












在分布式系统中,经常需要利用健康检查机制来检查服务的可用性,防止其他服务调用时出现异常。
对于容器而言,最简单的健康检查是进程级的健康检查,即检验进程是否存活。Docker Daemon会自动监控容器中的PID1进程,如果docker run命令中指明了restart policy,可以根据策略自动重启已结束的容器。在很多实际场景下,仅使用进程级健康检查机制还远远不够。比如,容器进程虽然依旧运行却由于应用死锁无法继续响应用户请求,这样的问题是无法通过进程监控发现的。
在Kubernetes提供了Liveness与Readness探针分别对Container及其服务健康状态进行检查。阿里云容器服务也提供了类似的服务健康检查机制。
Docker 原生健康检查能力
而自 1.12 版本之后,Docker 引入了原生的健康检查实现,可以在Dockerfile中声明应用自身的健康检测配置。HEALTHCHECK 指令声明了健康检测命令,用这个命令来判断容器主进程的服务状态是否正常,从而比较真实的反应容器实际状态。
HEALTHCHECK 指令格式:
- HEALTHCHECK [选项] CMD <命令>:设置检查容器健康状况的命令
- HEALTHCHECK NONE:如果基础镜像有健康检查指令,使用这行可以屏蔽掉
注:在Dockerfile中 HEALTHCHECK 只可以出现一次,如果写了多个,只有最后一个生效。
使用包含 HEALTHCHECK 指令的dockerfile构建出来的镜像,在实例化Docker容器的时候,就具备了健康状态检查的功能。启动容器后会自动进行健康检查。
HEALTHCHECK 支持下列选项:
- interval=<间隔>:两次健康检查的间隔,默认为 30 秒;
- timeout=<间隔>:健康检查命令运行超时时间,如果超过这个时间,本次健康检查就被视为失败,默认 30 秒;
- retries=<次数>:当连续失败指定次数后,则将容器状态视为 unhealthy,默认 3 次。
- start-period=<间隔>: 应用的启动的初始化时间,在启动过程中的健康检查失效不会计入,默认 0 秒; (从17.05)引入
在 HEALTHCHECK [选项] CMD 后面的命令,格式和 ENTRYPOINT 一样,分为 shell 格式,和 exec 格式。命令的返回值决定了该次健康检查的成功与否:
- 0:成功;
- 1:失败;
- 2:保留值,不要使用
容器启动之后,初始状态会为 starting (启动中)。Docker Engine会等待 interval 时间,开始执行健康检查命令,并周期性执行。如果单次检查返回值非0或者运行需要比指定 timeout 时间还长,则本次检查被认为失败。如果健康检查连续失败超过了 retries 重试次数,状态就会变为 unhealthy (不健康)。
注:
- 一旦有一次健康检查成功,Docker会将容器置回 healthy (健康)状态
- 当容器的健康状态发生变化时,Docker Engine会发出一个 health_status 事件。
假设我们有个镜像是个最简单的 Web 服务,我们希望增加健康检查来判断其 Web 服务是否在正常工作,我们可以用 curl来帮助判断,其 Dockerfile 的 HEALTHCHECK 可以这么写:
- FROM elasticsearch:5.5
- HEALTHCHECK --interval=5s --timeout=2s --retries=12 \
- CMD curl --silent --fail localhost:9200/_cluster/health || exit 1
- docker build -t test/elasticsearch:5.5 .
- docker run --rm -d \
- --name=elasticsearch \
- test/elasticsearch:5.5
我们可以通过 docker ps,来发现过了几秒之后,Elasticsearch容器从 starting 状态进入了 healthy 状态
- $ docker ps
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
- c9a6e68d4a7f test/elasticsearch:5.5 "/docker-entrypoin..." 2 seconds ago Up 2 seconds (health: starting) 9200/tcp, 9300/tcp elasticsearch
- $ docker ps
- CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
- c9a6e68d4a7f test/elasticsearch:5.5 "/docker-entrypoin..." 14 seconds ago Up 13 seconds (healthy) 9200/tcp, 9300/tcp elasticsearch
另外一种方法是在 docker run 命令中,直接指明healthcheck相关策略。
- $ docker run --rm -d \
- --name=elasticsearch \
- --health-cmd="curl --silent --fail localhost:9200/_cluster/health || exit 1" \
- --health-interval=5s \
- --health-retries=12 \
- --health-timeout=2s \
- elasticsearch:5.5
为了帮助排障,健康检查命令的输出(包括 stdout 以及 stderr)都会被存储于健康状态里,可以用 docker inspect 来查看。我们可以通过如下命令,来获取过去5个容器的健康检查结果
- docker inspect --format='{{json .State.Health}}' elasticsearch
或
- docker inspect elasticsearch | jq ".[].State.Health"
示例结果如下
- {
- "Status": "healthy",
- "FailingStreak": 0,
- "Log": [
- {
- "Start": "2017-08-19T09:12:53.393598805Z",
- "End": "2017-08-19T09:12:53.452931792Z",
- "ExitCode": 0,
- "Output": "..."
- },
- ...
- }
由于应用的开发者会更加了解应用的SLA,一般建议在Dockerfile中声明相应的健康检查策略,这样可以方便镜像的使用。对于应用的部署和运维人员,可以通过命令行参数和REST API针对部署场景对健康检查策略按需进行调整。
注:
- 阿里云容器服务同时支持Docker原生健康检测机制和阿里云的扩展检查机制
- 目前Kubernetes还不提供对Docker原生健康检查机制的支持。
Docker Swarm mode中的服务健康检查能力
在Docker 1.13之后,在Docker Swarm mode中提供了对健康检查策略的支持
可以在 docker service create 命令中指明健康检查策略
- $ docker service create -d \
- --name=elasticsearch \
- --health-cmd="curl --silent --fail localhost:9200/_cluster/health || exit 1" \
- --health-interval=5s \
- --health-retries=12 \
- --health-timeout=2s \
- elasticsearch
在Swarm模式下,Swarm manager会监控服务task的健康状态,如果容器进入 unhealthy 状态,它会停止容器并且重新启动一个新容器来取代它。这个过程中会自动更新服务的 load balancer (routing mesh) 后端或者 DNS记录,可以保障服务的可用性。
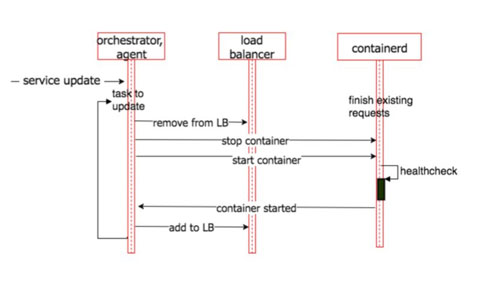
在1.13版本之后,在服务更新阶段也增加了对健康检查的支持,这样在新容器完全启动成功并进入健康状态之前,load balancer/DNS解析不会将请求发送给它。这样可以保证应用在更新过程中请求不会中断。
下面是在服务更新过程的时序图
总结
在企业生产环境中,合理的健康检查设置可以保证应用的可用性。现在很多应用框架已经内置了监控检查能力,比如Spring Boot Actuator。配合Docker内置的健康检测机制,可以非常简洁实现应用可用性监控,自动故障处理,和零宕机更新。























