都是对文本的字符依次从左到右进行匹配,所以,DFA在匹配过程中是跟正则表达式无关的,而 NFA 对于不同但效果相同的正则表达式,匹配过程是完全不同的。
3. 回溯
说完了引擎,我们再来看看到底什么是回溯。对于下面这个表达式,相信大家很清楚它的意图,
- ab{1,3}c
也就是说中间的b需要匹配1~3次。那么对于文本“abbbc”,按照第1部分NFA引擎的匹配规则,其实是没有发生回溯的,在表达式中的a匹配完成之后,b恰好和文本中的3个b完整匹配,之后是c发生匹配,一气呵成。如果我们把文本换成“abc”呢?无非就是少了一个字母b,却发生了所谓的回溯。匹配过程如下图所示(橙色为匹配,黄色为不匹配),
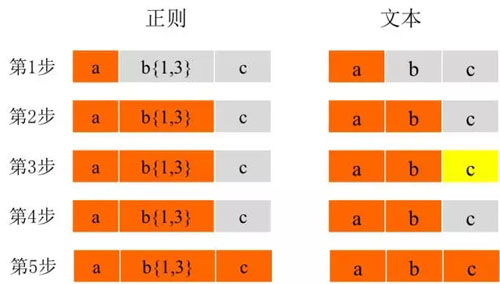
1~2步应该都好理解,但是为什么在第3步开始,虽然已经文本中已经有一个b匹配了b{1,3},后面还会拉着字母c跟b{1,3}做比较呢?这个就是我们下面将要提到的正则的贪婪特性,也就是说b{1,3}会竭尽所能的匹配最多的字符。在这个地方我们先知道它一直要匹配到撞上南墙为止。 在这种情况下,第3步发生不匹配之后,整个匹配流程并没有走完,而是像栈一样,将字符c吐出来,然后去用正则表达式中的c去和文本中的c进行匹配。这样就发生了一次回溯。
4. 贪婪、懒惰与独占
我们再来看一下究竟什么是贪婪模式。
下面的几个特殊字符相信大家都知道它们的用法:
i. ?: 告诉引擎匹配前导字符0次或一次。事实上是表示前导字符是可选的。
ii. +: 告诉引擎匹配前导字符1次或多次。
iii. *: 告诉引擎匹配前导字符0次或多次。
iv. {min, max}: 告诉引擎匹配前导字符min次到max次。min和max都是非负整数。如果有逗号而max被省略了,则表示max没有限制;如果逗号和max都被省略了,则表示重复min次。
默认情况下,这个几个特殊字符都是贪婪的,也就是说,它会根据前导字符去匹配尽可能多的内容。这也就解释了为什么在第3部分的例子中,第3步以后的事情会发生了。
在以上字符后加上一个问号(?)则可以开启懒惰模式,在该模式下,正则引擎尽可能少的重复匹配字符,匹配成功之后它会继续匹配剩余的字符串。在上例中,如果将正则换为
- ab{1,3}?c
则匹配过程变成了下面这样(橙色为匹配,黄色为不匹配),
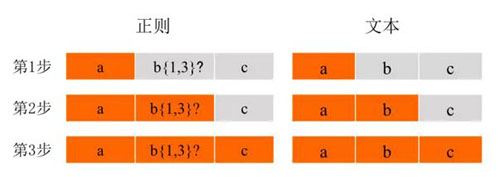
由此可见,在非贪婪模式下,第2步正则中的b{1,3}?与文本b匹配之后,接着去用c与文本中的c进行匹配,而未发生回溯。
如果在以上四种表达式后加上一个加号(+),则会开启独占模式。同贪婪模式一样,独占模式一样会匹配最长。不过在独占模式下,正则表达式尽可能长地去匹配字符串,一旦匹配不成功就会结束匹配而不会回溯。我们以下面的表达式为例,
- ab{1,3}+bc
如果我们用文本"abbc"去匹配上面的表达式,匹配的过程如下图所示(橙色为匹配,黄色为不匹配),

可以发现,在第2和第3步,b{1,3}+会将文本中的2个字母b都匹配上,结果文本中只剩下一个字母c。那么在第4步时,正则中的b和文本中的c进行匹配,当无法匹配时,并不进行回溯,这时候整个文本就无法和正则表达式发生匹配。如果将正则表达式中的加号(+)去掉,那么这个文本整体就是匹配的了。
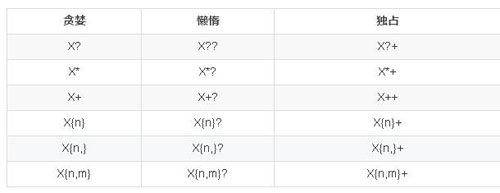
把以上三种模式的表达式列出如下,
5. 总结
现在再回过头看看文章开头的那个很长的正则表达式,其实简化之后,就是一个形如
^[允许字符集]+
的表达式。该字符集大小约为250,而+号表示至少出现一次。按照上面说到的NFA引擎贪婪模式,在用户输入一个过长字符串进行匹配时,一旦发生回溯,计算量将是巨大的。后来采用了独占模式,CPU 100%的问题也得到了解决。
因此,在自己写正则表达式的时候,一定不能大意,在实现功能的情况下,还要仔细考虑是否会带来性能隐患。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】



















